Storage Server Architecture#
With the NVIDIA Storage virtualization architecture, multiple virtual machines or HVRTOS processes can access dedicated partitions of physical storage assigned to them with out effecting other owned partitions. To share the same storage device between the different virtual machines, the storage virtualization architecture provides:
Virtual Storage Client Driver (VSCD) in the client virtual machine and client HVRTOS process for accessing storage. (The native storage driver in the virtual is disabled when storage virtualization is used.)
HVRTOS based Storage Server to manage the storage device. The storage server processes the storage access request from the client VM/HVRTOS process.
Storage Virtualization Architecture#
The storage virtualization architecture is as follows:
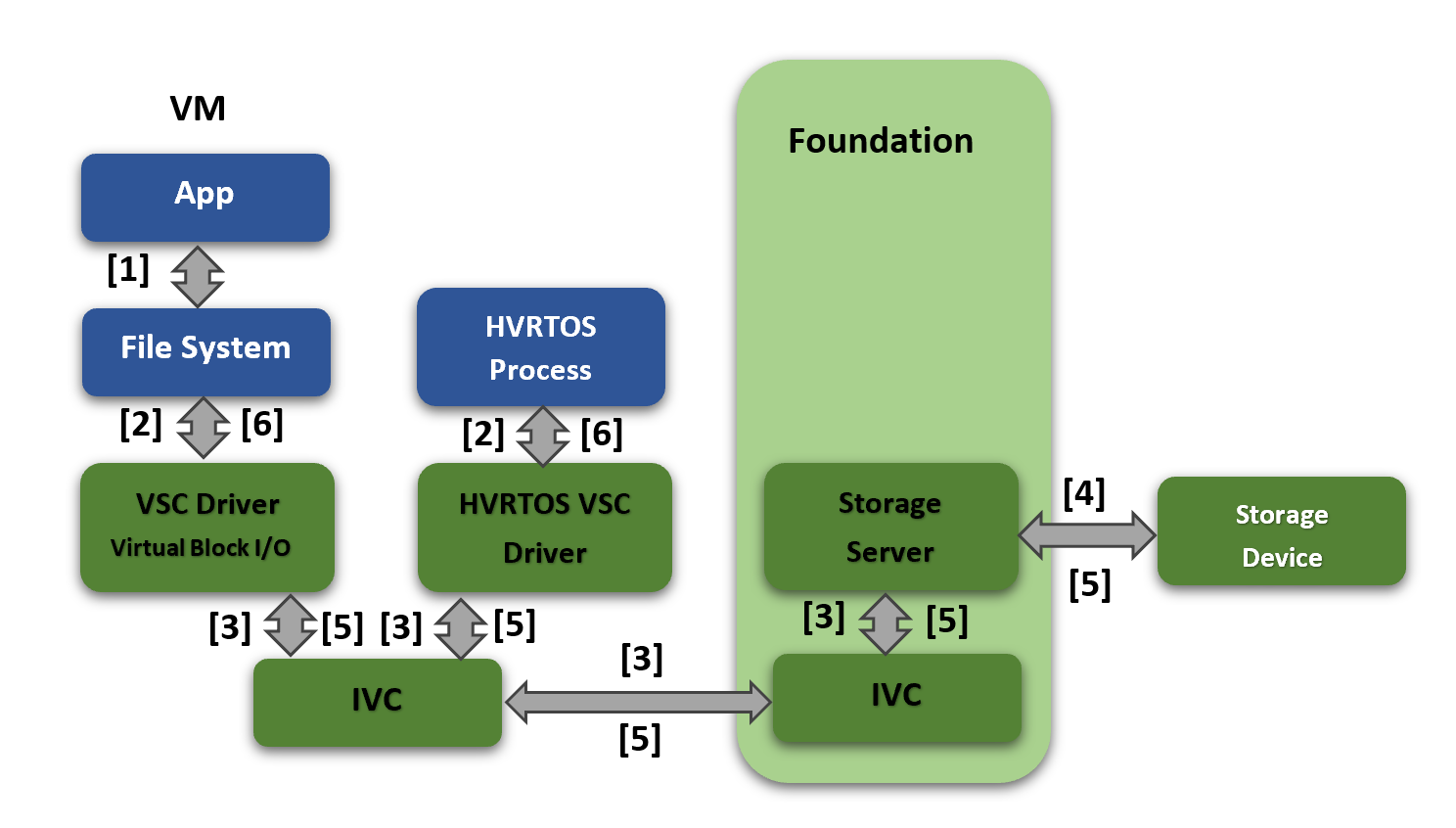
The component interactions are described below.
