
Telecom wireless network design demands streamlined processes and standardized approaches. Network architects, engineers, and IT professionals are challenged with manually retrieving and customizing Topology and Orchestration Specification for Cloud Applications (TOSCA) templates to meet firm industry specifications. This leads to reduced productivity and increases the risk of human errors and inconsistencies in network design.
To address this issue, Infosys built an automated tool to generate standard TOSCA templates based on user-provided requirements. The solution, powered by generative AI and deployed using NVIDIA NIM, enables a uniform standard TOSCA template generation process to streamline workflows and enhance productivity. This frees network service designers, as well as OSS solution architects and directors, to design carrier-grade networks faster.
Harnessing generative AI for network design template generation
Infosys used generative AI to develop a standard utility capable of generating service design templates based on network engineer prompts. The tool improves the user experience for customizing TOSCA templates for network service designs, using the following process:
- User-intuitive design: Provide simplified parameter edits and responses from Llama 3-70B, delivered as an NVIDIA NIM microservice, ensuring ease of use for all stakeholders using React with easy file conversion options.
- Integration of pretrained and fine-tuned LLMs: Generate YAML templates dynamically based on user inputs through an integration of a pretrained LLM (Llama 3-70B), NVIDIA NeMo Retriever embedding microservice (NV-Embed-QA-Mistral-7B), and a fine-tuned version of Mistral-7B (mistralai/Mistral-7B-v0.1).
- Input collection: Specify network configuration parameters, including service requirements and network topology preferences.
- Template generation: Process user inputs in real-time to generate customized YAML templates tailored to specific TOSCA design requirements.
- Display and export: Generate YAML templates to present for user review with options to export the finalized template for further network design and orchestration.
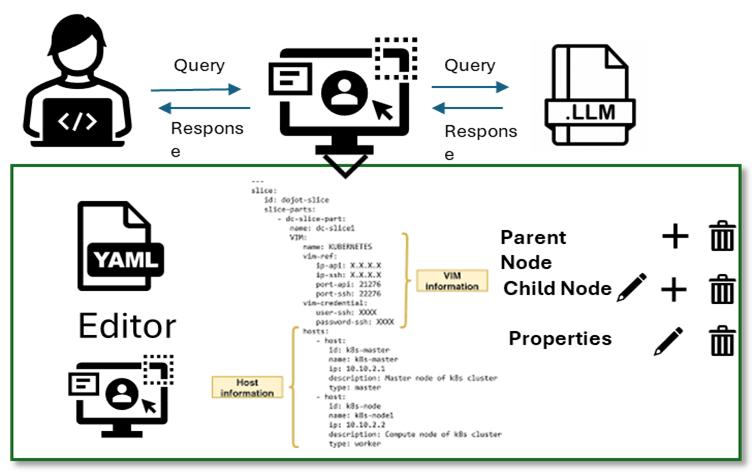
Data collection and preparation for RAG
Acquiring user guide network builder manuals, training documentation, and troubleshooting guides for cloud services helped them generate accurate, contextual network design responses to user queries.
Infosys created a dedicated chat interface, which integrated collected artifacts with user queries. The customizable interface featured drag-and-drop functionalities and easy conversions into the YAML file structure. This produced vector embeddings to populate the vector database used in retrieval augmented generation (RAG).
Technical challenges
By using NVIDIA GPUs, Infosys generated vector embeddings more quickly to prevent delays and frustration for network service designers and OSS solution architects.
Building the AI workflow with NVIDIA NIM and NVIDIA NeMo
The solution used self-hosted NVIDIA NIM and NVIDIA NeMo microservices to deploy fine-tuned foundational LLMs. They exposed OpenAI-like API endpoints that enabled a uniform solution for their client application, which uses the LangChain ChatOpenAI client.
