
高性能计算( HPC )和人工智能已经将超级计算机作为主要的数据处理引擎,广泛应用于商业领域,使研究、科学发现和产品开发成为可能。这些系统可以进行复杂的模拟,开启软件编写软件的人工智能新时代。
超级计算领导力是指科学和创新领导力,它解释了许多政府、研究机构和企业为构建更快、更强大的超级计算平台而进行的投资。从超级计算系统中提取尽可能高的性能,同时实现高效利用,传统上与现代云计算的安全、多租户体系结构不兼容。
一个云本地超级计算平台首次提供了两全其美,将峰值性能和集群效率与安全隔离和多租户的现代零信任模型结合起来。实现这种架构转换的关键元素是 NVIDIA BlueField 数据处理单元( DPU )。 DPU 是一个完全集成的片上数据中心平台,为每个超级计算节点注入了两种新功能:
- 基础设施控制平面处理器 – 保护用户访问、存储访问、网络和计算节点的生命周期编排,减轻主计算处理器的负担并实现裸机多租户。
- 带硬件加速的隔离线速率数据通路 – 实现裸机性能。
HPC 和 AI 通信框架和库对延迟和带宽敏感,它们在决定应用程序性能方面起着关键作用。将库从主机 CPU 或 GPU 卸载到 BlueField DPU 为通信和计算的并行进程创建了最高程度的重叠。它还减少了操作系统抖动的负面影响,显著提高了应用程序性能。
云本地超级计算机体系结构的开发基于开放社区开发,包括商业公司、学术组织和政府机构。这个不断增长的社区对于开发下一代超级计算至关重要。
我们在本文中分享的一个例子是 MVAPICH2- DPU 库,由 X-ScaleSolutions 设计和开发。 MVAPICH2- DPU 库包含了消息传递接口( MPI )标准的非阻塞集合的卸载。这篇文章概述了这种卸载背后的基本概念,以及最终用户如何使用 MVAPICH2- DPU MPI 库来加速科学应用程序的执行,特别是使用密集的非阻塞 all-to-all 操作。
BlueField DPU
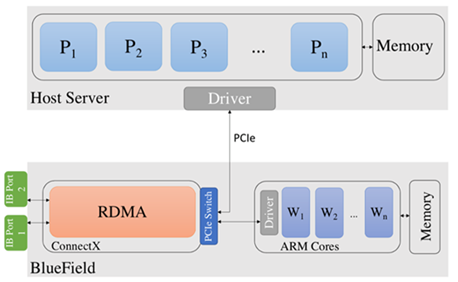
图 1 显示了 BlueField DPU 体系结构及其与主机计算平台的连接的概述。 DPU 通过 ConnectX-6 适配器具有 InfiniBand 网络连接。此外,它还有一组 Arm 内核。 Bluefield-2 DPU 有一组 8 个 Arm 内核,每个内核的工作频率为 2 . 0ghz 。 Arm 内核还有 16GB 的共享内存。
MVAPICH2- DPU MPI 库
MVAPICH2- DPU MPI 库是 MVMPI 库 的派生。该库经过优化,可利用 InfiniBand 网络充分发挥 BlueField DPU 的潜力。
最新的 MVAPICH2- DPU 2021 . 06 版本具有以下功能:
- 基于 MVAPICH2 2 . 3 . 6 ,符合 MPI 3 . 1 标准
- 支持 MV2 . 3 . 6 版本 提供的所有功能
- 将非阻塞集合卸载到 DPU 的新框架
- 将非阻塞 Alltoall ( MPI \ Ialltoall )卸载到 DPU
- 所有非阻塞集合的计算重叠率为 100%
- 使用 MPI Ialltoall 非阻塞集合加速科学应用
MVAPICH2- DPU MPI 库入门
MVAPICH2- DPU 库可从 X-ScaleSolutions 获得:
- 发送电子邮件至 contactus@x-scalesolutions.com
- 填写联系人 形式
有关更多信息,请参阅 MVAPICH2-DPU 产品页。
OSU 微基准的示例执行
OSU MPI 微基准 的副本与 MVAPICH2- DPU MPI 包集成在一起。 OMB 基准套件由非阻塞集体操作的基准组成。这些基准旨在评估非阻塞 MPI 集合使用的计算和通信之间的重叠能力。
可以执行 OMB 包中的非阻塞集体基准,以评估以下指标:
