CUDA-X Data Science
CUDA-X™ Data Science is a collection of open-source libraries that accelerate popular data science libraries and platforms. It is part of the CUDA-X collection of highly optimized, domain-specific libraries built on CUDA®.
CUDA-X Data Science includes zero code change APIs to accelerate popular PyData tools like pandas, scikit-learn, as well as distributed computing frameworks like Apache Spark. With 100+ integrations with open-source libraries and tools in the data science and data processing ecosystem, CUDA-X Data Science democratizes access to accelerated data science.
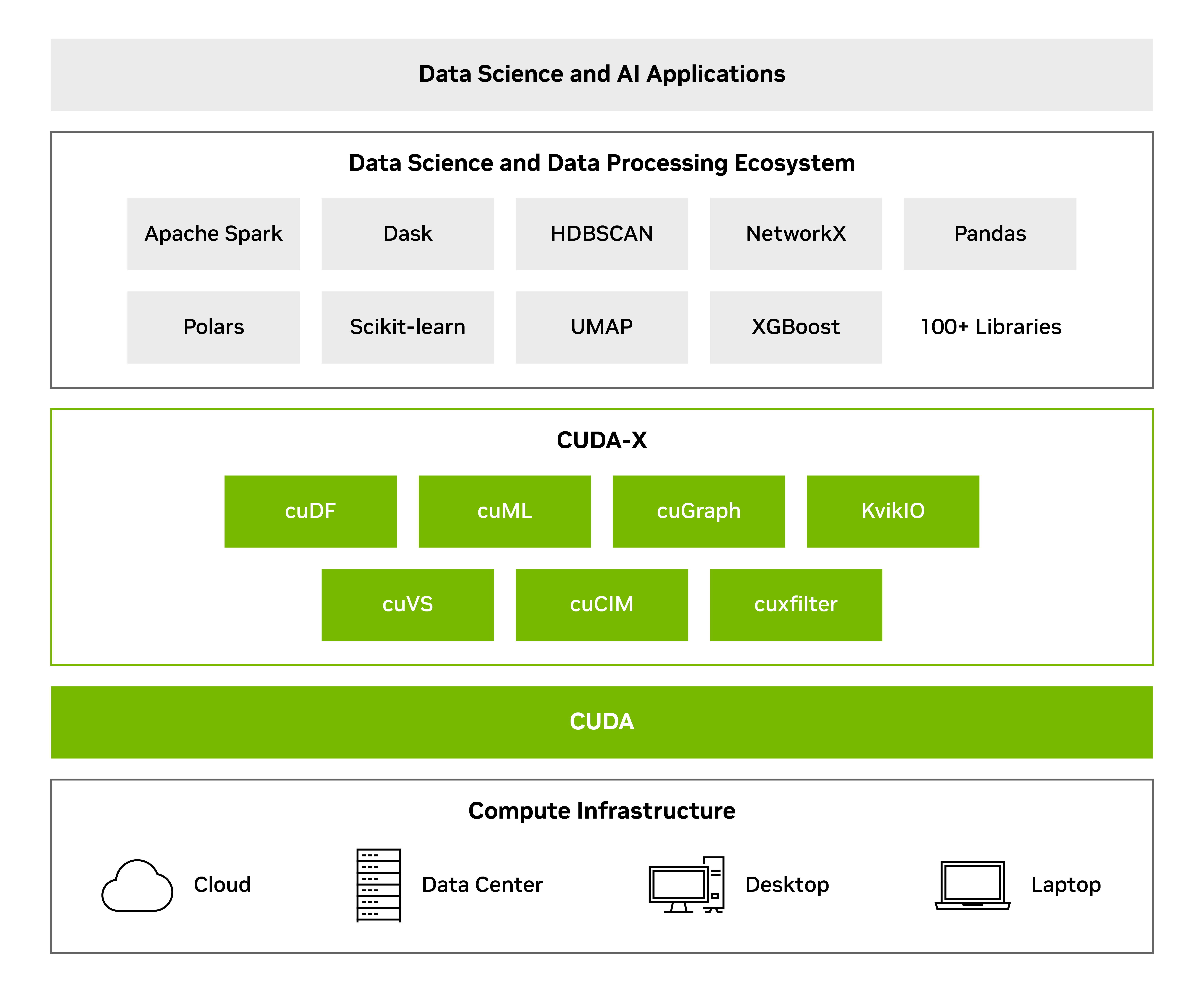
CUDA-X Data Science Libraries
Accelerate data analytics, machine learning, graphs as well as data intensive applications such as vector search to get the highest performance possible on single GPUs or scale up to distributed systems using simple zero code change interfaces.
cuDF: 50x Faster pandas
cuDF is a GPU-accelerated library that optimizes fundamental DataFrame operations. It includes drop-in accelerators for popular DataFrame tools like pandas, Polars, and Apache Spark with no code changes required.
TAGS: pandas, dataframe, Python,Cc++
cuML: 50x Faster scikit-learn
cuML is a GPU-accelerated machine learning library that optimizes machine learning algorithms for execution on GPUs. It includes accelerators that run machine learning algorithms in scikit-learn, UMAP, and HDBSCAN with no code changes required.
Run the BenchmarkView DocsInstall NowTAGS: scikit-learn, machine learning, Python, C++
cuGraph: 48x Faster NetworkX
cuGraph is a GPU-accelerated graph analytics library that optimizes graph algorithms for execution on GPUs to process millions of nodes without specialized software. It includes a zero-code-change accelerator for NetworkX.