Step |
Interaction |
|---|---|
1 |
In case of virtual machine: The application makes a storage access request to the file system. |
2 |
In case of virtual machine: The file system sends the request to the VSCD via block layer. In case of HVRTOS Process: The HVRTOS process application sends the storage access request(via APIs) to the VSCD directly. |
3 |
The VSCD (In virtual machine or HVRTOS process) sends the storage access request to Storage server via IVC. |
4 |
Storage Server sends the request to Storage device HW and relies on interrupt for the response from HW. |
5 |
When the actual transfer from/to storage device is complete, the storage server gets the interrupt notification from HW. Storage Server further sends IVC message along with data to the VSCD (in the VM/HVRTOS process). |
6 |
In case of virtual machine: the VSCD propagates the response back to the block layer driver and further response goes to file system and the application. In case of HVRTOS process: the VSCD driver propagates the response to HVRTOS process application. |
The storage controller-supported features are as follows:
Controller |
Supported |
Not Supported |
|---|---|---|
eMMC (Only on Orin) |
Speed: HS400 |
Command Queue |
NVIDIA mnand refresh and health status |
HPI |
|
RPMB |
||
UFS |
HS-G4 |
RPMB |
SCSI commands |
Note
RPMB (replay-protected memory blocks) is not supported on eMMC or UFS storage for DriveOS 7.0. Any data that requires RPMB protection must be on the SPI-NOR device, which does support RPMB.
Virtualized Storage Device Names#
On Linux, virtualized storage is named vblkdev<id>.
mNAND Utilities Support#
The storage server allows mNAND commands to be issued by the following mNAND utilities running on any virtual machine.
Utility |
Description |
|---|---|
mnand_hs |
Displays health and status of onboard eMMC and UFS. |
mnand_rfsh |
Issues refresh commands at a controllable rate. |
For more information about the use of the mNAND utilities and options, refer to “mNAND Utilities” chapter in the NVIDIA DriveOS 7.0 SDK Developer Guide.
To run mNAND utilities on Linux virtual machine, execute:
/home/nvidia/mnand_<xxx> -d /dev/vblkdev<id>.ctl [<options>]
Where:
<xxx>represents the distinguishing part of the utility name (mnand_hs and so on).<id>identifies the virtualized storage device that you want to check.<options>is one or more command-line options (optional).
Linux Virtual Machine Access Control for Passthrough and FFU Operations#
The Linux virtual machine VSCD enumerates a separate .ctl and .ffu device node for UFS and eMMC virtual partitions that have passthrough enabled in PCT. For Example, if the virt partition - /dev/vblkdev0 has passthrough enabled in PCT then, the vblk passthrough device node for device management will be /dev/vblkdev0.ctl and the vblk passthrough device node for Field Firmware Update(FFU) will be /dev/vblkdev0.ffu.
Device management commands are only allowed if the calling process belongs to group/supplementary group “vblk-ctl”. Similarly, the FFU command is only allowed if the calling process belongs to group/supplementary group “vblk-ffu”. Refer to Virtual Storage Linux Storage Access Control for mode details. In addition to the access control mentioned previously, the VSCD checks if the calling process has the capability cap_sys_rawio. This capability can be set using either file or thread capabilities.
Overhead in CPU Utilization#
In a multi-threaded storage server, one of the threads performs all hardware transactions, such as requesting submission to and fetching responses from the hardware. This thread is called as Hardware Resource Owner (HRO). For NVIDIA DriveOS™ 7.0, the HRO role is statically assigned to one of the threads (running on PCPU2). If a request arrives on a core other than an HRO-pinned core, it is received and queued by the server thread running on that core and it signals the HRO core to submit the request further to hardware. This will cause an overhead due to additional context switches on HRO core and IPI processing, which accounts for approximately 20% additional CPU utilization in the worst case.
