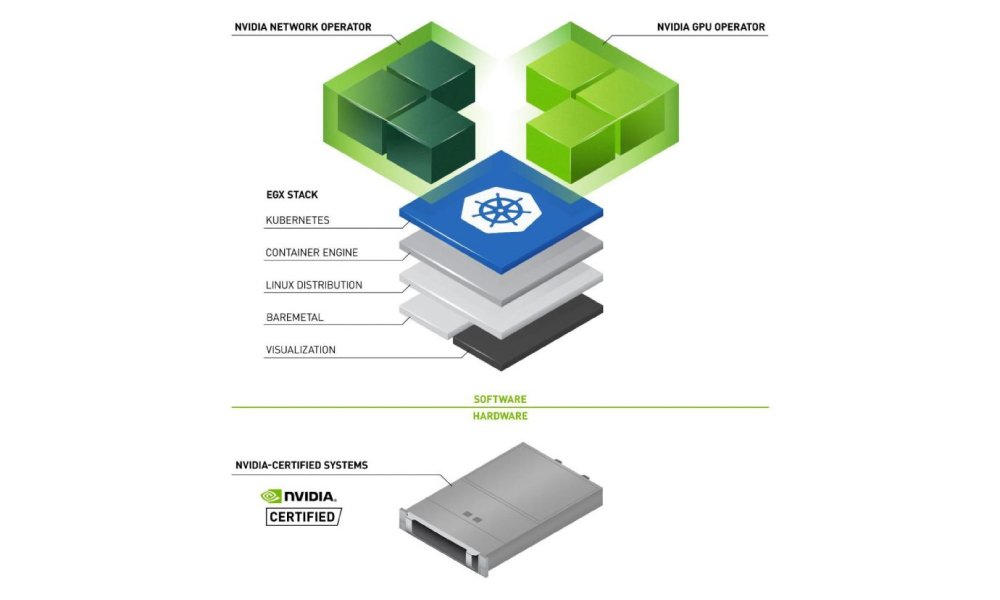
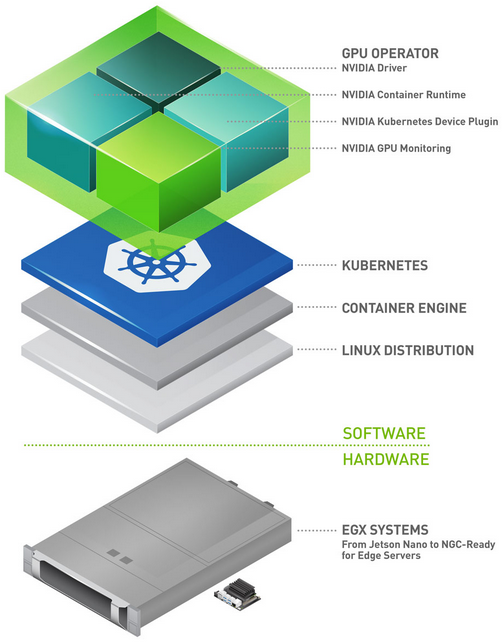
Slurm is an open source cluster management and job scheduling system for Linux. It manages job scheduling for over 65% of TOP500 systems. Most organizations running large-scale AI training have years of investment in Slurm job scripts, fair-share policies, and accounting workflows. The challenge is getting Slurm scheduling capabilities onto Kubernetes—the standard platform for managing GPU infrastructure at scale—without maintaining two separate environments.
Slinky, an open source project developed by SchedMD (now part of NVIDIA), takes two approaches to this integration:
- slurm-bridge brings Slurm scheduling to native Kubernetes workloads, allowing Slurm to act as a Kubernetes scheduler for pods
- slurm-operator runs full Slurm clusters on Kubernetes infrastructure, managing the complete lifecycle of Slurm daemons as pods
This post focuses on the slurm-operator, which is how NVIDIA runs Slurm on Kubernetes for large-scale GPU training clusters. It walks through the architecture of the operator and how it maps Slurm daemons to Kubernetes primitives, then covers deployment—including how Slinky slurm-operator integrates with your existing infrastructure. It also covers the Kubernetes ecosystem integrations that make this model practical. Finally, we share lessons from running Slinky in production at NVIDIA on clusters with over 1,000 GPU worker nodes and 8,000+ GPUs.
How does Slinky slurm-operator work?
