
跨平台软件开发对应用程序的构建过程提出了许多挑战。如何针对多个平台而不维护多个平台特定的构建脚本、项目或生成文件?如果您需要构建 CUDA 代码作为过程的一部分呢? CMake 是一个开源、跨平台的工具系列,旨在跨不同平台构建、测试和打包软件。许多开发人员使用 CMake 来使用简单的独立于平台和编译器的配置文件来控制他们的软件编译过程。 CMake 生成可在您选择的编译器环境中使用的本机 makefile 和工作区。 CMake 工具套件是由 Kitware 创建的,是为了响应对 ITK 和 VTK 等开源项目的强大、跨平台构建环境的需求。
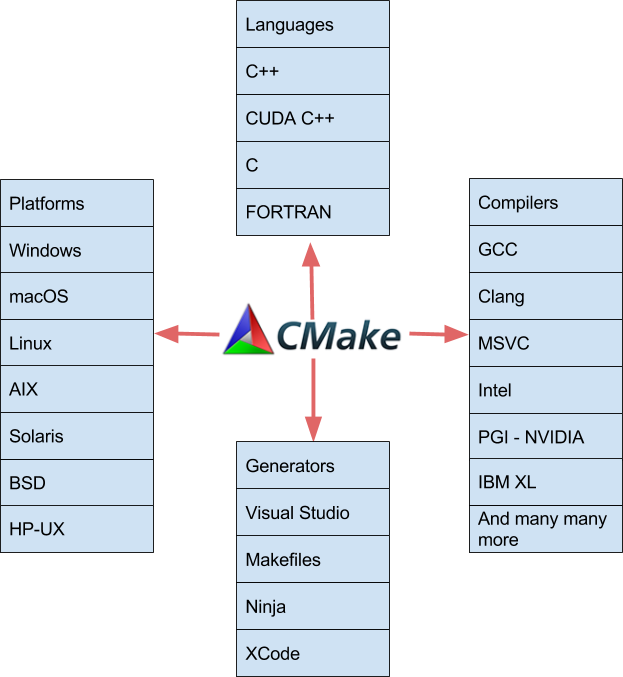
在这篇文章中,我想向您展示使用 cmake3 . 8 +( 3 . 9 支持 MSVC )的特性来构建 CUDA 应用程序是多么容易。从 2009 年起, CMake (从 2 . 8 . 0 开始)就提供了通过 Find CUDA 包提供的 cuda_add_executable 和 cuda_add_library 等自定义命令编译 CUDA 代码的能力。 CGEASE 3 . 8 使 CUDA C ++成为一种本质上支持的语言。 CUDA 现在加入了 CMake 支持的各种语言、平台、编译器和 ide ,如图 1 所示。
CMake 中的一个 CUDA 示例
让我们从一个用 CMake 构建 CUDA 的例子开始。清单 1 显示了名为“ particles ”的 CUDA 示例的 CMake 文件。我已经在 Github 上提供了 此示例的完整代码 。
cmake_minimum_required(VERSION 3.8 FATAL_ERROR)
project(cmake_and_cuda LANGUAGES CXX CUDA)
include(CTest)
add_library(particles STATIC
randomize.cpp
randomize.h
particle.cu
particle.h
v3.cu
v3.h
)
# Request that particles be built with -std=c++11
# As this is a public compile feature anything that links to
# particles will also build with -std=c++11
target_compile_features(particles PUBLIC cxx_std_11)
# We need to explicitly state that we need all CUDA files in the
# particle library to be built with -dc as the member functions
# could be called by other libraries and executables
set_target_properties( particles
PROPERTIES CUDA_SEPARABLE_COMPILATION ON)
add_executable(particle_test test.cu)
set_property(TARGET particle_test
PROPERTY CUDA_SEPARABLE_COMPILATION ON)
target_link_libraries(particle_test PRIVATE particles)
if(APPLE)
