
NetworkX 在其文档中指出,它是“… 用于创建、操作和研究复杂网络的结构、动态和功能的 Python 软件包”。自 2005 年首次公开发布以来,它已成为最受欢迎的 Python 图形分析库。这也许可以解释为什么 NetworkX 仅在 2023 年 9 月就累计了 2700 万 PyPI 下载量。
NetworkX 如何实现如此大规模的吸引力?是否有 NetworkX 不足的用例,如果是,可以做些什么来解决这些问题?我将在本文中探讨这些问题以及更多内容。
NetworkX:轻松进行图形分析
NetworkX 之所以在数据科学家、学生和许多对图形分析感兴趣的其他人中如此受欢迎,有几个原因。NetworkX 是开源的,由一个庞大而友好的社区提供支持,他们渴望回答问题并提供帮助。代码成熟且有据可查,软件包本身易于安装,不需要额外的依赖项。但最重要的是,NetworkX 拥有大量算法,通过易于使用的 API 涵盖每个人的东西(包括绘图!)。
只需几行简单的代码,您就可以使用提供的任何算法加载和分析图形数据。以下是找到简单的四节点图形的最短加权路径的示例:
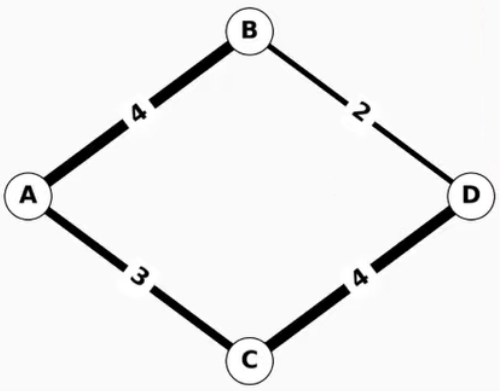
>>> import networkx as nx
>>> G = nx.Graph()
>>> G.add_edge("A", "B", weight=4)
>>> G.add_edge("B", "D", weight=2)
>>> G.add_edge("A", "C", weight=3)
>>> G.add_edge("C", "D", weight=4)
>>> nx.shortest_path(G, "A", "D", weight="weight")
['A', 'B', 'D']
只需按 Python 提示轻松输入几行,即可交互式探索图形数据。
缺少什么?
虽然 NetworkX 提供了开箱即用的大量可用性,但大中型网络的性能和可扩展性远远没有达到一流水平,并且会严重限制数据科学家的工作效率。
为了了解图形大小和算法选项对运行时的影响,以下是一个有趣的分析,它回答了有关真实数据集的问题。
使用中间性中心审查有影响力的美国专利
该图,由斯坦福网络分析平台 ( SNAP )提供,是一张显示了 1975 年至 1999 年期间授予的专利的专利引文图,这些专利共被引用了 16522438 次。如果您知道哪些专利比其他专利更重要,您可能会了解它们的相对重要性。
可以使用 pandas 库处理引文图形,以创建包含图形边缘的 DataFrame.DataFrame 有两列:一列用于源节点,另一列用于每个边缘的目标节点。然后,NetworkX 可以获取此 DataFrame 并创建图形对象,然后使用该对象运行介于中间性的中心位置。
间隔中心性是一个量化节点在多大程度上充当其他节点之间的媒介的指标,具体取决于节点所在最短路径的数量。在专利引文的上下文中,它可用于衡量专利在多大程度上连接了其他专利。
使用 NetworkX,您可以betweenness_centrality找到这些中心专利。NetworkX 选择k随机节点,用于间隔核心计算所使用的最短路径分析。k从而以增加计算时间为代价,获得更准确的结果。
以下代码示例加载引文图形数据,创建 NetworkX 图形对象,并运行 Betweenness_centrality.
###############################################################################
# Run Betweenness Centrality on a large citation graph using NetworkX
import sys
import time
import networkx as nx
import pandas as pd
k = int(sys.argv[1])
# Dataset from https://snap.stanford.edu/data/cit-Patents.txt.gz
print("Reading dataset into Pandas DataFrame as an edgelist...", flush=True,
end="")
pandas_edgelist = pd.read_csv(
"cit-Patents.txt",
skiprows=4,
delimiter="\t",
names=["src", "dst"],
dtype={"src": "int32", "dst": "int32"},
)
print("done.", flush=True)
print("Creating Graph from Pandas DataFrame edgelist...", flush=True, end="")
G = nx.from_pandas_edgelist(
pandas_edgelist, source="src", target="dst", create_using=nx.DiGraph
)
print("done.", flush=True)
print("Running betweenness_centrality...", flush=True, end="")
st = time.time()
bc_result = nx.betweenness_centrality(G, k=k)
print(f"done, BC time with {k=} was: {(time.time() - st):.6f} s")
通过k运行代码时,值为 10:
bash:~$ python nx_bc_demo.py 10
Reading dataset into Pandas DataFrame as an edgelist...done.
