这是世界上第四个帖子加速 IO系列它解决了存储问题,并与我们的合作伙伴分享了最近的成果和方向。我们将介绍新的 GPU 直接存储版本、优点和实施。
加速计算需要加速 IO 。否则,计算资源就会缺乏数据。考虑到所有工作流程中数据存储在内存中的比例正在减少,优化存储 IO 变得越来越重要。存储数据的价值、窃取或破坏数据的行为以及保护数据的法规要求也在不断增加。为此,人们对数据中心基础设施的需求日益增长,这些基础设施可以为用户提供更大程度的隔离,使其与不应访问的数据隔离开来。
GPU 直接存储
GPU 直接存储简化了存储和 GPU 缓冲区之间的数据流,适用于在 GPU 上消费或生成数据而无需 CPU 处理的应用程序。不需要增加延迟和阻碍带宽的额外拷贝。这种简单的优化导致了改变游戏规则的角色转换,数据可以更快地从远程存储(而不是 CPU 内存)馈送到 GPU s 。
GPU 直系亲属的最新成员
GPUDirect系列技术能够访问 GPU 并有效地将数据移入和移出 GPU 。直到最近,它还专注于内存到内存的传输。随着 GPU 直接存储(GDS)的添加,使用存储的访问和数据移动也加快了。 GPU 直接存储使在本地和远程存储之间向 CUDA 添加文件IO迈出了重要的一步。
使用 CUDA 11 . 4 发布 v1 . 0
GPU 直接存储经过两年多的审查,目前可作为生产软件使用。 GDS 以前仅通过单独安装提供,现在已并入 CUDA 11 . 4 版及更高版本,它可以是 CUDA 安装的一部分,也可以单独安装。对于 CUDA 版本X-Y的安装,libcufile-X-Y. so 用户库gds-tools-X-Y默认安装,nvidia-fs.ko内核驱动程序是可选安装。有关更多信息,请参阅 GDS 故障排除和安装文档。
GDS 现在在RAPIDS中提供。它还有 PyTorch 集装箱和MXNet 容器两种版本。
GDS 说明和好处
GPU 直接存储启用存储和 GPU 内存之间的直接数据路径。在本地 NVMe 驱动器或与远程存储器通信的 NIC 中,使用直接内存访问( DMA )引擎移动数据。
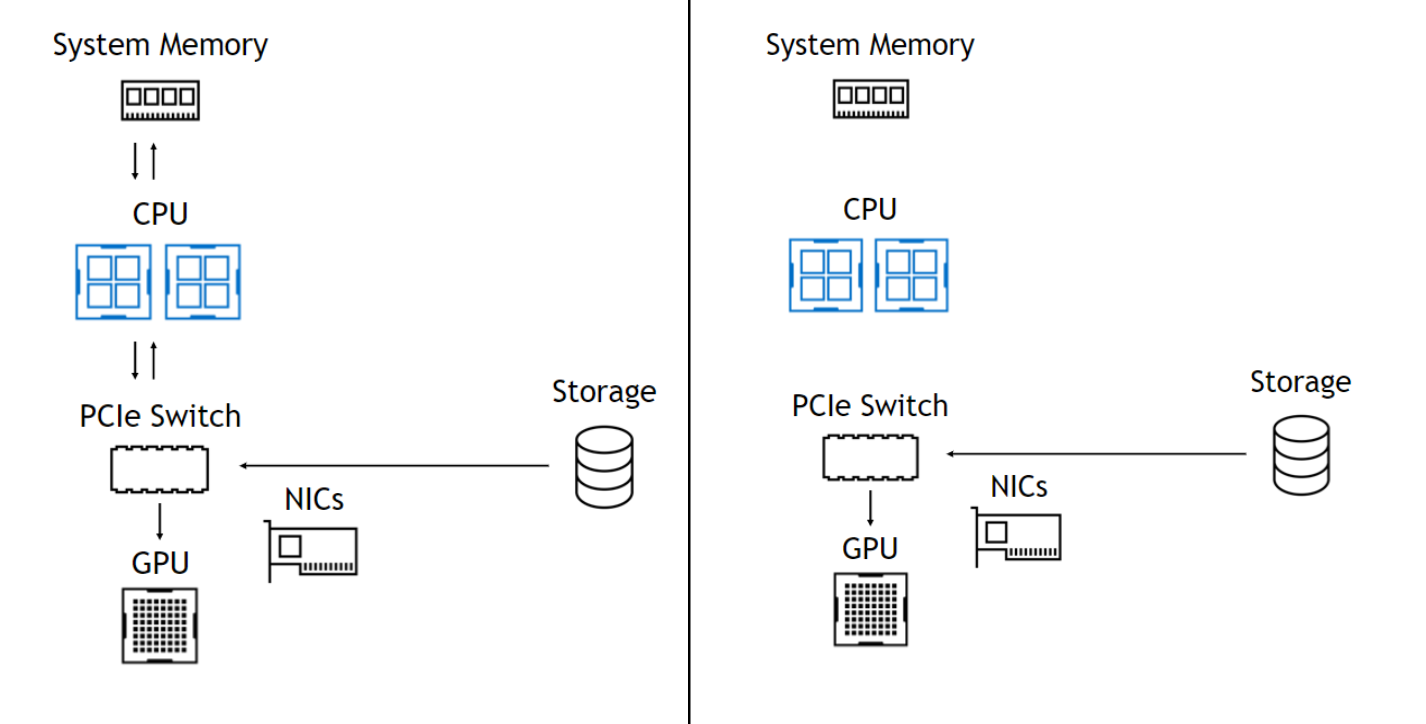
使用该 DMA 引擎意味着,尽管 DMA 的设置是一个 CPU 操作, CPU 和 GPU 完全不涉及数据路径,使它们自由且不受阻碍(图 1 )。在左侧,来自存储器的数据通过 PCIe 交换机进入,通过 CPU 进入系统内存,然后一直返回 GPU 。在右侧,数据路径跳过 CPU 和系统内存。下面总结了这些好处。
