模拟或 合成数据 生成是人工智能工具发展的一个重要趋势。传统上,这些数据集可用于解决低数据问题或边缘情况场景,而或许现在存在于可用的实际数据集中。
合成数据的新兴应用包括建立模型性能水平、量化适用领域,以及下一代系统工程,其中人工智能模型和传感器是串联设计的。

Blender 是生成这些数据集的一个常用且引人注目的工具。它是免费使用和开源的,但同样重要的是,它可以通过强大的 Python API 完全扩展。 Blender 的这一特性使其成为视觉图像渲染的一个有吸引力的选择。因此,它已被广泛用于此目的,有 18 +渲染引擎选项可供选择。
集成到 Blender 中的渲染引擎(如 Cycles )通常具有紧密集成的 GPU 支持,包括最先进的 NVIDIA RTX 支持。但是,如果在可视化渲染引擎之外需要高性能级别,例如合成 SAR 图像的渲染,那么 Python 环境对于实际应用程序来说可能过于迟缓。加速这段代码的一个选择是使用流行的 Numba 包将 Python 代码的部分预编译成 C 。然而,这仍有改进的余地,特别是在采用领先的 GPU 体系结构进行科学计算方面。
GPU 科学计算功能可直接从 Blender 中获得,允许使用简单的统一工具,利用 Blender 强大的几何体创建功能以及尖端计算环境。对于 blender2 . 83 +的最新变化,可以使用 CuPy (一个专门用于数组计算的 GPU 加速 Python 库)直接从 Python 脚本中完成。
根据这些想法,下面的教程将比较两种不同的加速矩阵乘法的方法。第一种方法使用 Python 的 Numba 编译器,而第二种方法使用 NVIDIA GPU-compute API, CUDA 。这些方法的实现可以在 rleonard1224/matmul GitHub repo 中找到,还有一个 Dockerfile ,它设置了 anaconda 环境,从中可以运行 CUDA – 加速的 Blender Python 脚本。
矩阵乘法算法
作为讨论用于加速矩阵乘法的不同方法的前奏,我们简要回顾了矩阵乘法本身。
对于两个矩阵的乘积![[A \cdot B]](https://s0.wp.com/latex.php?latex=%5BA+%5Ccdot+B%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[A]](https://s0.wp.com/latex.php?latex=%5BA%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[B]](https://s0.wp.com/latex.php?latex=%5BB%5D&bg=ffffff&fg=000&s=0&c=20201002)
行和
列,即
matrix.
matrix.
- 产品
结果是
matrix.
如果![[C]](https://s0.wp.com/latex.php?latex=%5BC%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[C[i,j]]](https://s0.wp.com/latex.php?latex=%5BC%5Bi%2Cj%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[C[i,j] = \Sigma_{r = 1}^{n} A[i,r] \cdot B[r,j]]](https://s0.wp.com/latex.php?latex=%5BC%5Bi%2Cj%5D+%3D+%5CSigma_%7Br+%3D+1%7D%5E%7Bn%7D+A%5Bi%2Cr%5D+%5Ccdot+B%5Br%2Cj%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
麻木加速度
通过使用 Numba . jit decorator ,可以将 Numba 编译器应用于 Python 脚本中的函数。通过预编译到 C 中,在 Python 代码中使用 numba . jit decorator 可以显著减少循环的运行时间。由于直接转换为代码的矩阵乘法需要嵌套 for 循环,因此使用 numba . jit decorator 可以显著减少用 Python 编写的矩阵乘法函数的运行时间。 matmulnumba.py Python 脚本实现矩阵乘法并使用 numba . jit decorator 。
CUDA 加速度
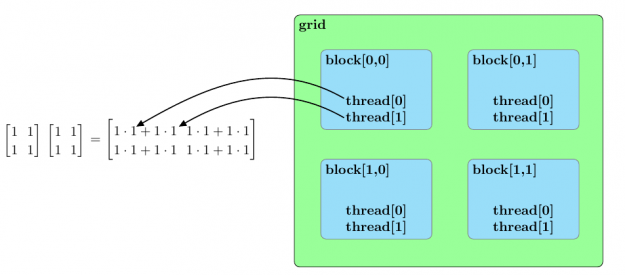
在讨论使用 CUDA 加速矩阵乘法的方法之前,我们应该大致概述 CUDA 内核的并行结构。内核启动中的所有并行进程都属于一个网格。网格由块数组组成,每个块由线程数组组成。网格中的线程组成了由 CUDA 内核启动的基本并行进程。图 2 概述了这类并行结构的示例。

既然已经详细说明了 CUDA 内核启动的并行结构,那么在 matmulcuda.py Python 脚本中用于并行化矩阵乘法的方法可以描述如下。
假设以下由一个由块的二维数组组成的 CUDA 内核网格计算,每个块由线程的一维数组组成:
- 矩阵积
此外,进一步假设如下:
- 网格 x 维中的块数 (
) 大于或等于
).
- 网格 y 维中的块数 (
) 大于或等于
(
).,
- 每个块中的线程数 (
) 大于或等于
).