To mitigate this overhead for optimal CPU utilization, virtual machine VSCD processes submits the storage requests on the same core where Storage Server HRO runs (VCPU corresponding to LCPU2).
Storage Priority Scheduling and Requests Latencies#
Priority Scheduling
Storage Server does priority scheduling of requests as per the virtual storage partition priority.
In PCT storage configuration, priority is set for each virtual storage partition.
If there are multiple outstanding requests of different priority partitions, then Storage server first process the requests of high priority. Among equal priority, Storage Server does round robin scheduling of requests.
Latencies
For UFS storage access if “low priority virtual storage partition requests are already queued and after that if there are “high priority virtual storage partition” requests queued then, there can be delays in getting responses for the high priority virtual storage partition requests due to already existing low priority requests queued.
This is due to UFS device queue length has a direct impact on the initial latency for high priority virtual partitions requests. When all 32 slots of the device queue are occupied by already queued low priority virtual storage partition requests and after this if a high priority virtual storage partition request comes, then the high priority request will not be queued until at least one response for the already queued low priority request comes. It is possible that by the time the first response comes for the low priority requests, the rest of the low priority requests in the UFS device queue could have transitioned to active state(Enabled). Due to this, high priority virtual storage partition requests will be processed by device only after processing all existing queued low priority requests.
UFS device provides a way to specify hardware priorities for the queued requests. For Micron UFS, there are 3 levels of priorities supported and for Samsung UFS two levels of priorities supported. Even with these hardware priorities, if the already queued requests to the device gets transitioned to active state then they can’t be preempted to process the high priority requests.
To control the latencies for the high priority requests, a DT configuration option is provided to users to configure the UFS device queue length, so that the latency for high priority requests can be controlled.
Update the DT property below under Storage Server UFS DT node “ufshci@2500000 {” . DTS file name: . t23x-vsc-server.dts:
“nvidia,max-device-queue-len” = <1 to 32>
By default, 32 device queue length is assumed if the above DT property is not provided.
Note
If the device queue length is reduced then there is an opposite effect on the throughput. Effect on throughput drop will be more if lesser the device queue length.
Storage Throughput
For better storage throughput it is recommended to send as much as possible larger size requests from the applications.
For EMMC , the maximum size read/write request from VSCD to storage Server is 512KB.
For UFS, the maximum size read/write request from VSCD to storage Server is 4 MB
Sending smaller size requests less than above will lead to more number of requests to device, which may have negative impact on storage throughput.
Time Slice Configurations for Virtual Machine and Storage Server#
To provide best possible time slice configurations for the virtual machine and the storage server, performance measurements were done.
The following time slice values are configured after analyzing the results:
Storage server time slice
40 us for HRO Core (core on which “Hardware Resource Owner” thread runs (LCPU2))
20 us for Non-HRO Cores
VM (AV VM) time slice
On HRO core (LCPU2, where actual storage hardware transactions are handled (request submission and response handling)).
400 us - If VM is QNX
40 us - Otherwise
25 ms for all other VCPUs
The proposed time slice configurations take consideration of the tradeoff between CPU utilization and storage performance.
Increasing VM time slice (for LCPU2) impacts storage performance negatively, but guaranteeing more CPU (LCPU2) for the VM.
Reducing VM time slice (for LCPU2) has no negative impact on storage performance, but the VM LCPU2 time slice might be taken away due to some worst-case scenario. Note that, in such case, time sensitive or safety critical applications should not be run on LCPU2 core.
Note
The Priority of the storage server is set the same as that of the virtual machine.
EMMC Device Lifetime#
NAND devices have limited programand erase cycles for its blocks, after which the devices are not functional for the storage use cases. For example, EMMC devices that are part of NVIDIA DRIVE AGX Orin™ SCL have a budget of 3000 P/E cycles for MLC.