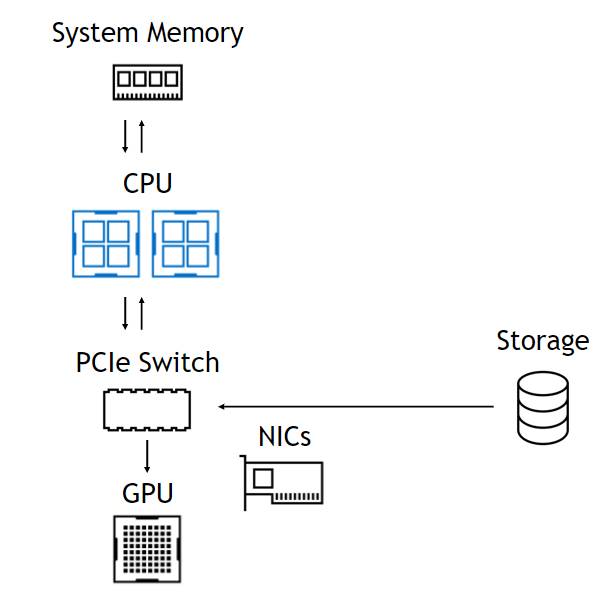
无 GPU 直接存储
受进出 CPU 的带宽限制。导致 CPU 反弹缓冲区的延迟。内存容量限制为 0 ( 1TB )。存储不是 CUDA 的一部分。没有基于拓扑的优化。
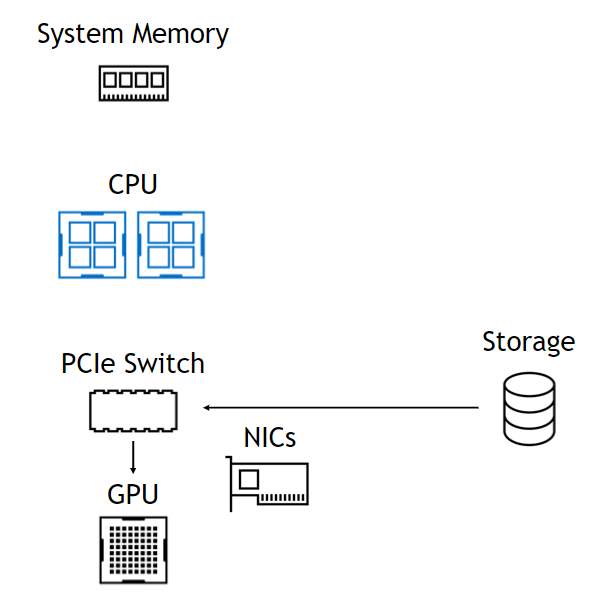
使用 GPU 直接存储
GPU 的带宽仅受 NIC 限制。由于直接复制,延迟更低。访问 O ( PB )容量。简单的 CUDA 编程模型。通过 NVLink 、 GPU 缓冲区自适应路由。
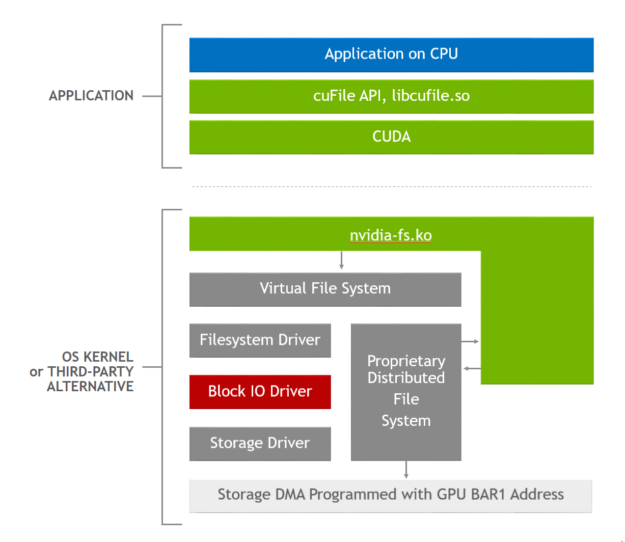
图 1 . GDS 软件堆栈,其中应用程序使用 cuFile API ,启用 GDS 的存储驱动程序调用nvidia-fs.ko内核驱动程序以获得正确的 DMA 地址。
GPU 直接存储提供了三个基本的性能优势:
- 增加带宽:通过消除通过 CPU 中的反弹缓冲区的需要,在某些平台上可以使用备用路径,包括通过 PCIe 交换机或 NVLink 提供更高带宽的平台。虽然 DGX 平台同时具有 PCIe 交换机和 NVLink ,但并非所有平台都具有。我们建议使用这两种方法来最大限度地提高性能。火星着陆器的例子实现了 8 倍的带宽增益。
- 潜伏期缩短:通过 CPU 内存避免额外拷贝的延迟和管理内存的开销(在极端情况下可能非常严重),从而减少延迟。延迟减少 3 倍是常见的。
- CPU 利用率降低:使用跳出缓冲区会在 CPU 上引入额外的操作,以执行额外的复制和管理内存缓冲区。当 CPU 利用率成为瓶颈时,有效带宽会显著下降。我们测量了多个文件系统的 CPU 利用率提高了 3 倍。
没有 GDS ,只有一条可用的数据路径:从存储器到 CPU ,从 CPU 到具有 CUDA Memcpy 的相关 GPU 。对于 GDS ,还有其他可用的优化:
- 用于与 DMA 引擎交互的 CPU 线程与最近的 CPU 内核密切相关。
- 如果存储器和 GPU 挂断不同的插槽,并且 NVLink 是可用的连接,则数据可通过存储器附近的 GPU 内存中的快速反弹缓冲区暂存,然后使用 CUDA 传输到最终的 GPU 内存目标缓冲区。这可能比使用 intersocket 路径(例如 UPI )快得多。
- 没有