# We need to add the path to the driver (libcuda.dylib) as an rpath,
# so that the static cuda runtime can find it at runtime.
set_property(TARGET particle_test
PROPERTY
BUILD_RPATH ${CMAKE_CUDA_IMPLICIT_LINK_DIRECTORIES})
endif()
在我完成清单 1 所示的所有逻辑和特性之前,让我们先跳过构建。如果您使用 VisualStudio ,则需要使用 CGuess 3 . 9 和 VisualStudio CUDA 构建扩展(包含在 CUDA 工具包中),否则您可以使用 生成文件生成器(或忍者生成器) 与 nvcc ( NVIDIA CUDA 编译器)和 C ++编译器在您的路径中使用 CMASE 3 . 8 或更高。(或者,您可以将 CUDACXX 和 CXX 环境变量分别设置为 nvcc 和 C ++编译器的路径)。


为了配置 CMake 项目并生成一个 makefile ,我使用了以下命令
cmake -DCMAKE_CUDA_FLAGS=”-arch=sm_30” .
图 1 显示了输出。 CMADE 自动发现并验证 C ++和 CUDA 编译器并生成一个 MaMaFrimeProject 。注意,参数 -DCMAKE_CUDA_FLAGS="-arch=sm_30" 将 -arch=sm_30 传递给 nvcc ,告诉它以我计算机中的开普勒体系结构( SM _ 30 或 ComputeCapability 3 . 0 ) GPU 为目标。
接下来,图 1 显示了我如何使用命令 make -j4 调用构建。这运行了 make 多个线程,因此它并行编译 C ++和 CUDA 源文件。有关 CMake 如何确定在项目中的何处查找并行性的更多信息,请阅读“ “用你所有的核心来建设” 。 CMake 还可以自动管理将多种语言构建和链接到可执行文件或共享库中。
启用 CUDA
让我们深入研究 CMake 代码并研究不同的组件。和往常一样,根 CMake 文件中的第一个命令应该是 cmake_minimum_required ,它断言 CMake 版本足够新,并确保 CMake 可以确定当用户运行的 CMake 版本比需要的版本更新时,它需要保留哪些向后兼容性。
接下来,第 2 行是 Project 命令,它设置项目名称( cmake_and_cuda )并定义所需语言( C ++和 CUDA )。这使 CMake 能够识别和验证所需的编译器,并缓存结果。这将生成图 3 所示的公共缓存语言标志。
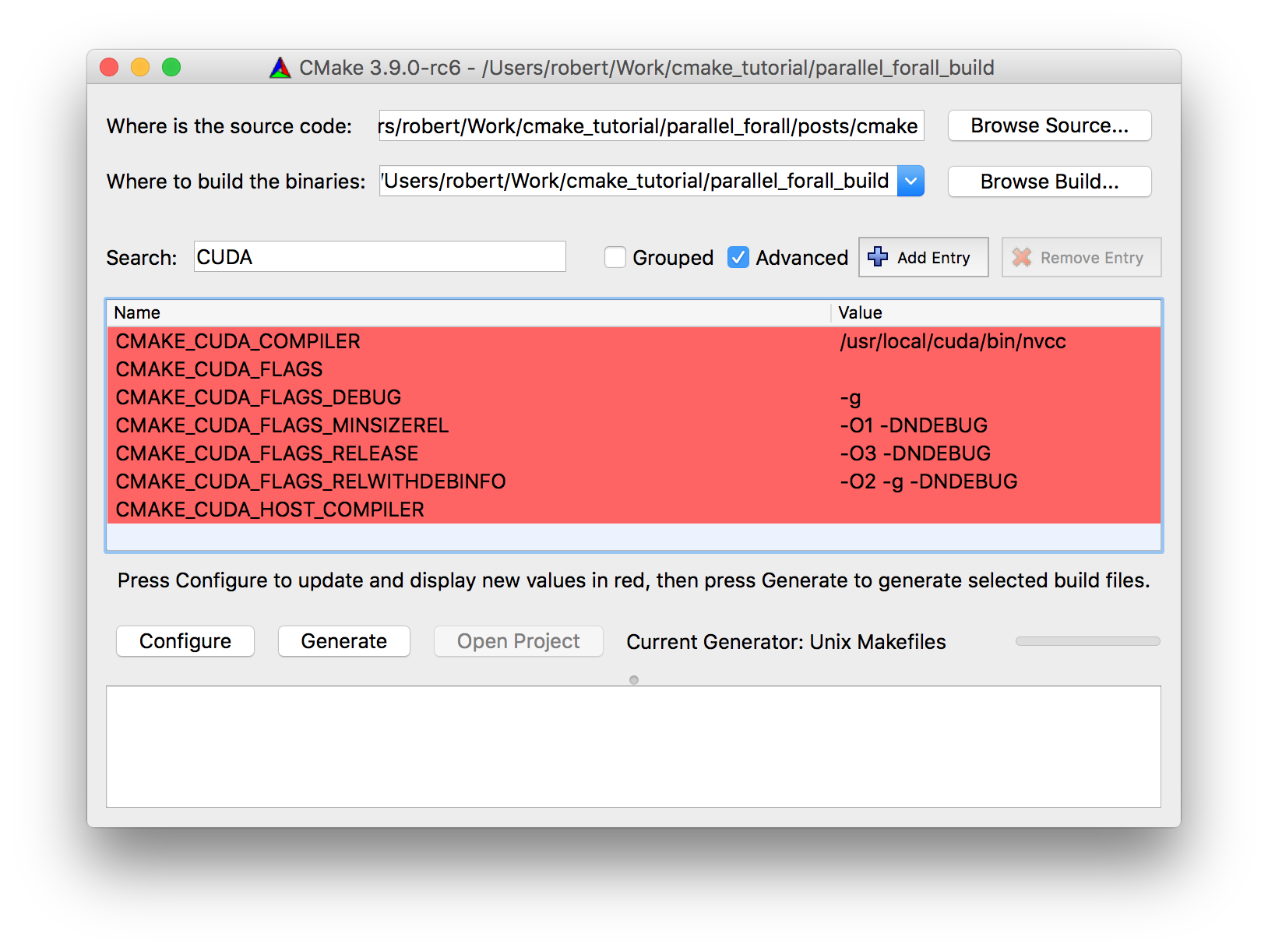
(调试、发布、 RelWithDebInfo 和 MinSizeRel )。
既然 CMake 已经确定了项目需要什么语言,并且配置了它的内部基础设施,我们就可以继续编写一些真正的 CMake 代码了。
用 CMake 建立图书馆