The EMMC device lifetime primarily depends on the storage use cases that define the storage access pattern. Consult storage device vendors for the initial EMMC device lifetime estimate based on the product storage use cases and evaluate if it meets the product lifetime.
Next, monitor the “average block erase counter” and “lifetime percentage” of EMMC. The “average block erase counter” indicates how many P/E cycles of EMMC are consumed out of the total P/E cycle budget (such as 3000 P/E cycles). Monitor these parameters on the target system (such as once a day) to check if the EMMC is aging out faster than intended for the lifetime. Use mNAND tools to obtain parameters.
EMMC Device Latencies#
EMMC device firmware internally completes BKOPS (background operations) for storage maintenance, such as wear leveling, garbage collection, refresh, and bad block management pushing data from SLC storage to MLC/TLC storage. BKOPS results in varying latencies when accessing the storage.
For example, for the Micron Pearl EMMC device, BKOPS delays may extend up to 500ms. In rare cases it can go to 3 or 5 seconds, but this is unusual due to power loss during instant garbage collection or bad block replacement.
Following are general guidelines to reduce the latencies. For additional assistance, consult with storage device vendors.
Avoid random writes of smaller request sizes. Instead do sequential writes
The performance will be less if more the storage area is occupied; keep storage area free as much as possible. Enable the discard option in filesystems
Use the
discardoption during filesystem mounting so that the user space Erase operation would lead to the file system sending a Discard or Erase request to the eMMC device.In Linux, the
discardoption can be added during ext4 filesystem mounting
mount –o discard –t <fs type> …
Keep at least 1GB of free space on eMMC devices to reduce garbage collection and reduce the time taken for BKOPS by the eMMC firmware.
QSPI Flash Device Information from Linux Virtual Machine#
The following information for QSPI flash device can be read from Linux virtual machine sysfs nodes.
First, find the MTD virtual storage device using the following command. QSPI flash device information can be accessed through the specific virtual storage device node.
ls -la /sys/devices/platform/tegra_virt_storage* | grep -i -C 4 mtd
#sample ouput:
ls -la /sys/devices/platform/tegra_virt_storage* | grep -i -C 4 mtd
total 0
drwxr-xr-x. 4 root root 0 Aug 12 05:22 .
drwxr-xr-x. 129 root root 0 Jan 1 1970 ..
-r--r--r--. 1 root root 4096 Aug 12 05:23 device_id
lrwxrwxrwx. 1 root root 0 Aug 12 05:23 driver -> ../../../bus/platform/drivers/Virtual MTD device
-rw-r--r--. 1 root root 4096 Aug 12 05:23 driver_override
-r--r--r--. 1 root root 4096 Aug 12 05:23 ecc_status
-r--r--r--. 1 root root 4096 Aug 12 05:23 failure_chunk_addr
-r--r--r--. 1 root root 4096 Aug 12 05:23 manufacturer_id
-r--r--r--. 1 root root 4096 Aug 12 05:23 modalias
drwxr-xr-x. 4 root root 0 Aug 12 05:22 mtd
lrwxrwxrwx. 1 root root 0 Aug 12 05:23 of_node -> ../../../firmware/devicetree/base/tegra_virt_storage40
-r--r--r--. 1 root root 4096 Aug 12 05:23 phys_base
-r--r--r--. 1 root root 4096 Aug 12 05:23 phys_dev
drwxr-xr-x. 2 root root 0 Aug 12 05:22 power
ECC Status: This node provides the current ECC status of the device. Note that after reading this node, ECC status will be cleared.
#sample ouput:
cat /sys/devices/platform/tegra_virt_storage40/ecc_status
0x0
- Following are the possible values:
0x0: No error detected.
0x1: One-bit error corrected.
0x2: Two-bit error detected (uncorrected).
0x3: ECC is disabled.
0xFFFFFFFF: ECC_REQUEST_FAILED.
Failure Chunk Address: This node provides the address of 16 byte memory chunk (of QSPI flash) that has the ECC error. It is relevant only when the sysfs node ecc_status has an error. If no error is present, it returns 0x0. The failure_chunk_address node should be read immediately after checking the syfs node ecc_status to ensure accurate information, as subsequent ECC checks clear the status and reset the failed chunk address. Note that reading this node will clear the failed chunk address value.