cudaMemcpy参与分割 IO 传输,以适应 GPU BAR1 孔径,其大小随 GPU SKU 变化,或者在目标缓冲区未固定cuFileBufRegister的情况下,分割到预固定缓冲区。这些操作由libcufile.so用户库代码管理。 - 处理未对齐的访问,其中要传输的文件中的数据偏移量与页面边界不对齐。
- 在未来的GDS版本中,
cuFileAPI将支持异步和批处理操作。这使得 CUDA 内核能够在 CUDA 流中的读取之后对其进行排序,该 CUDA 流为该内核提供输入,并且在生成要写入的数据的内核之后对写入进行排序。随着时间的推移,cuFileAPI也将在 CUDA 图形的上下文中可用。
表 1 显示了 NVIDIA DGX-2 和 DGX A100 系统的峰值和测量带宽。该数据表明,在理想条件下,从本地存储到 GPU s 的可实现带宽超过了 CPU 内存的最大带宽,最高可达 1 TB 。通常从 PB 级远程内存测量的带宽可能是 CPU 内存实际提供带宽的两倍以上。
将 GPU 内存中无法容纳的数据溢出到甚至 PB 的远程存储中,可能会超过将其分页回 CPU 内存中 1 TB 的可实现性能。这是历史的一次显著逆转。
| Endpoint | DGX-2 (Gen3), GB/s |
DGX A100 (Gen4), GB/s |
|
| CPU | 50, peak | 100, peak | |
| Switch/GPU | 100, peak | 200*, peak |
|
| Endpoint | Capacity | Measured | |
| CPU sysmem | O(1TB) | 48-50 @ 4 PCIe | 96-100 @ 4 PCIe |
| Local storage | O(100TB) | 53+ @ 16 drives | 53+ @ 8 drives |
| RAID cards | O(100TB) | 112 (MicroChip) @ 8 | N/A |
| NICs | O(1PB) | 90+ @ 8 NICs | 185+ @ 8 NICs |
表 1 .在带宽超过 CPU 内存 1 TB 的情况下,可以访问数 PB 的数据。
*此处显示的 NVIDIA GPU 直接存储在 NVIDIA DGX A100 插槽 0-3 和 6-9 上的性能数字不是官方支持的网络配置,仅供实验使用。为计算和存储共享相同的网络适配器可能会影响 NVIDIA 先前在 DGX A100 系统上发布的标准或其他基准测试的性能。
GDS 的工作原理