Creating Graph from Pandas DataFrame edgelist...done.
Running betweenness_centrality...done, BC time with k=10 was: 97.553809 s
如您所见,betweenness_centrality在一个中等大小的图形上k=10而快速的现代 CPU (Intel Xeon Platinum 8480CL)几乎需要 98 秒。要实现更高水平的准确性以符合您对这种规模的图形的期望,就需要大幅提高k但是,这将导致运行时间更长,正如本文稍后的基准测试结果中所强调的那样,执行时间会延长到几个小时。
RAPIDS cuGraph:速度和 NetworkX 互操作性
创建 RAPIDS cuGraph 项目的目的是为了弥补基于 GPU 的快速、可扩展的图形分析与 NetworkX 易用性之间的差距。如需了解更多信息,请参阅 RAPIDS cuGraph 增加了 NetworkX 和 DiGraph 兼容性。
cuGraph 在设计时就考虑到了 NetworkX 互操作性,这一点在您仅替换betweenness_centrality使用 cuGraph 的betweenness_centrality并保留代码的其余部分。
因此,只需更改几行代码,即可将速度提高 12 倍以上:
###############################################################################
# Run Betweenness Centrality on a large citation graph using NetworkX
# and RAPIDS cuGraph.
# NOTE: This demonstrates legacy RAPIDS cuGraph/NetworkX interop. THIS CODE IS
# NOT PORTABLE TO NON-GPU ENVIRONMENTS! Use nx-cugraph to GPU-accelerate
# NetworkX with no code changes and configurable CPU fallback.
import sys
import time
import cugraph as cg
import pandas as pd
k = int(sys.argv[1])
# Dataset from https://snap.stanford.edu/data/cit-Patents.txt.gz
print("Reading dataset into Pandas DataFrame as an edgelist...", flush=True,
end="")
pandas_edgelist = pd.read_csv(
"cit-Patents.txt",
skiprows=4,
delimiter="\t",
names=["src", "dst"],
dtype={"src": "int32", "dst": "int32"},
)
print("done.", flush=True)
print("Creating Graph from Pandas DataFrame edgelist...", flush=True, end="")
G = cg.from_pandas_edgelist(
pandas_edgelist, source="src", destination="dst", create_using=cg.Graph(directed=True)
)
print("done.", flush=True)
print("Running betweenness_centrality...", flush=True, end="")
st = time.time()
bc_result = cg.betweenness_centrality(G, k=k)
print(f"done, BC time with {k=} was: {(time.time() - st):.6f} s")
当您在同一台机器上使用相同的k值,您可以看到它的速度提高了 12 倍以上:
bash:~$ python cg_bc_demo.py 10
Reading dataset into Pandas DataFrame as an edgelist...done.
Creating Graph from Pandas DataFrame edgelist...done.
Running betweenness_centrality...done, BC time with k=10 was: 7.770531 s
此示例很好地展示了 cuGraph 与 NetworkX 的互操作性。但是,在将 cuGraph 添加到代码中时,有些实例需要您做出更重大的更改。
许多差异都是有意的(出于性能原因,不同的选项可以更好地映射到 GPU 实现,不支持的选项等),而另一些则是不可避免的(cuGraph 实施的算法较少,cuGraph 需要 GPU,等等)。这些差异需要您添加特殊情况代码来转换选项,或者检查代码是否在 cuGraph 兼容的系统上运行,如果它们打算支持没有 GPU 或 cuGraph 的环境,则调用等效的 NetworkX API.
cuGraph 本身是一个易于使用的 Python 库,但它并不打算取代 NetworkX.