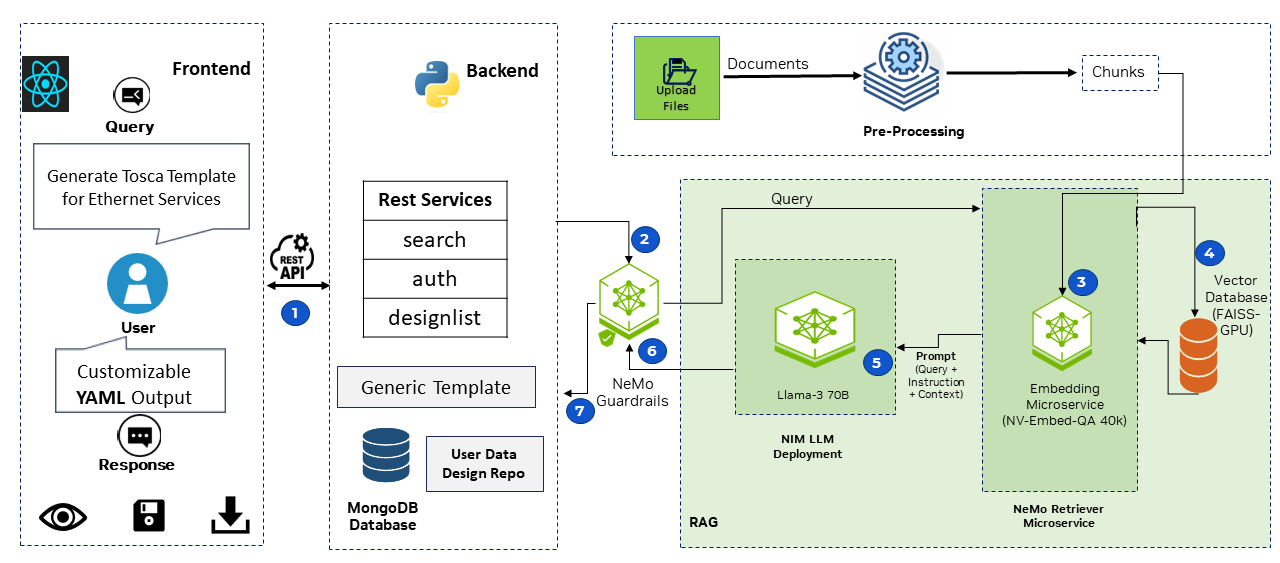
The solution architecture included the following requirements:
- User interface: Using React to create a customized chat interface, tailored to an enterprise’s workflow and advanced query scripting options.
- Data configuration management: Store preloaded network builder manuals in the vector database, to ensure easy access and efficient retrieval, with common templates ingested into the system alongside embedded documents for access by LLMs.
- Vector database options: Use FAISS to ensure flexibility, efficiency, and consistent responsiveness in data handling. By using FAISS, the system can provide rapid and reliable access to stored information, optimizing performance for user needs.
- Backend services and integration: Create robust backend services for user management and configuration, including a RESTful API for integration with external systems to ensure secure authentication and authorization.
- Integration with NVIDIA NIM: Enhance generative AI learning and inferencing capabilities with the NVIDIA NeMo reranking microservice (nv-rerank-qa_v1) to improve RAG inference efficiency.
- Configuration:
- Nine NVIDIA A100 80-GB Tensor Core GPUs (8 used for NIM, 1 used for NeMo Retriever microservices)
- 88 CPU cores
- 1 TB system memory
- AI guardrails: Use NVIDIA NeMo Guardrails to add programmable guardrails to LLM-based conversational applications and protect users from model hallucinations and toxicity.
Evaluating LLM performance results
Infosys tested the following combinations using and excluding NVIDIA NIM for comparison.
| NIM OFF | NIM ON | |||||
| Combo 1 | Combo 2 | Combo 3 | Combo 4 | Combo 5 | ||
| Framework | LangChain | LangChain | LangChain | Llama-index | Langchain | |
| Chunk Size, Chunk Overlap | 1500,100 | 1500,100 | 1500,100 | 2000,200 | 2000,200 | |
| Embedding Model | e5-small-v2 | all-minilm-l6-v2 | Hugging Face/allminiML | Hugging Face/allminiML | NV-Embed-QA-Mistral-7B | |
| TRT-LLM | No | No | Yes | Yes | Yes | |
| Triton | No | No | Yes | Yes | Yes | |
| Vector DB | Faiss-CPU | Faiss-CPU | Faiss-GPU | Faiss-GPU | Faiss-GPU | |
| LLM | Azure GPT-3.5 | Azure GPT-4 | NIM LLM (Mistral-7B) | NIM LLM (LLama-3 70B) | NIM LLM (Llama-3 70B) | |
| Accuracy | 70% | 83% | 65% | 83% | 85% | |
| Latency (sec) | 3.5 | 2.5 | 3.5 | 3 | 2.5 | |
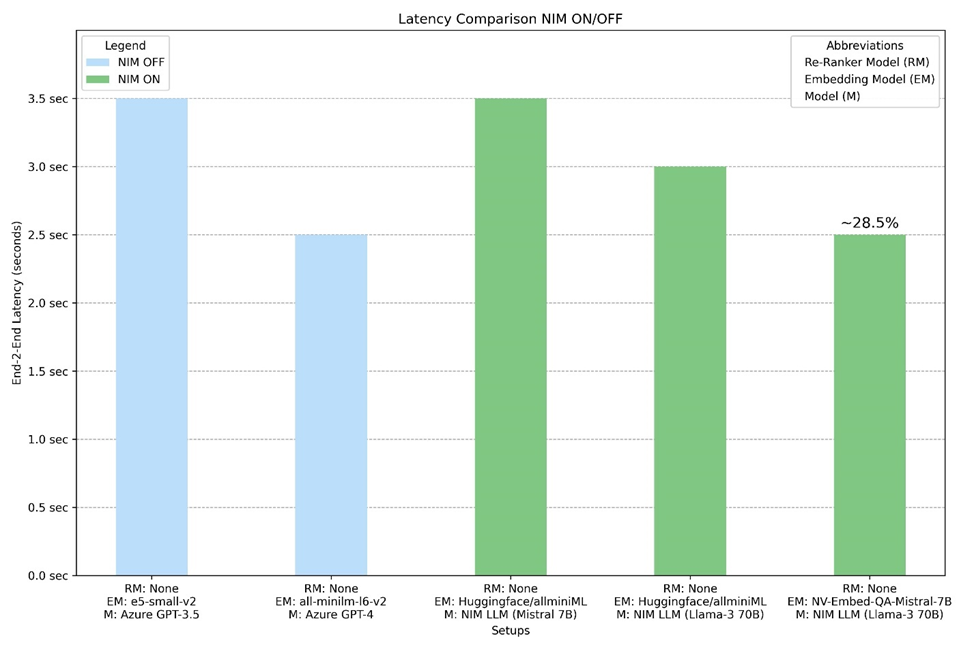
Combo 2 and Combo 5 demonstrated the lowest latency in testing at 2.5 seconds, a nearly 28.5% improvement over the slowest models. Combos 1 and 3 are the slowest at 3.5 seconds, while Combo 4 has a latency of 3 seconds. Combo 5 used both an NVIDIA NIM (Llama 3-70B) and NeMo Retriever embedding microservice (NV-Embed-QA-Mistral-7B), compared to Combo 2 using GPT-4 and an alternative embedding microservice.