Slinky slurm-operator represents each Slurm component (slurmctld for scheduling, slurmdbd for accounting, slurmd for compute workers, slurmrestd for API access) as a Kubernetes Custom Resource Definition (CRD). A Slurm cluster is defined using Custom Resources, and Slinky creates containerized Slurm daemons running in their own pods, configured to belong to their respective cluster.

Slinky ensures high availability (HA) of the Slurm control plane (slurmctld) through pod regeneration, with no need for the Slurm native HA mechanism. Configuration changes propagate automatically: Kubernetes synchronizes mounted configuration (ConfigMaps and Secrets) into the control plane pod, which detects the changes and propagates the new configuration to its workers (slurmd) with zero scheduler downtime.
Using Slurm native OpenMetrics support and Prometheus monitoring (since Slurm v25.11), workers can be autoscaled through the HorizontalPodAutoscaler (HPA) based on cluster metrics and your desired scaling policy, from a single pod to every available worker node. On scale-in, Slinky fully drains Slurm nodes before terminating pods, ensuring running workloads complete first. Slinky prioritizes pods whose workloads will complete soonest for scale-in. The same drain-before-terminate process applies when rolling out new worker pod images (updated Slurm versions or OS patches, for example), so upgrades do not interrupt running jobs.
How to deploy Slinky slurm-operator
Slurm clusters deployed with Slinky on Kubernetes work similarly to noncontainerized Slurm deployments. Slinky slurm-operator automatically enables the Slurm features required for containerized operation:
- configless mode for config distribution without shared filesystems
- dynamic nodes so workers register on startup without being predefined in
slurm.conf - auth/slurm with use_client_ids for cluster-wide user authentication without per-node identity services

Slinky works with your existing database and identity infrastructure. Slurm accounting (slurmdbd) connects to any MySQL- or MariaDB-compatible database, whether running within the cluster or as an external managed service. Identity management for login pods works through SSSD, so Active Directory, LDAP, or any other supported backend integrates without changes. Slurm 25.11 allows slurmd to enforce resource isolation (cgroups v2) within its container. This means mult-user concurrent workloads on the same worker are fully isolated.
Slinky provides reference container images and Docker files for each Slurm component. You can use these directly, extend them with your own libraries and dependencies, or build entirely custom images as long as they include a functioning Slurm installation.
What is the benefit of running Slurm on Kubernetes?
The operational payoff of running Slurm on Kubernetes comes from the ecosystem. Rather than building and maintaining separate toolchains for GPU management, monitoring, networking, and node lifecycle, you can use the Kubernetes tooling that already exists for these problems. Platform teams manage clusters with declarative YAML, Helm deployments, rolling updates, and Prometheus or Grafana for observability.
Automate GPU management with the NVIDIA GPU Operator
The NVIDIA GPU Operator automates GPU driver installation, container runtime configuration, and device plugin deployment, giving worker pods automatic access to GPUs.
The NVIDIA GPU Operator also deploys DCGM Exporter, a GPU telemetry collector. With Slinky DCGM integration and HPC job mapping support, you can enable per-job GPU metrics labeled with Slurm job IDs, giving you workload-level GPU monitoring across your cluster.
To enable this, add the following to the NVIDIA GPU Operator Helm values:
dcgmExporter:
hpcJobMapping:
enabled: true
directory: /var/lib/dcgm-exporter/job-mapping
Worker pods mount the same directory, allowing Slurm prolog/epilog scripts (which run at job start and completion) to write job mapping files that DCGM Exporter picks up automatically.
Multinode NVIDIA NVLink with ComputeDomains
For GPU architectures like NVIDIA GB200 NVL72, where GPUs communicate across nodes through multinode NVIDIA NVLink, Slinky enables access to ComputeDomains. This is a Kubernetes abstraction provided by the NVIDIA DRA driver that dynamically manages Internode Memory Exchange (IMEX) domains for high-bandwidth GPU-to-GPU connectivity.
In NVIDIA deployments, Slinky uses a cluster-wide ComputeDomain (numNodes: 0) that automatically adds and removes nodes from the IMEX domain as they join or leave the cluster. This provides:
- Block topology awareness: Slinky integrates with Topograph, which automatically discovers the GPU block topology of your cluster using Dynamic Resource Allocation (DRA) and labels published by the NVIDIA GPU Operator.
- IMEX plugin: Slurm is configured with
SwitchType = switch/nvidia_imexto use NVIDIA IMEX for cross-node GPU communication. - Topology-aware scheduling: Slurm 25.11 supports
TopologyParam=BlockAsNodeRankwithTopologyPlugin=topology/block, ensuring allocations are sorted so applications can discover segments by node rank.