与此同时,NetworkX 增加了调度 … …
NetworkX 最近增加了向第三方提供的不同分析后端分配 API 调用的功能。这些后端可以为各种 NetworkX API 提供替代实现,从而大大提高性能。
后端可以通过backend=keyword支持的 API 上的参数,或者通过设置NETWORKX_AUTOMATIC_BACKENDS环境变量。
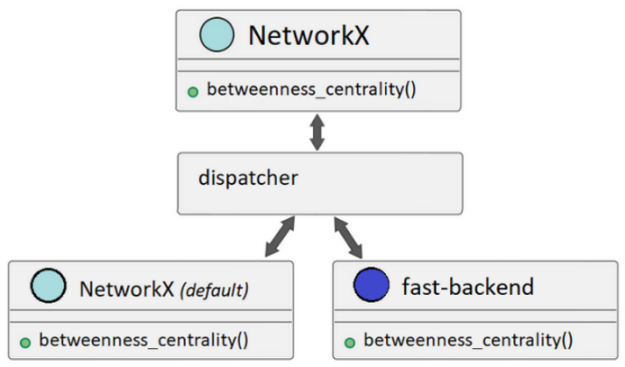
如果发出了 NetworkX API 调用,但后端无法支持该调用,则可以将 NetworkX 配置为引发信息性错误或自动回退到其默认实现以满足调用要求(图 2)。
即使后端已安装且可用,如果您未指定要使用的一个或多个后端,NetworkX 也会使用默认实现。
通过使其他图形库能够通过后端轻松扩展 NetworkX,NetworkX 成为标准的图形分析前端。这意味着更多用户可以使用其他图形库的功能,而无需使用与新库相关的学习曲线和集成时间。
库维护人员还可以从 NetworkX 调度中受益,因为他们可以覆盖更多用户,而不会产生维护面向用户的 API 的开销。相反,他们可以专注于提供后端。
使用 nx-cugraph 的 GPU 加速 NetworkX
NetworkX 调度为 RAPIDS cuGraph 团队创建 nx-cugraph 打开了大门,nx – cugraph 是一个新项目,基于 RAPIDS cuGraph 提供的图形分析引擎为 NetworkX 添加了后端。
此方法还可减少 nx-cugraph 的依赖项,并避免 cuGraph Python 库添加的代码路径,从而与 RAPIDS cuDF 进行高效集成,而 NetworkX 不需要这样做。
借助 nx-cugraph,NetworkX 用户最终可以获得一切:易用性、GPU 和非 GPU 环境之间的可移植性以及性能,所有这些都无需更改代码。
但也许最棒的是,您现在可以通过添加 GPU 和 nx-cugraph 来解锁以前因运行时间过长而不实际的用例。有关更多信息,请参阅本文后面的基准测试部分。
安装 nx-cugraph
假设已安装 NetworkX 3.2 或更高版本,则可以使用 conda 或 pip 安装 nx-cugraph.
conda
conda install -c rapidsai-nightly -c conda-forge -c nvidia nx-cugraph
pip
python -m pip install nx-cugraph-cu11 --extra-index-url https://pypi.nvidia.com
Nightly wheel 构建在 23.12 版本之前不可用,因此稳定版本的索引 URL 将用于pip install命令。
有关安装任何 RAPIDS 包的更多信息,请参阅 快速本地安装。
使用 nx-cugraph 重温 NetworkX 间隔中心性
当您安装 nx-cugraph 并指定 cugraph 后端时,NetworkX 会分配betweenness_centrality调用 nx-cugraph.您无需更改代码即可了解 GPU 加速的优势。
以下运行是在本文后面的基准测试部分中使用的同一系统上完成的。这些演示也不包括热身运行,这可以提高性能,但稍后展示的基准测试确实做到了。
以下是在 k=10 的情况下,在美国专利数据集上运行的初始 NetworkX:
bash:~$ python nx_bc_demo.py 10
Reading dataset into Pandas DataFrame as an edgelist...done.
Creating Graph from Pandas DataFrame edgelist...done.
Running betweenness_centrality...done, BC time with k=10 was: 97.553809 s
在不更改代码的情况下,设置环境变量NETWORKX_AUTOMATIC_BACKENDS使用 nx-cugraphbetweenness_centrality运行并观察速度提升 6.8 倍:
bash:~$ NETWORKX_AUTOMATIC_BACKENDS=cugraph python nx_bc_demo.py 10
Reading dataset into Pandas DataFrame as an edgelist...done.
Creating Graph from Pandas DataFrame edgelist...done.