Combo 5 showed the highest accuracy at 85%, a 15% absolute improvement from the baseline model tested. Combo 5 used both an NVIDIA NIM (Llama 3-70B) and NeMo Retriever embedding microservice (NV-Embed-QA-Mistral-7B). Similarly, Combo 4 used an NVIDIA NIM (Llama 3-70B) to achieve 83% accuracy. Combo 1 and Combo 3 saw the least accuracy at 70% and 65%, respectively.
Together, these results demonstrate Infosys achieved up to 28.5% lower latency and 15% absolute improvement in accuracy using NVIDIA NIM and NeMo Retriever embedding microservices. This improved model performance for TOSCA template generation enables network service designers and OSS solution architects to build network designs faster and reduce the costs of running AI models.
Sample use case for TOSCA template design generation
Here is an example use case to generate a TOSCA template consisting of Ethernet service with 100 Mbps bandwidth between 1PE and 2CE.
LLM response: Service Template design confirming to TOSCA standard in YAML format.
tosca_definitions_version: tosca_simple_yaml_1_3
description: TOSCA template for Ethernet service with 100 Mbps bandwidth between 1PE and 2CE
metadata:
ID: EthernetService-1PE2CE-100Mbps
vendor: Network Vendor
version: 1.0.0
Service_template:
node_templates:
PE_Node:
type: tosca.nodes.Network.Device
description: Provider Edge Node
requirements:
- bandwidth: 100 Mbps
CE_Node_01:
type: tosca.nodes.Network.Device
description: Customer Edge Node 1
CE_Node_02:
type: tosca.nodes.Network.Device
description: Customer Edge Node 2
Ethernet_Service:
type: tosca.nodes.Network.EthernetService
description: Ethernet service with 100 Mbps bandwidth
requirements:
- provider_pe_device: PE_Node
- customer_ce_device_1: CE_Node_01
- customer_ce_device_2: CE_Node_02
interfaces:
lifecycle:
INSTANTIATE: start_ethernet_service
relationship_types:
EthernetConnects:
derived_from: tosca.relationships.ConnectsTo
version: 1.0.0
node_types:
tosca.nodes.Network.EthernetService:
derived_from: tosca.nodes.Network.Root
version: 1.0.0
inputs:
bandwidth:
type: integer
Empowering network designers with efficiency and consistency
Network service designers spend the majority of their bandwidth in the manual generation of TOSCA templates, ranging from simple to complex.
Infosys achieved 28.5% lower latency and 15% absolute improvement in accuracy using NVIDIA NIM and NeMo Retriever embedding microservices for their generative AI model used in network design. By automating TOSCA template generation, telecom companies can streamline design workflows, enhance productivity, and ensure consistency for network design and orchestration.
Get started deploying generative AI applications with NVIDIA NIM. Try NeMo Retriever NIM microservices in the API Catalog. Explore generative AI solutions for telecom operations.
