
Recurrent drafting (referred to as ReDrafter) is a novel speculative decoding technique developed and open-sourced by Apple for large language model (LLM) inference now available with NVIDIA TensorRT-LLM. ReDrafter helps developers significantly boost LLM workload performance on NVIDIA GPUs. NVIDIA TensorRT-LLM is a library for optimizing LLM inference. It provides an easy-to-use Python API to define LLMs and build NVIDIA TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. Optimizations include custom attention kernels, inflight batching, paged KV caching, quantization (FP8, INT4 AWQ, INT8 SmoothQuant), and much more.
Speculative decoding is a technique that accelerates LLM inference by generating multiple tokens in parallel. It uses smaller “draft” modules to predict future tokens, which are then verified by the main model. This method maintains output quality while significantly reducing response times, especially during low traffic periods, by better utilizing available resources for low-latency inference.
ReDrafter employs recurrent neural network (RNN)-based sampling, referred to as drafting, combined with tree-style attention previously used in other techniques like Medusa to predict and verify draft tokens from multiple possible paths for better accuracy and to potentially accept more than one token in each iteration of the decoder. NVIDIA collaborated with Apple to add support for this technique in TensorRT-LLM, making it accessible to the broader developer community.
The integration of ReDrafter into TensorRT-LLM expanded its reach, unlocked new optimization potential, and improved on previous methods such as Medusa. For Medusa, the path acceptance and token sampling happens in the TensorRT-LLM runtime, introducing some overhead inside the engine for processing all possible future paths without knowing the accepted path, most of which are ultimately discarded. To reduce such overhead, ReDrafter requires the token validation and acceptance of the best path before drafting future tokens for the next iteration.
TensorRT-LLM has been updated to incorporate drafting and validation logic inside a single engine, rather than relying on the runtime or separate engines to further minimize overhead. This approach provides TensorRT-LLM kernel selection and scheduling more freedom to optimize the network for maximum performance.
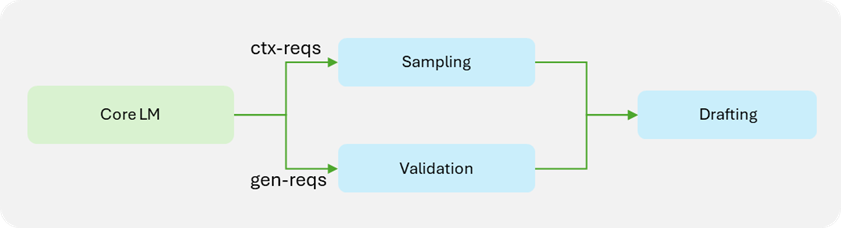
To better illustrate ReDrafter improvements, Figure 1 highlights the key differences between its implementation and that of Medusa in TensorRT-LLM. Most of the components related to speculative decoding have been done in-engine for ReDrafter. This significantly simplifies the runtime changes needed for ReDrafter.


Figure 1. Comparison of Medusa (left) and ReDrafter (right) implementations in NVIDIA TensorRT-LLM
The following sections delve into some of the changes that help enable ReDrafter in TensorRT-LLM.
Inflight-batching compatible engine
Inflight-batching (IFB) is a strategy that significantly improves the throughput by batching context-phase and generation-phase requests. Speculative decoding, coupled with IFB, introduces more complexity to the pipeline as context-phase requests need to be handled differently than generation-phase requests, which require draft token validation. Since ReDrafter moves the validation logic inside the model definition, the engine needs that logic as well during validation. Similar to the attention plugin, the batch is split into two smaller batches: one for context requests and another for generation requests. Each smaller batch then enters its computational workflow, and at the end they are combined back to a single batch for drafting.
Note that this approach requires that all operators on either path support empty tensors, which could happen if a batch consists of all context requests or all generation requests. This capability adds flexibility to TensorRT-LLM APIs, enabling the definition of more complicated models in the future.
Implementing in-engine validation and drafting
To validate and draft inside the engine, TensorRT-LLM is updated with support for numerous new operations so that PyTorch code can be easily translated into a definition of the TensorRT-LLM model.
The following PyTorch code excerpt is Apple’s PyTorch implementation of ReDrafter. The TensorRT-LLM implementation is almost a straightforward line-by-line mapping of the PyTorch version.
PyTorch
def unpack(
packed_tensor: torch.Tensor,
unpacker: torch.Tensor,
) -> torch.Tensor:
assert len(packed_tensor.shape) == 3
last_dim_size = packed_tensor.shape[2]
batch_size, beam_width, beam_length = unpacker.shape
unpacked_data_indices = unpacker.view(
batch_size, beam_width * beam_length, 1).expand(
-1, -1, last_dim_size
)
unpacked_tensor = torch.gather(
packed_tensor, 1, unpacked_data_indices).reshape(
batch_size, beam_width, beam_length, -1
)
return unpacked_tensor
TensorRT-LLM
def _unpack_beams(
x: Tensor,
indices: Tensor,
num_beams: int,
beam_length: int
) -> Tensor:
assert x.rank() == 3
d0 = shape(x, 0, INT_DTYPE_STR)
dl = shape(x, -1, INT_DTYPE_STR)
indices = view(
indices, [-1, num_beams * beam_length, 1], False)
res_shape = concat([d0, num_beams, beam_length, dl])
res = view(gather_nd(x, indices), res_shape, False)
return res
This, of course, is a very simple example. For a more complex example, see the beam search implementation. With the new functionalities added for ReDrafter, it might be possible to improve the Medusa implementation in TensorRT-LLM to further increase its performance.
ReDrafter performance in TensorRT-LLM
As benchmarked by Apple, ReDrafter with TensorRT-LLM can provide up to 2.7x throughput improvements on NVIDIA H100 GPUs with TP8 over the base LLM.
Note that the performance improvement of any speculative decoding technique can be heavily impacted by many factors, including:
- GPU utilization: Speculative decoding is commonly used for low-traffic scenarios, where GPU resources are typically underutilized due to small batch sizes.
- Average acceptance rate: The latency of each decoding step is increased since speculative decoding must perform extra computation, where a significant portion of it is ultimately wasted after validation. As a result, to see any performance benefits from speculative decoding, the average acceptance rate must be high enough to pay for that extra latency. This is affected by the number of beams, their lengths, and the quality of the beam search itself (which is impacted by the training data).
- Task: It is easier to predict future tokens for some tasks (code completion, for example), which leads to a higher acceptance rate, and thus improved performance.
Summary
This collaboration between NVIDIA and Apple, has made TensorRT-LLM more powerful and more flexible, enabling the LLM community to innovate more sophisticated models and easily deploy them with TensorRT-LLM to achieve unparalleled performance on NVIDIA GPUs. These new features open exciting possibilities, and we eagerly anticipate the next generation of advanced models from the community that leverage TensorRT-LLM capabilities, driving further improvements in LLM workloads.
Explore NVIDIA TensorRT-LLM to unlock the full potential of your models on NVIDIA GPUs.