Running betweenness_centrality...done, BC time with k=10 was: 14.286906 s
更大k值会导致默认 NetworkX 实现速度显著放缓:
bash:~$ python nx_bc_demo.py 50
Reading dataset into Pandas DataFrame as an edgelist...done.
Creating Graph from Pandas DataFrame edgelist...done.
Running betweenness_centrality...done, BC time with k=50 was: 513.636750 s
在相同的位置使用 cugraph 后端k值将导致速度提升 31 倍:
bash:~$ NETWORKX_AUTOMATIC_BACKENDS=cugraph python nx_bc_demo.py 50
Reading dataset into Pandas DataFrame as an edgelist...done.
Creating Graph from Pandas DataFrame edgelist...done.
Running betweenness_centrality...done, BC time with k=50 was: 16.389574 s
如你所见,当你增加k您会看到加速增加。越大k由于 GPU 具有很高的并行处理能力,因此在使用 cugraph 后端时,值对运行时的影响很小。
事实上,您可以使用k在与整体运行时间几乎没有区别的情况下提高准确性:
bash:~$ NETWORKX_AUTOMATIC_BACKENDS=cugraph python nx_bc_demo.py 500
Reading dataset into Pandas DataFrame as an edgelist...done.
Creating Graph from Pandas DataFrame edgelist...done.
Running betweenness_centrality...done, BC time with k=500 was: 18.673590 s
设置k如果使用默认的 NetworkX 实现需要一个多小时,但如果使用 cugraph 后端,则只需几秒钟。有关更多信息,请参阅下一节基准测试。
基准测试
使用以下数据集和系统硬件配置,使用和不使用 nx-cugraph 的 NetworkX 基准测试结果如表 1-3 所示:
- 数据集:定向图形,包含 370 万个节点和 1650 万个边缘
- CPU: 英特尔 Xeon Platinum 8480CL,2TB
- GPU: NVIDIA H100,80GB
这些基准测试使用 pytest 和 pytest-benchmark 插件运行。每次运行都包括 NetworkX 和 nx-cugraph 的热身步骤,可提高测量运行的性能。
基准测试代码可以在 cuGraph Github 库 中找到。
nx.betweenness_centrality(G, k=k)
| k=10 | k=20 | k=50 | k=100 | k=500 | k=1000 | |
| NetworkX | 97.28 秒 | 184.77 秒 | 463.15 秒 | 915.84 秒 | 4585.96 秒 | 9125.48 秒 |
| nx-cugraph | 8.71 秒 | 8.26 秒 | 8.91 秒 | 8.67 秒 | 11.31 秒 | 14.37 秒 |
| 加速 | 1117 倍 | 22.37 倍 | 51.96 倍 | 105.58 倍 | 405.59 X | 634.99 X |
nx.edge_betweenness_centrality(G, k=k)
| k=10 | k=20 | k=50 | k=100 | k=500 | k=1000 | |
| NetworkX | 112.22 秒 | 211.52 秒 | 503.57 秒 | 993.15 秒 | 4937.70 秒 | 9858.11 秒 |
| nx-cugraph | 19.62 秒 | 19.93 秒 | 21.26 秒 | 22.48 秒 | 41.65 秒 | 57.79 秒 |
| 加速 | 5.72 倍 | 10.61 倍 | 23.69 倍 | 44.19 倍 | 118.55 倍 | 170.59 倍 |
nx.community.louvain_communities(G)
| NetworkX | 2834.86 秒 |
| nx-cugraph | 21.59 秒 |
| 加速 | 131.3 倍 |
结束语
NetworkX 调度是 NetworkX 演变的新篇章,这将使更多用户在以前不可行的用例中采用 NetworkX.
可互换的第三方后端使 NetworkX 成为标准化的前端,您无需再重写 Python 代码以使用不同的图形分析引擎。nx-cugraph 将基于 cuGraph 的 GPU 加速和可扩展性直接添加到 NetworkX,因此您最终可以在不更改代码的情况下从 NetworkX 获得所缺少的速度和可扩展性。
由于 NetworkX 和 nx-cugraph 都是开源项目,因此欢迎提供反馈、建议和贡献。如果您想看到一些内容,例如 nx – cugraph 中的特定算法或其他可调度的 NetworkX API,请在适当的 GitHub 项目中留下建议:
如果您想详细了解如何使用 nx-cugraph 在 GPU 上加速 NetworkX,请注册参加 AI 和数据科学虚拟峰会。