Run the BenchmarkView DocsInstall NowTAGS: NetworkX, graph, Python, C++
Apache Spark Accelerated with cuDF
Learn more about our accelerator plug-in for Apache Spark workflows.
TAGS: machine learning, data processing, distributed computing, Scala, Python
Dask-RAPIDS
Scale out GPU-accelerated data science pipelines to multiple nodes on Dask.
Tags: distributed computing, Python
cuxfilter
Create interactive data visuals with multidimensional filtering of over 100-million-row tabular datasets.
Tags: dashboards, visualization, Python
cuCIM
Mirror scikit-image for image manipulation and OpenSlide for image loading with the cuCIM API.
Tags: computer vision, vision processing, Python
cuVS
Apply cuVS algorithms to accelerate vector search, including world-class performance from CAGRA.
TAGS: vector search, Python, C++, c, rust
RAFT
Use RAFT’s CUDA-accelerated primitives to rapidly compose analytics.
Tags: primitives, algorithms, CUDA, Python, C++
KvikIO
Take full advantage of NVIDIA® GPUDirect® Storage (GDS) through powerful bindings to cuFile.
Tags: FILEIO, GPUDirectStorage, Python, C++
Other CUDA-X Data Science and Processing Libraries
See a complete list of libraries and tools.
Get Started
Starter Kit: Accelerated Data Analytics With pandas Code
This kit demonstrates how to create responsive dashboards on large-scale data using pandas code and PyViz libraries, leveraging cuDF for accelerated exploratory data analytics with zero code changes.
Notebook: Build an Interactive Dashboard Notebook
Starter Kit: Accelerated Machine Learning on XGBoost
XGBoost is the most popular Python library for gradient boosted decision trees. It supercharges machine learning models for classification, regression and ranking workflows.
Video:
Accelerated Machine Learning with XGBoost on NVIDIA GPUs (20:10)
Starter kit: Accelerated Machine Learning With cuML Code
cuML accelerates popular machine learning algorithms, including Random Forest, UMAP, and HDBSCAN
Starter Kit: Accelerated Data Analytics With Apache Spark
The NVIDIA RAPIDS™ accelerator for Apache Spark accelerates enterprise-level data workloads to drive cost savings.
Starter Kit: Accelerated Data Analytics With Polars Code
Polars is known for its high performance and memory optimizations. Experience even faster execution when you call the GPU engine powered by cuDF.
Starter Kit: Accelerated Graph Analytics With NetworkX Code
NetworkX accelerates popular graph algorithms, including Louvain, Betweeness Centrality, and PageRank.
Notebook: Accelerated Graph Analytics Notebook
Data Science Learning Path
Get an overview of everything DLI offers for upskilling in accelerated data science.
Accelerated Data Science Workflows With Zero Code Change
Take our free self-paced course to learn how to transform your workflow with zero-code-change acceleration.
Get Certified in Accelerated Data Science
Gain a deeper understanding of accelerated data science in our certification course.
Install and Deploy in Your Environment
Quick Install With conda
1. If not installed, download and run the install script. This will install the latest miniforge:
wget "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh" bash Miniforge3-$(uname)-$(uname -m).sh
2. Then install with:
conda create -n rapids-25.06 -c rapidsai -c conda-forge -c nvidia rapids=25.06 python=3.13 cuda-version=12.9
Quick Install With pip
Install via the NVIDIA PyPI index: pip install \ --extra-index-url=https://pypi.nvidia.com \ cudf-cu12==25.6.* \ dask-cudf-cu12==25.6.* \ cuml-cu12==25.6.* \ cuGraph-cu12==25.6.*
Deploy Locally
Use this guide to install and build with conda, pip, Docker, or WSL2 on your local machine.
Deploy on Platforms
Deploy CUDA-X Data Science libraries on your platform of choice, including Kubernetes, Databricks, and Google Colab.
Deploy in the Cloud
Run CUDA-X Data Science libraries in AWS, Azure, GCP, and more.
The Accelerated Data Science Ecosystem
Data practitioners in open-source libraries, commercial software, and industries are driving innovation with CUDA-X Data Science.
AT&T applied the RAPIDS Accelerator for Apache Spark on GPU clusters in their data-to-AI pipeline.
bunq improved fraud detection accuracy by accelerating model training 100x and data processing 5x using NVIDIA CUDA-X libraries.
Read BlogCapital One accelerated their financial and credit analysis pipelines, improving model training by 100x.
Checkout.com accelerated their data analysis workflows from minutes to seconds with NVIDIA cuDF.
The IRS team uncovered fraud with the RAPIDS Accelerator for Apache Spark on the Cloudera Data Platform.
LinkedIn developed DARWIN to enable faster data analysis on NVIDIA cuDF.
NASA used CUDA-X Data Science to detect and quantify air pollution anomalies and build a bias-correction model.
PayPal reduced cloud costs by up to 70% with the RAPIDS Accelerator for Apache Spark.
Taboola, an advertising platform, processes terabytes of hourly data with the RAPIDS Accelerator for Apache Spark.
Watch On-Demand SessionTGen cut analysis time on 4 million-cell datasets from 10 hours to three minutes with RAPIDS-singlecell, built on CUDA-X Data Science.
TCS Optumera accelerated their demand forecasting pipeline with the RAPIDS Accelerator for Apache Spark.
Uber developed Horovod with support for Spark 3.x with GPU scheduling.
Watch On-Demand SessionWalmart solved scalability issues with their product-substitution algorithm.
Join the Community
Ethical AI
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting team to ensure their application meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns here.