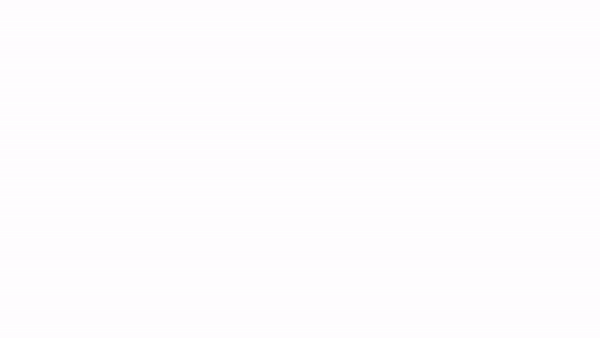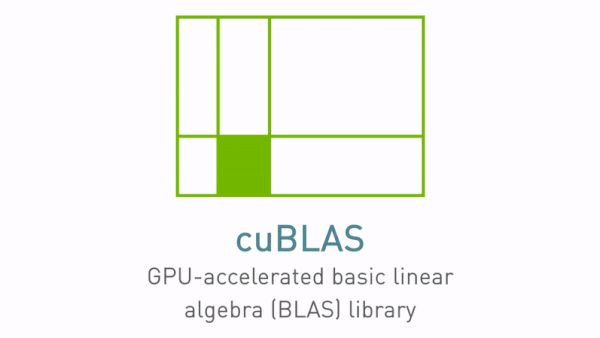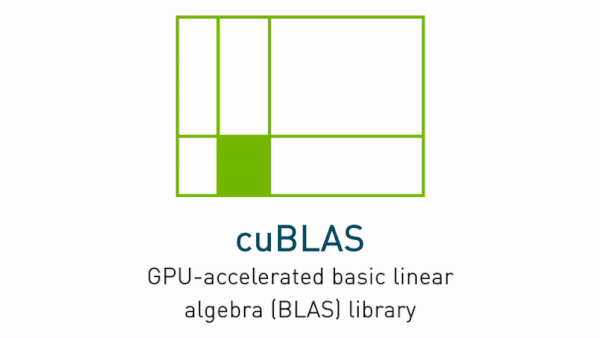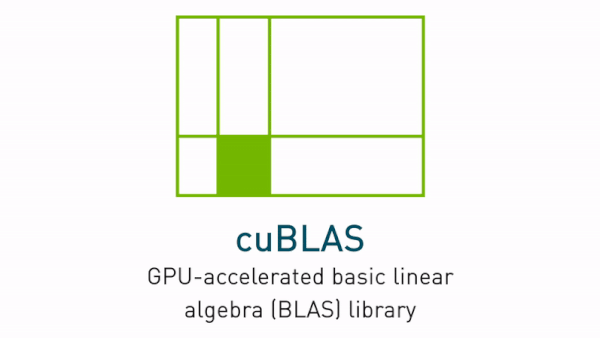NVIDIA Blackwell Tops MLPerf Training 6.0 with Industry-Leading Scale and Performance
NVIDIA delivered a clean sweep in MLPerf Training v6.0, the latest edition of industry-standard AI training benchmarks developed by the MLCommons consortium....
CUDA 13.2 Introduces Enhanced CUDA Tile Support and New Python Features
CUDA 13.2 arrives with a major update: NVIDIA CUDA Tile is now supported on devices of compute capability 8.X architectures (NVIDIA Ampere and NVIDIA Ada), as...
NVIDIA CUDA 13.1 Powers Next-Gen GPU Programming with NVIDIA CUDA Tile and Performance Gains
NVIDIA CUDA 13.1 introduces the largest and most comprehensive update to the CUDA platform since it was invented two decades ago. In this release, you’ll...
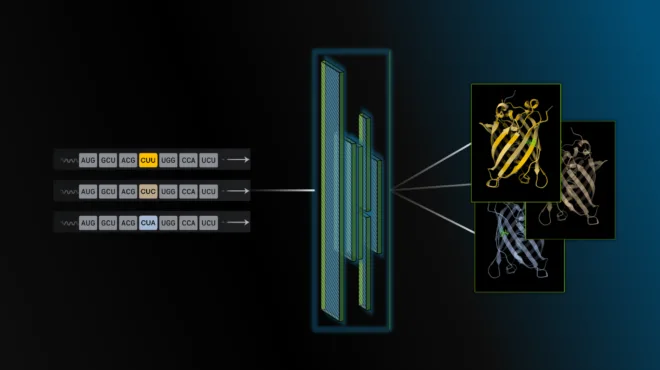
Introducing the CodonFM Open Model for RNA Design and Analysis
Open research is critical for driving innovation, and many breakthroughs in AI and science are achieved through open collaboration. In the field of digital...