- 重叠功能
- 启动非阻塞集合后立即合并计算步骤时的总执行时间
在 HPC-AI 咨询委员会集群上运行了一组 OMB 实验,其中 32 个节点与支持 HDR 200Gb / s InfiniBand 连接的 32 个 BlueField DPU s 相连。每个主机节点都有双插槽 Intel Xeon 16 核 CPU E5-2697A V4 @ 2 . 60 GHz 。每个 Bluefield-2 DPU 有 8 个 Arm 核@ 2 . 0ghz 和 16gb 内存。
图 2 显示了分别运行 512 个( 32 个节点,每个节点有 16 个进程( PPN ))和 1024 个( 32 个节点,每个节点有 32 个 PPN ) MPI 进程的 MPI \ u ialtoall 非阻塞集合基准的性能结果。随着消息大小的增加, MVAPICH2- DPU 库可以显示计算和 MPI Ialltoall 非阻塞集合之间的峰值( 100% )重叠。相比之下,没有这种 DPU 卸载功能的 MVAPICH2 默认库可以在计算和 MPI (所有非阻塞)集合之间提供很少的重叠。
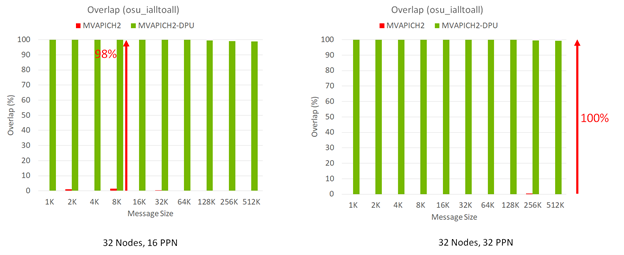
当 MPI 应用程序中的计算步骤以重叠方式与 MPI Ialltoall 非阻塞集合操作一起使用时, MVAPICH2- DPU MPI 库在整个程序执行时间内提供了显著的性能优势。这是可能的,因为 DPU 中的 Arm 内核可以实现非阻塞的 all-to-all 操作,而主机上的 Xeon 内核正在执行峰值重叠的计算(图 2 )。
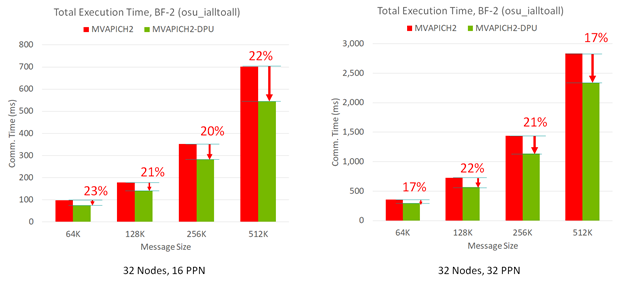
图 3 显示,与基本的 MVAPICH2 MPI 库相比, MVAPICH2- DPU MPI 库可以提供高达 23% 的性能优势。这是在 32 节点的 OMB-MPI-Iall 基准测试中跨消息大小和 ppn 的测试。
加速 P3DFFT 应用程序内核
P3DFFT 是一种常见的 MPI 内核,用于许多使用快速傅立叶变换( FFT )的终端应用程序。这个 MPI 内核的一个版本是由 P3DFFT 开发人员设计的,它使用非阻塞的 all-to-all 集合操作和计算步骤来利用最大的重叠。
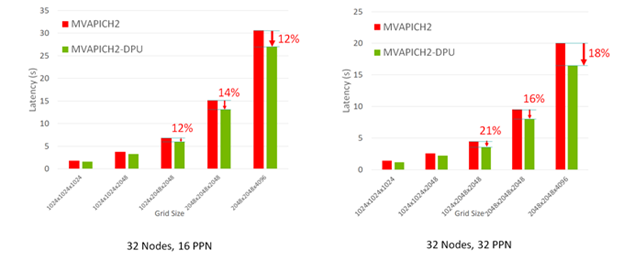
P3DFFT MPI 内核的增强版本在 32 节点 HPC-AI 集群上使用 MVAPICH2- DPU MPI 库进行了评估。图 4 显示了 MVAPICH2- DPU MPI 库将 P3DFFT 应用程序内核的总体执行时间减少了 21% ,适用于各种网格大小和 ppn 。
概括
NVIDIA DPU 体系结构提供了新的功能,可以将任何中间件的功能卸载到 DPU 上的可编程 Arm 内核。必须重新设计 MPI 库,以利用这些功能加速科学应用。
MVAPICH2- DPU MPI 库是利用这种 DPU 功能的领先库。 MVAPICH2- DPU 库的初始版本提供了对 MPI \ u ialtoall nonblocking collectives 的卸载支持,显示了计算和非阻塞 alltoall collective 之间 100% 的重叠。在 1024mpi 进程运行时,它可以将 P3DFFT 应用程序内核执行时间缩短 21% 。
这项研究证明了使用 MVAPICH2- DPU MPI 库的 DPU 体系结构具有很强的 ROI 。随着 DPU 体系结构的进步,即将发布的其他 MPI 功能的附加卸载功能将显著加快云本地超级计算系统上的科学应用。
有关 MVAPICH2- DPU MPI 库及其路线图的更多信息,请发送电子邮件至 contactus@x-scalesolutions.com 或填写 联系方式 。




