NVIDIA 中国开发者日活动 中国・苏州 | 2025 年 11 月 14 日
了解详情
DEVELOPER
首页
博客
论坛
论坛 (英文)
文档
下载
培训
Search
加入
数据科学
2025年 10月 14日
借助 NVIDIA Parabricks 提高变体识别准确性
NVIDIA Parabricks 是一款专为数据科学家和生物信息学家设计的可扩展基因组学软件套件,专注于基因数据的二级分析。
3 MIN READ
借助 NVIDIA Parabricks 提高变体识别准确性
2025年 9月 25日
使用 CUDA-X 数据科学加速 GPU 模型训练的方法
在之前关于 AI 在制造和运营中应用的博文中,我们探讨了供应链所面临的独特数据挑战,并介绍了智能特征工程如何显著提升模型性能。
2 MIN READ
使用 CUDA-X 数据科学加速 GPU 模型训练的方法
2025年 9月 23日
如何使用 GPU 驱动的 Leiden 在 Python 中加速社区检测
社区检测算法通过识别网络中隐藏的关联实体组,在理解数据方面发挥着重要作用。社交网络分析、推荐系统、GraphRAG、
3 MIN READ
如何使用 GPU 驱动的 Leiden 在 Python 中加速社区检测
2025年 9月 23日
借助 NVIDIA NeMo 在 FP8 精度下提高训练吞吐量
在之前关于 FP8 训练的博文中,我们探讨了 FP8 精度的基础知识 并深入分析了适用于大规模深度学习的 多种扩展方法。
3 MIN READ
借助 NVIDIA NeMo 在 FP8 精度下提高训练吞吐量
2025年 9月 18日
Kaggle 大师级玩家手册:7 种实战验证的表格数据建模技术
在数百场 Kaggle 比赛中,我们不断优化了这套 BLUEPRINT,无论面对的是数百万行数据、缺失值,还是与训练数据截然不同的测试集,
3 MIN READ
Kaggle 大师级玩家手册:7 种实战验证的表格数据建模技术
2025年 9月 17日
NVIDIA RAPIDS 25.08 版本新增 cuML 分析器、Polars GPU 引擎更新、增加算法支持及更多功能
RAPIDS 25.08 版本持续突破极限,新增多项功能,进一步提升了加速数据科学的易用性和可扩展性,包括: 请在下方详细了解新增功能。
3 MIN READ
NVIDIA RAPIDS 25.08 版本新增 cuML 分析器、Polars GPU 引擎更新、增加算法支持及更多功能
2025年 9月 10日
借助 NVIDIA RTX PRO Blackwell 服务器版本,将蛋白质结构推理速度提高 100 多倍
了解蛋白质结构的研究比以往任何时候都更加重要。从加快药物研发到为未来可能的疫情做好准备,
2 MIN READ
借助 NVIDIA RTX PRO Blackwell 服务器版本,将蛋白质结构推理速度提高 100 多倍
2025年 8月 22日
如何发现 (并修复) pandas 工作流中的 5 个常见性能瓶颈
数据加载缓慢、内存消耗大的连接操作以及长时间运行的任务,是每位 Python 开发者都会面临的问题。它们不仅浪费了宝贵的时间,
2 MIN READ
如何发现 (并修复) pandas 工作流中的 5 个常见性能瓶颈
2025年 8月 13日
使用 ProRL v2 通过长时间训练扩展 LLM 强化学习
目前,AI 领域最引人注目的问题之一是大型语言模型 (LLM) 是否可以通过持续强化学习 (RL) 继续改进,或者其能力是否最终会达到顶峰。
4 MIN READ
使用 ProRL v2 通过长时间训练扩展 LLM 强化学习
2025年 8月 7日
在单个 NVIDIA Grace Hopper 超级芯片上使用 XGBoost 3.0 训练 TB 级数据集
梯度提升决策树 (GBDT) 驱动着从实时欺诈过滤到 PB 级需求预测的各种功能。由于其先进的准确性、
2 MIN READ
在单个 NVIDIA Grace Hopper 超级芯片上使用 XGBoost 3.0 训练 TB 级数据集
2025年 8月 7日
使用 JIT 编译在 cuDF 中高效转换
RAPIDS cuDF 提供了一系列用于使用 GPU 处理数据的 ETL 算法。对于 pandas 用户,
3 MIN READ
使用 JIT 编译在 cuDF 中高效转换
2025年 8月 6日
CUDA 工具包 13.0 的新特性和重要更新
CUDA Toolkit 13.0 是该工具包的最新版本,具有加速最新 NVIDIA CPU 和 GPU 计算的优势。作为一项重大发布,
4 MIN READ
CUDA 工具包 13.0 的新特性和重要更新
2025年 8月 1日
7 种可即时加速 Python 数据科学工作流程的插入式替代方案
您已经经历过。您编写了完美的 Python 脚本,在示例 CSV 上对其进行了测试,一切都很完美。但是,
2 MIN READ
7 种可即时加速 Python 数据科学工作流程的插入式替代方案
2025年 7月 24日
借助 NVIDIA cuVS 优化索引和实时检索的向量搜索
AI 赋能的搜索需要高性能索引、低延迟检索和无缝可扩展性。NVIDIA cuVS 为开发者和数据科学家带来了 GPU…
2 MIN READ
借助 NVIDIA cuVS 优化索引和实时检索的向量搜索
2025年 7月 23日
在 Azure 上使用 Apache Spark 和 NVIDIA AI 进行无服务器分布式数据处理
将大量文本库转换为数字表示 (称为嵌入) 的过程对于生成式 AI 至关重要。从语义搜索和推荐引擎到检索增强生成 (RAG) ,
2 MIN READ
在 Azure 上使用 Apache Spark 和 NVIDIA AI 进行无服务器分布式数据处理
2025年 7月 18日
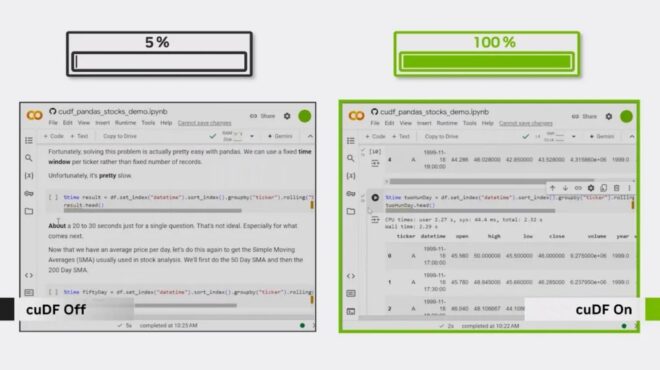
3 个 pandas 工作流在大型数据集上严重变慢,直到启用了 GPU 加速
如果您使用 pandas,您可能已经撞到了墙壁。正是在这个时刻,您值得信赖的工作流程在处理较小的数据集时表现出色,在处理大型数据集时陷入停顿。
1 MIN READ
3 个 pandas 工作流在大型数据集上严重变慢,直到启用了 GPU 加速
加载更多