矩阵积的元素
您可以通过将指定给要执行的块的每个线程来获得进一步的并行增强
为了避免竞争条件,这些atomicAdd 函数处理。 atomicAdd 函数签名由作为第一个输入的指针和作为第二个输入的数值组成。该定义将输入的数值与第一个输入所指向的值相加,然后将该和存储在第一个输入所指向的位置。
假设![[\textrm{tid}(i,j)]](https://s0.wp.com/latex.php?latex=%5B%5Ctextrm%7Btid%7D%28i%2Cj%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[[i,j]]](https://s0.wp.com/latex.php?latex=%5B%5Bi%2Cj%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[C[i,j] = \textrm{atomicAdd}(C[i,j], A[i, \textrm{tid}(i,j)] \cdot B[\textrm{tid}(i,j), j])]](https://s0.wp.com/latex.php?latex=%5BC%5Bi%2Cj%5D+%3D+%5Ctextrm%7BatomicAdd%7D%28C%5Bi%2Cj%5D%2C+A%5Bi%2C+%5Ctextrm%7Btid%7D%28i%2Cj%29%5D+%5Ccdot+B%5B%5Ctextrm%7Btid%7D%28i%2Cj%29%2C+j%5D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
图 3 总结了两个样本矩阵乘法的并行排列![[2 \times 2]](https://s0.wp.com/latex.php?latex=%5B2+%5Ctimes+2%5D&bg=ffffff&fg=000&s=0&c=20201002)
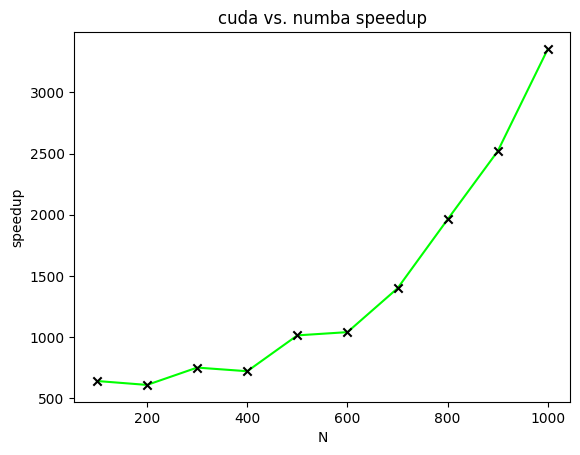
提速
图 4 显示了 CUDA 加速矩阵乘法相对于不同大小矩阵的 Numba 加速矩阵乘法的加速比。在该图中,绘制了加速比以计算两个![[N \times N]](https://s0.wp.com/latex.php?latex=%5BN+%5Ctimes+N%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[N]](https://s0.wp.com/latex.php?latex=%5BN%5D&bg=ffffff&fg=000&s=0&c=20201002)
今后的工作
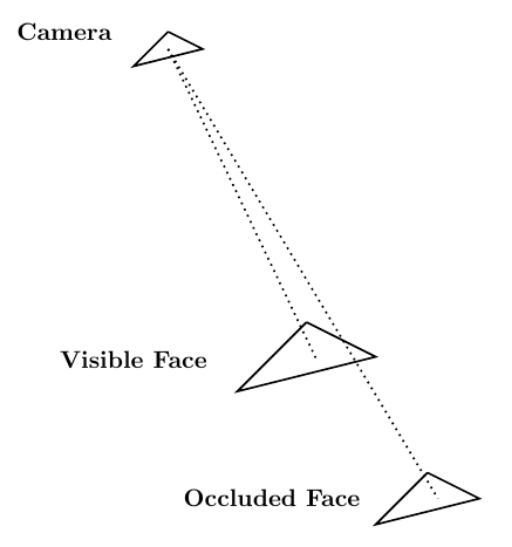
考虑到 Blender 作为计算机图形工具的作用,一个适用于 CUDA 加速的相关应用领域涉及到通过光线跟踪解决可见性问题。可见性问题可以概括如下: 相机存在于空间的某个点上,并且正在观察由三角形元素组成的网格。可见性问题的目标是确定哪些网格元素对摄影机可见,哪些网格元素被其他网格元素遮挡。
光线跟踪可以用来解决可见性问题。您试图确定其可见性的网格由
每条光线在不同的网格元素上都有一个端点。如果光线到达其端点时未被其他网格元素遮挡,则可以从摄影机中看到端点网格元素。图 5 显示了这个过程。
使用光线跟踪来解决可见性问题的本质使其成为![[\mathcal{O}(N^{2})]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BO%7D%28N%5E%7B2%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
概括
这篇文章描述了两种不同的加速矩阵乘法的方法。第一种方法使用 Numba 编译器来减少 Python 代码中与循环相关的开销。第二种方法使用 CUDA 并行化矩阵乘法。速度比较证明了 CUDA 在加速矩阵乘法方面的有效性。
因为前面描述的 CUDA 加速代码可以作为 Blender Python 脚本运行,所以可以在 Blender Python 环境中使用 CUDA 加速任意数量的算法。这大大提高了 blenderpython 作为科学计算工具的有效性。
如果您有任何问题或意见,请在下面发表意见或联系我们 info @ rendered . ai .