NVIDIA cuDF: GPU-Accelerated Structured Data Processing
NVIDIA cuDF is an open source NVIDIA CUDA-X™ data processing toolkit for structured data that delivers massive speedups and cost savings for data engines and libraries. Built on highly optimized NVIDIA® CUDA® primitives, cuDF taps into GPU parallelism and memory bandwidth to accelerate data processing and analytics workflows.
How cuDF Works
cuDF provides components to GPU-accelerate query engines, including I/O and SQL operations—like joins, aggregations, sorting, and shuffles. Built on Apache Arrow’s columnar memory format, cuDF libraries dispatch highly parallel kernels across thousands of GPU cores simultaneously. Memory management tools optimize costly memory transfers between CPU and GPU.
See which data engines use cuDF today.
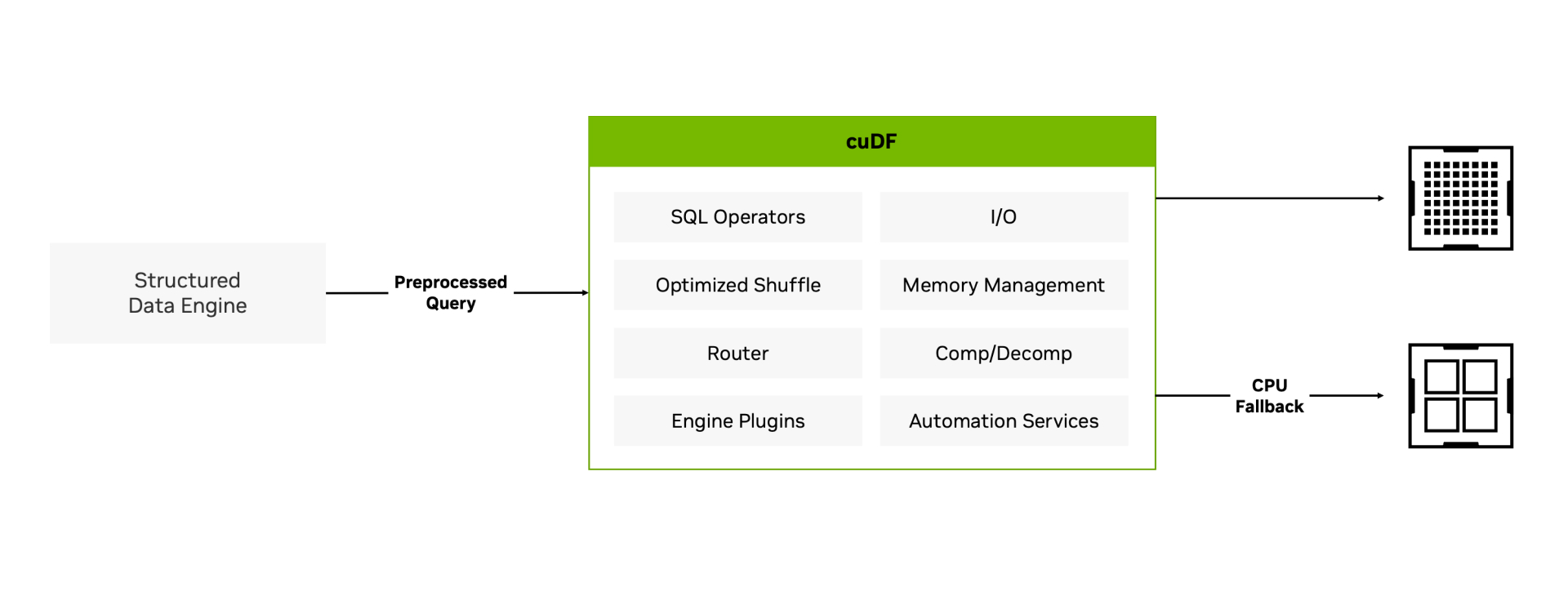
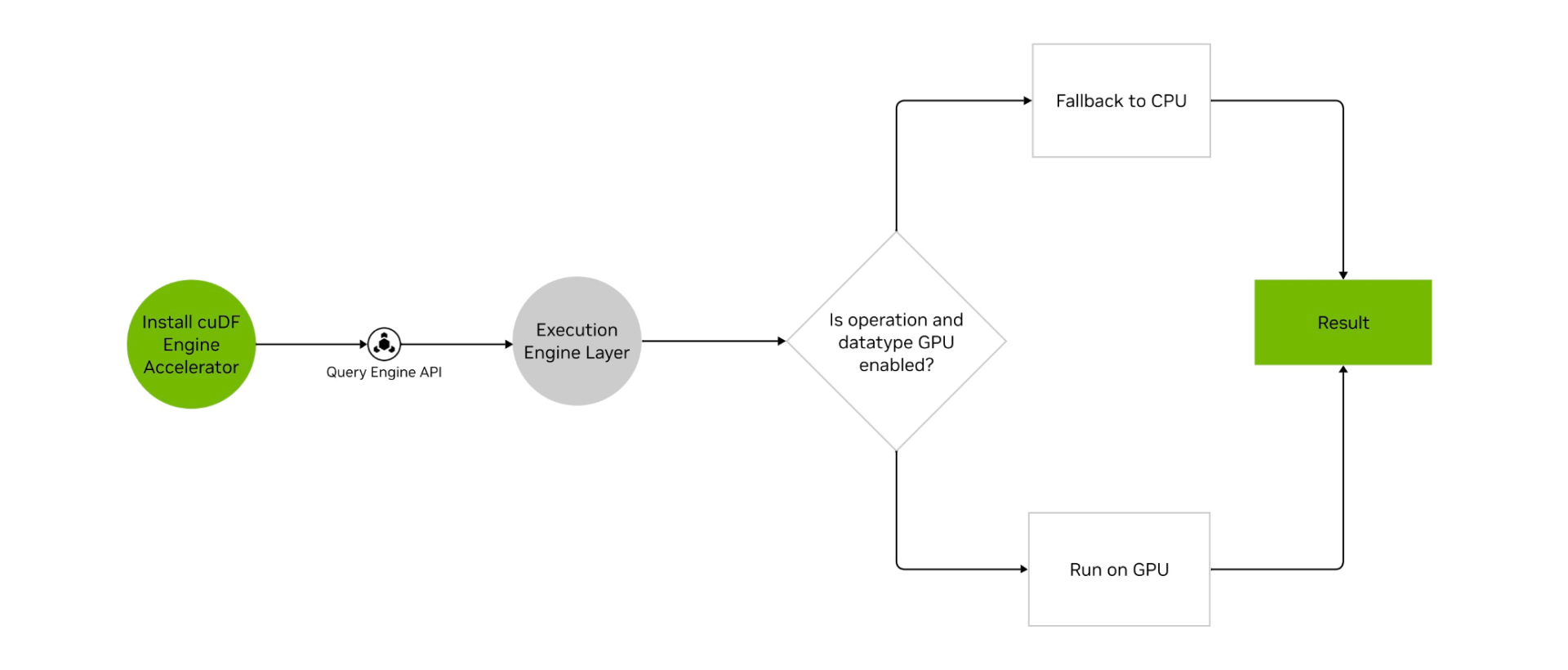
User Experience With cuDF
When cuDF is used to accelerate data engines, the user experiences GPU execution with the data engine, while the data engine helps route operations without GPU support to the CPU to ensure the user’s workflow won’t be interrupted.
Key Features
Maximize Performance With NVIDIA GPUs
cuDF maximizes performance of gigabyte- to petabyte-scale workloads by optimizing core SQL and DataFrame operations with low-level CUDA primitives that fully leverage the parallelism and memory bandwidth of NVIDIA GPUs.
Built for Latency Sensitive Workloads
With faster time to result, cuDF unblocks latency-sensitive workloads like interactive analytics and agentic AI querying to enable the next generation of data analytics.
Reduce Infrastructure Costs
By reducing runtime of data operations, workloads can process the same data volumes on far fewer nodes, cutting infrastructure costs and reducing the data center footprint.
Minimize Data Movement
Built on the Apache Arrow format, cuDF utilizes highly efficient columnar data structures and zero-copy interfaces with other accelerated libraries, minimizing data movement overhead.
Out-of-Core Scalability
With NVIDIA’s memory tools and primitives, cuDF helps accelerated engines process datasets and memory-intensive operations like joins and groupbys that exceed GPU memory.
Install and Deploy in Your Environment
To get a sense of what comes with cuDF, download the package using your preferred install method.