Distributed training jobs achieve full NVLink bandwidth across node boundaries while ComputeDomains automatically create and tear down IMEX domains as workloads run to completion.
Bidirectional state synchronization
Slinky synchronizes state between Kubernetes and Slurm in both directions. Slurm node states (Idle, Allocated, Mixed, Down, Drain, Completing, Not Responding) are reflected as pod conditions, giving operators visibility into Slurm state through standard Kubernetes tooling.
When you take a node out for maintenance using kubectl drain, the drain state and reason automatically sync to Slurm. Pods running active workloads are protected by PodDisruptionBudgets, so jobs in progress are not accidentally evicted.
Slinky slurm-operator at scale
NVIDIA runs Slinky slurm-operator in production across multiple clusters, with some deployments scaling to over 8,000 GPUs. These clusters run large-scale LLM training and multinode inference workloads daily. GPU communication benchmarks (NCCL all-reduce and all-gather) match the performance of noncontainerized Slurm deployments, with no measurable impact from the Kubernetes layer Slinky runs on. New clusters go from zero to running jobs in hours using Helm charts and declarative config, with no manual provisioning. At this scale, the operational benefits of running Slurm on Kubernetes compound with:
- Unified monitoring: Prometheus scrapes Slurm metrics (jobs, nodes, partitions, scheduler latency) alongside standard Kubernetes metrics, with Grafana dashboards showing both in a single view. No separate monitoring stack for HPC.
- Automated remediation: When health checks flag a node as unhealthy, the state syncs from Kubernetes to Slurm automatically, with the same reason visible in both systems. Slurm drains the node, jobs reschedule to healthy hardware, and teams no longer need to coordinate between K8s and Slurm tooling separately.
- Nondisruptive rolling updates: Updating hundreds of worker pod images used to require downtime. With
PodDisruptionBudgetsprotecting running jobs, we now roll out Slurm version updates and OS patches while training jobs continue uninterrupted on the remaining capacity. - Maintenance coordination: Standard Kubernetes node drain syncs to Slurm. Jobs complete gracefully, maintenance proceeds, and bringing the node back online restores it to the Slurm cluster automatically.
- Familiar tooling: Platform teams use kubectl for day-to-day operations. Pod conditions expose Slurm states (Idle, Allocated, Drain) without needing Slurm CLI access, which means on-call engineers can triage Slurm issues with the same tools they use for everything else.
One constraint to be aware of: Slinky’s slurm-operator currently assumes one worker pod per node. If your workloads are exclusively single-node Slurm jobs, this over-provisions relative to what you need, and a lighter-weight integration (or slurm-bridge) may be a better fit. The Slinky deployment model pays off in multinode job scheduling.
Slinky slurm-operator v1.1.0 release highlights
The recently released slurm-operator v1.1.0 addresses several gaps that matter for production deployments:
- Dynamic topology support: Prior to v1.1.0, Slurm topology awareness required static configuration. In v1.1.0, dynamic nodes will register with their topology based on the Kubernetes node the worker pod runs on, which means topology-aware scheduling works correctly as pods move across the cluster.
- DaemonSet-style worker pod scaling: Prior to v1.1.0, worker pods scaled through replica count. DaemonSet-style scaling ties pods to their
nodeSelectorinstead, making Slurm-to-Kubernetes node mapping statically 1:1. This simplifies operations for clusters where every GPU node should always run a Slurm worker. - Unregistered worker pod remediation: Worker pods that are healthy but not registered to their Slurm cluster are automatically recreated, closing a gap in self-healing behavior.
In the longer term, the team is working on graceful Slurm cluster upgrades, planned outage workflows, configuration rollback, and structured daemon logging. The goal is to make the Slinky operational model match what platform teams expect from any production Kubernetes workload: declarative, self-healing, and observable.
Get started with the Slinky slurm-operator
Slinky is open source and available today. Install the slurm-operator through Helm, define your Slurm cluster as a Custom Resource, and you can have jobs running on Kubernetes in under an hour. The slurm-operator Quick Start Guide walks you through the full setup.
Kubernetes is the right infrastructure substrate for GPU computing, and Slurm is an extremely powerful job scheduling layer for the workloads running on top of it. Slinky makes that combination work seamlessly in production. We plan to continue investing in making it simple to run large-scale AI training infrastructure. If you have questions or want to share what you’re building, visit SlinkyProject on GitHub.