NVIDIA 寻求尽可能采用现有标准,并在必要时明智地扩展这些标准。 POSIX 标准的pread和pwrite提供了存储和 CPU 缓冲区之间的拷贝,但尚未启用到 GPU 缓冲区的拷贝。随着时间的推移, Linux 内核中不支持 GPU 缓冲区的缺点将得到解决。
一种称为 dma _ buf 的解决方案正在进行中,该解决方案支持 NIC 或 NVMe 和 GPU 等设备之间的拷贝,它们是 PCIe 总线上的对等设备,以解决这一差距。同时, GDS 带来的性能提升太大,无法等待上游解决方案传播到所有用户。多种供应商提供了支持 GDS 的替代解决方案,包括 MLNX _ OFED (表 2 )。 GDS 解决方案涉及与 POSIX pread和pwrite类似的新 API cuFileRead或cuFileWrite。
动态路由、 NVLink 的使用以及 CUDA 流中使用的异步 API (仅可从 GDS 获得)等优化使
cuFileAPI 成为 CUDA 编程模型的持久特性,即使在 Linux 文件系统中的漏洞得到解决之后也是如此。
以下是GDS实现的功能。首先,当前Linux实现的基本问题是通过虚拟文件系统(VFS)向下传递 GPU 缓冲区地址作为DMA目标,以便本地NVMe或网络适配器中的DMA引擎可以执行到 GPU 内存或从 GPU 内存的传输。这会导致出现错误情况。我们现在有办法解决这个问题:在 CPU 内存中传递一个缓冲区地址。
当使用cuFile API (如cuFileRead或cuFileWrite)时,libcufile。因此,用户级库捕获 GPU 缓冲区地址,并替换传递给 VFS 的代理 CPU 缓冲区地址。就在缓冲区地址用于 DMA 之前,启用 GDS 的驱动程序对nvidia-fs.ko的调用识别 CPU 缓冲区地址,并再次提供替代 GPU 缓冲区地址,以便 DMA 可以正确进行。
libcufile.so中的逻辑执行前面描述的各种优化,如动态路由、预固定缓冲区的使用和对齐。图 2 显示了用于此优化的堆栈。cuFile API 是 Magnum IO 灵活抽象体系结构原则的一个示例,它支持特定于平台的创新和优化,如选择性缓冲和 NVLink 的使用。
了解更多
GPU 直接存储帖子是对 GPU 直接存储的最初介绍。我们向最终客户和原始设备制造商推荐 NVIDIA GPU 直接存储设计指南,向最终客户、原始设备制造商和合作伙伴推荐 NVIDIA GPU 直接存储概述指南。有关使用 GDS 编程的更多信息,请参阅cuFile API 参考指南。