The package includes Python and C++ interfaces as well as zero-code-change accelerators.
Integrate cuDF directly into your environment. Follow these steps to get started.
Install cuDF
Quick Install With conda
1. If not installed, download and run the install script. This will install the latest miniforge:
wget "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh" bash Miniforge3-$(uname)-$(uname -m).sh
2. Then install with:
conda create -n rapids-26.06 -c rapidsai -c conda-forge \
cudf=26.06 python=3.14 'cuda-version>=13.0,<=13.2'Quick Install With pip
pip install \
"cudf-cu13==26.6.*"Deploy Locally
Use this guide to install and build with conda, pip, Docker, or WSL2 on your local machine.
Read the Local Deployment GuideDeploy on Platforms
Deploy CUDA-X Data Science libraries on your platform of choice, including Kubernetes, Databricks, and Google Colab.
Read the Platforms GuideDeploy in the Cloud
Run CUDA-X Data Science libraries in AWS, Azure, GCP, and more.
Read the Cloud Deployment GuideSee the complete install selector for Docker, WSL2, and individual libraries.
Install Selector
Try Accelerated Data Engines and Tools
Tool |
Ecosystem Plug-Ins |
Get Started |
|---|---|---|
Velox |
Velox on GPU (experimental) |
|
Apache Spark |
cuDF plugin for Apache Spark Drop-In Extension: spark.conf.set('spark.rapids.sql.enabled','true') |
|
Presto |
Presto-GPU |
|
Polars |
Polars GPU Engine Drop-In Extension: .collect(engine="gpu") |
|
DuckDB |
SiriusDB Drop-In Extension: LOAD 'sirius.duckdb_extension'; |
|
Pandas |
Cudf.pandas Drop-In Extension: %load_ext cudf.pandas import pandas as pd ... |
Starter Kits
Starter Kit: Build Data Engines With cuDF
Learn about cuDF’s application in large-scale data processing workloads.
GitHub: GPU Query Execution Blueprint
On-Demand GTC Session: The Era of GPU Data Processing: From SQL to Search and Back Again
On-Demand GTC Session: Shatter the Memory Wall: Composable Building Blocks for Massive Analytics
Starter Kit: Build Data Engines With Velox on GPUs up to 6x Faster
Learn how Velox, a C++ execution engine, on GPUs accelerates data engine execution for terabyte-sized workloads.
Conference Talk: Bringing GPU-Acceleration to Presto With Velox
Starter Kit: Run Apache Spark Workloads 5x Faster With 10x Cost Savings
Learn how GPUs accelerate enterprise-scale Apache Spark workflows to drive cost savings.
On-Demand GTC Workshop: Transform Enterprise and Edge Infra With NVIDIA RTX PRO™ 4500 Blackwell Server Edition
On-Demand GTC Workshop: Automate and Simplify Apache Spark Workload Migration From CPU to GPU
On-Demand GTC Session: Accelerate Big Data Analytics on GPUs With the NVIDIA RAPIDS™ Accelerator for Apache Spark (01:27:34)
User Guide: RAPIDS Accelerator for Apache Spark
Starter Kit: Run Presto on GPUs up to 6x Faster With 5x Cost Savings
The kit describes how interactive analytics engine Presto leverages Velox execution on cuDF to accelerate analytics execution.
On-Demand GTC Session: Unlock Fast, Cost-Effective Interactive Analytics on Massive Lakehouses
GitHub: Get Started With Presto
Starter Kit: Run Polars GPU Engine for up to 10x Speed Up
This kit demonstrates how the Polars GPU engine can process 100 million rows in under two seconds.
Notebook: Intro to the Polars GPU Engine
Starter Kit: Use SiriusDB to Accelerate DuckDB by up to 8x
Learn how SiriusDB, #1 on ClickBench, cost-effectively accelerates DuckDB workloads.
On-Demand GTC Session: Achieving 8x Lower Cost Analytics With GPU-Accelerated DuckDB
GitHub: SiriusDB
Academic Paper: Rethinking Analytical Processing in the GPU Era
Starter Kit: Accelerate Pandas by up to 50x
This kit gets you started with accelerating pandas on Google Colab.
Notebook: 10 Minutes to cudf.pandas
Join the Community
Ethical AI
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting team to ensure their application meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns here.