NVIDIA In-Game Inferencing SDK
The NVIDIA In-Game Inferencing (NVIGI) SDK offers a streamlined and high performance path to integrate locally run AI models into games and applications via in-process (C++) execution and CUDA in Graphics. NVIGI supports all major inference backends, across different hardware accelerators (GPU and CPU), so developers can take advantage of the full range of available system resources on a user’s PC.
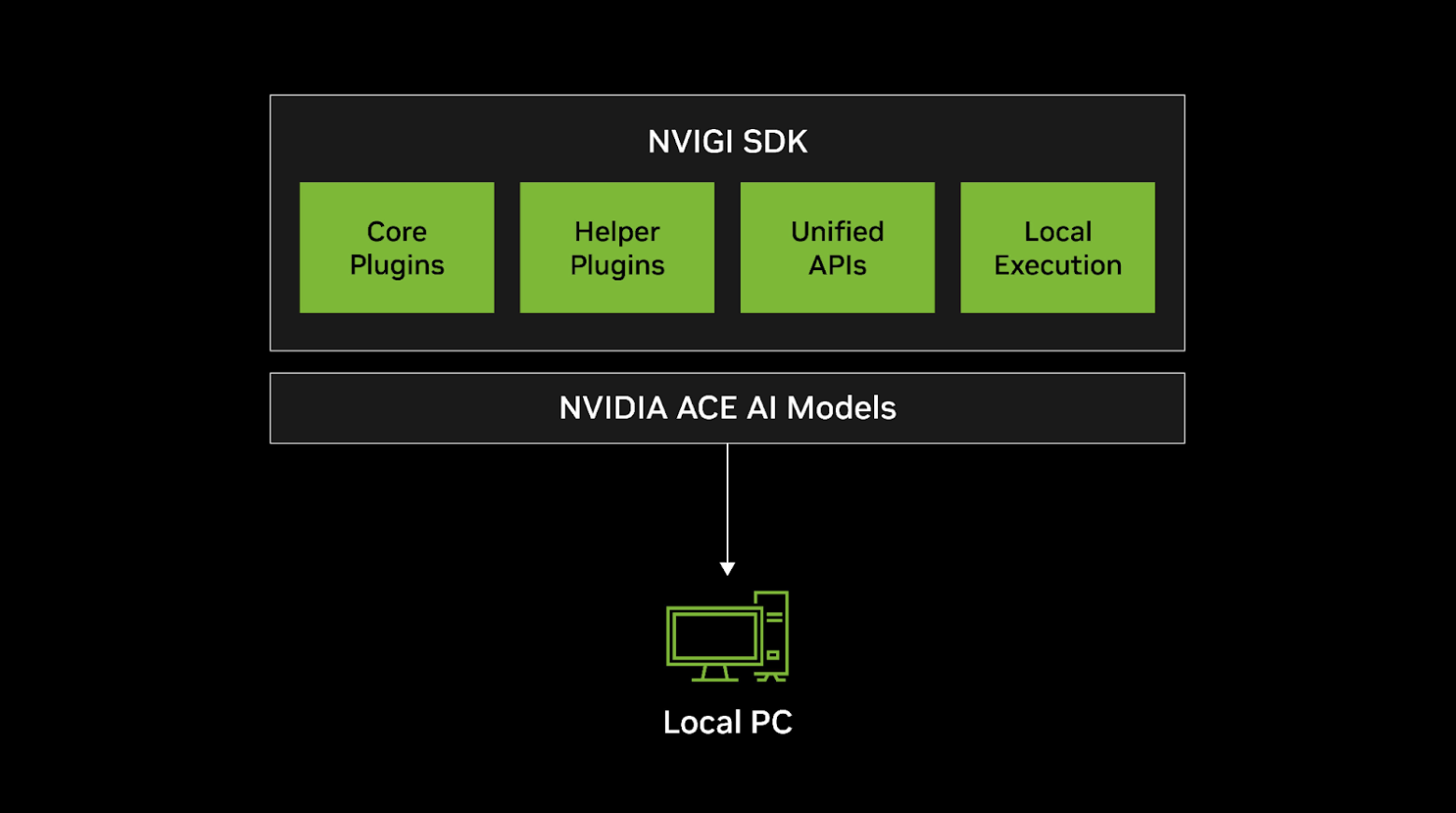
Benefits of NVIDIA In-Game Inferencing SDK
Scalable Model Support
NVIDIA In-Game Inferencing supports speech, audio, visual and language models for in-process (C++) execution.
Simplified Deployment
Load and run models built for TensorRT, ONNX Runtime, Llama.cpp or a custom executor that works across GPU and CPU via a unified inference API.
Accelerated Performance
Ensures that CUDA in Graphics (CiG) is properly set up to optimize graphics and AI execution within game pipelines, allowing them to happen simultaneously at low latency.
NVIDIA In-Game Inferencing Plugins & Model Support
The NVIDIA In-Game Inferencing SDK provides plugin support for a number of different language and speech models including:
NVIGI Plugin |
Supported Inference Hardware |
Supported Models |
|---|---|---|
Speech - ASR Local TRT |
CUDA-Enabled GPU |
|
Speech - TTS Local TRT |
CUDA-Enabled GPU |
|
|
Language - GPT Local GGML
|
CUDA-Enabled GPU or CPU
|
|
RAG - Embed Local GGML |
CUDA-Enabled GPU or CPU |
Developers can also use the open source NVIGI SDK to build their own plugins for models not listed above.
Related Products
NVIDIA ACE
NVIDIA ACE is a suite of digital human technologies that bring game characters and digital assistants to life with generative AI.

NVIDIA ACE Unreal Engine 5 Reference
Plugins and samples for Unreal Engine developers looking to bring their MetaHumans to life with generative AI on RTX PCs.
Resources
How to Successfully Integrate NVIDIA ACE for Autonomous Game Characters
This guide explores how NVIGI integrates with ACE to enable seamless AI inference in game development. It covers NVIGI’s architecture, key features, and how to get started creating autonomous characters with NVIDIA ACE on-device models.
FAQ
Find answers to frequently asked questions on NVIDIA In-Game Inferencing FAQ.
Additional Advanced Use Components
While the downloaded binary pack will suffice for most applications, NVIGI also includes some additional components for advanced development cases. The most common of these cases is NVIGI developers creating their own plugins.
Unreal Engine 5 Sample
A minimalistic code sample that shows how to integrate AI features (GPT/LLM) into an Unreal Engine 5 application.
Archive
Get started with the NVIDIA In-Game Inferencing SDK.