Unlocking Tensor Core Performance with Floating Point Emulation in cuBLAS
NVIDIA CUDA-X math libraries provide the fundamental numerical building blocks that enable developers to deploy accelerated applications across multiple...
NVIDIA Blackwell Delivers up to 2.6x Higher Performance in MLPerf Training v5.0
The journey to create a state-of-the-art large language model (LLM) begins with a process called pretraining. Pretraining a state-of-the-art model is...
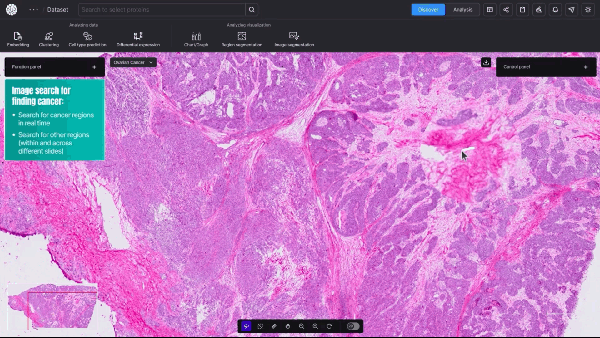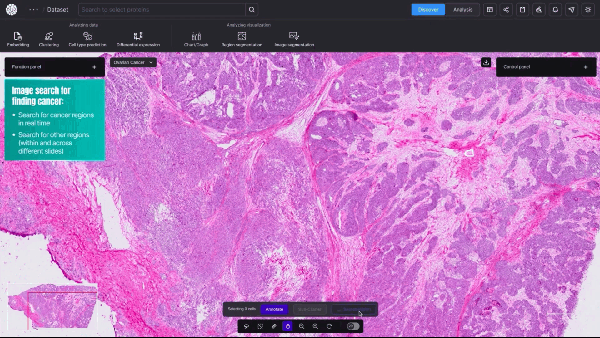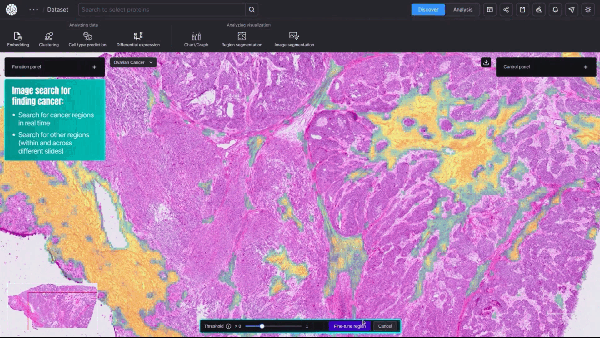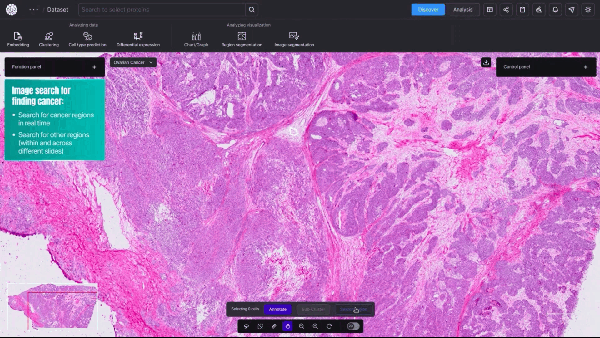
New AI Model Offers Cellular-Level View of Cancerous Tumors
Researchers studying cancer unveiled a new AI model that provides cellular-level mapping and visualizations of cancer cells, which scientists hope can shed...
With the latest release of Warp 1.5.0, developers now have access to new tile-based programming primitives in Python. Leveraging cuBLASDx and cuFFTDx, these...
Fusing Epilog Operations with Matrix Multiplication Using nvmath-python
nvmath-python (Beta) is an open-source Python library, providing Python programmers with access to high-performance mathematical operations from NVIDIA CUDA-X...
The release supports GB100 capabilities and new library enhancements to cuBLAS, cuFFT, cuSOLVER, cuSPARSE, as well as the release of Nsight Compute 2024.3.
Introducing Grouped GEMM APIs in cuBLAS and More Performance Updates
The latest release of NVIDIA cuBLAS library, version 12.5, continues to deliver functionality and performance to deep learning (DL) and high-performance...
cuBLASDx allows you to perform BLAS calculations inside your CUDA kernel, improving the performance of your application. Available to download in Preview...
cuBLASMp is a high-performance, multi-process, GPU-accelerated library for distributed basic dense linear algebra. It is available to download in Preview now.