学习 CMake 时,每个人做的第一件事就是编写一个生成单个可执行文件的玩具示例 就像这个 。让我们更大胆一点,并生成一个可执行文件使用的静态库。
使用要求 是现代 CMake 的核心。 include 目录、编译器定义和编译器选项等信息可以与目标相关联,这样这些信息就可以通过 target_link_libraries 自动传播给使用者。在 CMake 的早期版本中,构建 CUDA 代码需要命令,比如 cuda_add_library 。不幸的是,这些命令无法参与使用需求,因此无法使用传播的编译器标志或定义。 CMake 中现在对 CUDA 的内在支持使使用 CUDA 的目标能够充分利用现代 CMake 使用需求,并为所有语言提供统一的 CMake 语法。
C ++语言层
在一个项目中,首先要配置的事情之一是 C ++语言级别( 98 , 11 , 14 , 17 …)。 CGuSE 3 . 1 介绍了为整个项目或基于每个目标的基础来设置 C ++语言级别的能力。还可以控制 CUDA 编译的 C ++语言级别。
您可以通过 CMAKE_CUDA_STANDARD 或 target_compile_features 命令轻松地要求特定版本的 CUDA 编译器。为了使 target_compile_features更容易与 CUDA 一起使用, CMake 使用了 CUDA C ++的同一组 C ++特征关键字。下面的代码展示了如何请求 C ++ 11 对 particles 目标的支持,这意味着粒子目标所使用的任何 CUDA 文件都会被 CUDA C ++ 11 启用( --std=c++11 参数] nvcc ]编译。
# Request that particles be built with --std=c++11 # As this is a public compile feature anything that links to particles # will also build with -std=c++11 target_compile_features(particles PUBLIC cxx_std_11)
启用位置无关代码
在处理大型项目时,通常会生成一个或多个共享库。作为共享库一部分的每个对象文件通常都需要在启用位置独立代码的情况下进行编译,这是通过设置 fPIC 编译器标志来完成的。不幸的是,并非所有编译器都支持 fPIC ,因此 CMake 在构建共享库时自动启用位置无关的代码,从而避免了这个问题。对于将链接到共享库的静态库,需要通过如下设置 POSITION_INDEPENDENT_CODE target 属性显式地启用位置无关的代码。
set_target_properties(particles PROPERTIES POSITION_INDEPENDENT_CODE ON)
CMake 3 . 8 支持 CUDA 编译的 POSITION_INDEPENDENT_CODE 属性,并在请求时构建所有可重新定位的主机端代码。对于那些希望在跨平台项目或内部共享库中使用 CUDA 的项目,或者希望支持深奥的 C ++编译器的项目,这是一个好消息。
可分离汇编