#sample ouput:
cat /sys/devices/platform/tegra_virt_storage40/failure_chunk_addr
0x0
Manufacturer ID: This node provides the manufacturer ID of the device, which is a unique identifier assigned by the manufacturer.
#sample ouput:
cat /sys/devices/platform/tegra_virt_storage40/manufacturer_id
0xc2
Device ID: This node provides the device ID, which is a unique identifier for the specific model of the device.
#sample ouput:
cat /sys/devices/platform/tegra_virt_storage40/device_id
0x95
QSPI Device Size: This node provides the total size of the QSPI flash device in bytes.
#sample ouput:
cat /sys/devices/platform/tegra_virt_storage40/qspi_device_size_bytes
67108864
UFS Multi-LUN Support#
Storage virtualization supports I/O operations from virtual partitions belonging to multiple User LUNs. The User LUN type can be Normal(TLC) or Enhanced Memory(EM1 SLC). This is verified with one SLC User LUN and one TLC User LUN. Support, therefore, is for one SLC User LUN and one TLC User LUN.
Functional Constraints#
The storage server imposes the following constraints on users and system integrators:
Its assumed that users will perform integrity checks on the storage data to verify accuracy of the data.
Its assumed that users of storage will implement mechanisms, such as timeout, to monitor forward progress if required.
It is assumed that NVIDIA DriveOS will go through a graceful shutdown sequence, which sends a shutdown notification to the storage server. In the case of an abrupt shutdown, the data in storage device caches could be lost, resulting in some storage device writes not being persistent.
The storage server should have a graceful shutdown each time, and any failure in this regard might result in storage device initialization taking longer during the next boot cycle and impacting boot KPIs.
The storage server completes a majority of its processing on LCPU-2. For DriveOS use cases, LCPU-2 CPU BW availability needs to be evaluated for its impact.
For optimal storage throughput, always en-queue large-size requests as much as possible.
The storage server supports UFS device queueing for the requests. UFS device queue length has a direct impact on the initial latency for high-priority virtual partitions. When all 32 slots of the device queue are occupied by low-priority requests and a high priority request comes, the high-priority request will not be queued until at least one response for the already queued low priority request comes. By the time the first response arrives for the low priority requests, the rest of the low priority requests in the UFS device queue could have transitioned to an active state (Enabled). If storage use cases have strict latency requirements, configure the device queue length (provided as a DT property) to the optimum value after considering the tradeoff between latency and throughput. If the device queue length is reduced, then there will be a negative effect on throughput.
It is the responsibility of the system integrator to tune the virtual storage partitions priority to meet the latency and bandwidth needs of the system.
Depending on the virtual storage partitions priorities, if high-priority virtual storage partitions continuously consume the storage bandwidth, low-priority virtual storage partition requests may potentially be starved. This is because of storage priority-based scheduling, in which high-priority requests are processed before low priority requests. Storage users should consider this for accessing the storage.
DriveOS users may schedule the storage access so that low-priority storage user requests may not timeout due to high-priority storage requests
Low-priority storage access can be retried on timing out, or set the timeout based on the priority. The VSCD provides a configurability option to set the timeout via DT.
For SDMMC and UFS, performance varies based on the amount of the storage occupied in the storage device. Consult with storage vendors for additional information.
UFS Stream ID(ufs_stream_id) PCT attribute should be configured for all the UFS virtual partitions in PCT storage configuration. The POR is to use the ufs_stream_id for the UFS storage partitions, so that additional memory copy can be avoided. Storage Server doesn’t support UFS partitions configurations with out ufs_stream_id, as this is not verified.
Storage Server does priority scheduling of requests which arrives only on LCPU-2. For multi virtual machines, all virtual machines will not have the LCPU2 mapped. So, For multi virtual machine use cases LCPU2 based priority scheduling is not supported.
For UFS, VSCD maps multiple erase types like DISCARD and SECURE ERASE to single erase type(DISCARD or ERASE or SECURE ERASE) that is currently provisioned.