默认情况下, CUDA 编译器使用整个程序编译。实际上,这意味着所有设备函数和变量都需要位于单个文件或编译单元中。 单独编译和链接 是在 CUDA 5 . 0 中引入的,它允许将 CUDA 程序的组件编译成单独的对象。为了使其正常工作,任何使用可分离编译的库或可执行文件都有两个链接阶段。首先它必须为包含 CUDA 设备代码的所有对象执行设备链接,然后必须执行主机端链接,包括上一个链接阶段的结果。
可分离编译不仅允许项目维护一个代码结构,其中独立的函数被保存在不同的位置,它还有助于提高增量构建性能(所有基于 CMake 的项目的一个特性)。增量构建只允许重新编译和链接已修改的单元,这减少了构建时间。可分离编译的主要缺点是,对于驻留在不同编译位中的函数的调用,某些函数调用优化被禁用,因为编译器不知道被调用函数的详细信息。
CMake 现在基本上理解了独立编译和设备链接的概念。隐式地, CMake 会尽可能长时间地延迟 CUDA 代码的设备链接,因此,如果您使用可重定位的 CUDA 代码生成静态库,则设备链接将被推迟,直到静态库链接到共享库或可执行文件。这是一个显著的改进,因为现在可以将 CUDA 代码组合到多个静态库中,这在 CMake 中以前是不可能的。要控制 CMake 中的可分离编译,请按如下方式打开目标的 CUDA_SEPARABLE_COMPILATION 属性。
set_target_properties(particles PROPERTIES CUDA_SEPARABLE_COMPILATION ON)
PTX 生成
如果要将 PTX 文件打包用于加载时 JIT 编译,而不是将 CUDA 代码编译到库或可执行文件的集合中,则可以启用 CUDA_PTX_COMPILATION 属性,如下例所示。本例将一些 .cu 文件编译为 PTX ,然后指定安装位置。
add_library(CudaPTX OBJECT kernelA.cu kernelB.cu) set_property(TARGET CudaPTX PROPERTY CUDA_PTX_COMPILATION ON) install(TARGETS CudaPTX OBJECTS DESTINATION bin/ptx )
为了使 PTX 生成成为可能,对 CMake 进行了扩展,以便所有 对象库 都能够在生成器表达式中安装、导出、导入和引用。这也使得 PTX 文件能够被 bin2c 等工具转换或处理,然后作为 C 字符串嵌入到库或可执行文件中。 这是一个基本的例子 。
CMake 和 CUDA 一起就像花生酱和果酱
我希望这篇文章向您展示了 CMake 如何自然地支持构建 CUDA 应用程序。如果您是 CMake 的现有用户,请试用 CMake 3 . 9 并利用改进的 CUDA 支持。如果您不是 CMake 的现有用户,请试用 CMake 3 . 9 ,亲身体验一下它对于构建使用 CUDA 的跨平台项目有多好。
您可以在 https://cmake.org/download/ 下载最新的 cmake3 . 9 二进制文件,也可以在 https://cmake.org/documentation/ 上找到官方文档。




