NVIDIA CUDA-Q
NVIDIA CUDA-Q™ is the quantum processing unit (QPU)-agnostic platform for accelerated quantum supercomputing.
How CUDA-Q Works
CUDA-Q is an open-source quantum development platform that orchestrates the hardware and software needed to run useful, large-scale quantum computing applications. The platform’s hybrid programming model allows computation on GPU, CPU, and QPU resources in tandem from within a single quantum program. CUDA-Q is “qubit-agnostic”—seamlessly integrating with all QPUs and qubit modalities and offering GPU-accelerated simulations when adequate quantum hardware isn’t available.
CUDA-Q extends far beyond the NISQ-era, charting a course to large-scale, error-corrected quantum supercomputing with libraries, tools, infrastructure, and a hybrid programming model built for the future of quantum computing. Under the hood, CUDA-Q can be interchangeably powered by industry-leading simulators or actual quantum processors from a growing list of vendors. Both of these engines can leverage AI supercomputing, whether to GPU-accelerate simulations or control and enhance QPU operations.

Key Features
Simplify Development of Hybrid Quantum-Classical Applications
The kernel-based programming model makes it easy to write a hybrid application once and run it on multiple QPU and simulation backends.
Run Quantum Simulations at Scale
Powerful state vector, tensor networks, and noisy simulators can accelerate your applications with GPUs.
Simulate Quantum Systems
Accelerated simulation of the time evolution of dynamic systems, noise modeling, and quantum error correction (QEC) tools allow QPU builders to design fault-tolerant systems.
Write Once, Run Everywhere
CUDA-Q is QPU agnostic and integrates with 75% of publicly available QPUs. Write your code once and run on all qubit modalities.
Use Familiar Tools
Use Python or C++ to describe your algorithm in a high-level language. The CUDA-Q compiler will lower and optimize the code based on the backend, using industry tools such as Multi-Level Intermediate Representation (MLIR), Low Level Virtual Machine (LLVM), and Quantum Intermediate Representation (QIR).
Be Part of the Community
CUDA-Q is an open-source project and is part of the quantum community. It interops with AI and high-performance computing (HPC) libraries and visualization tools.
Built for Performance
NVIDIA CUDA-Q enables the straightforward execution of hybrid code on many different types of quantum processors, simulated or physical. Researchers can use the cuQuantum-accelerated simulation backends or QPUs from our partners or connect their own simulator or quantum processor.
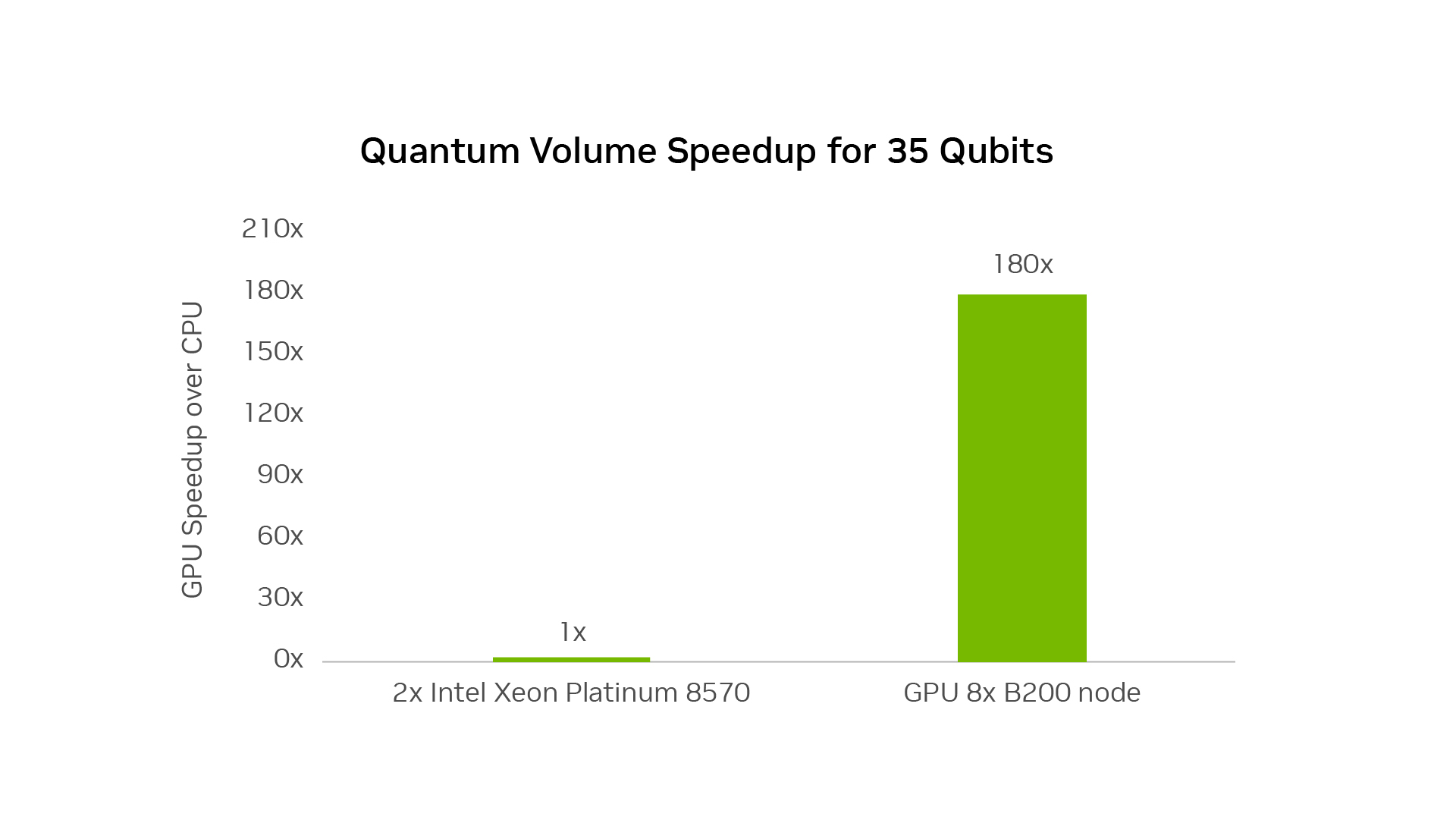
GPU Advantage
CUDA-Q quantum algorithm simulations can achieve a speedup of up to 180x over a leading CPU, as well as scaling of the number of qubits with low overhead in GPU time.
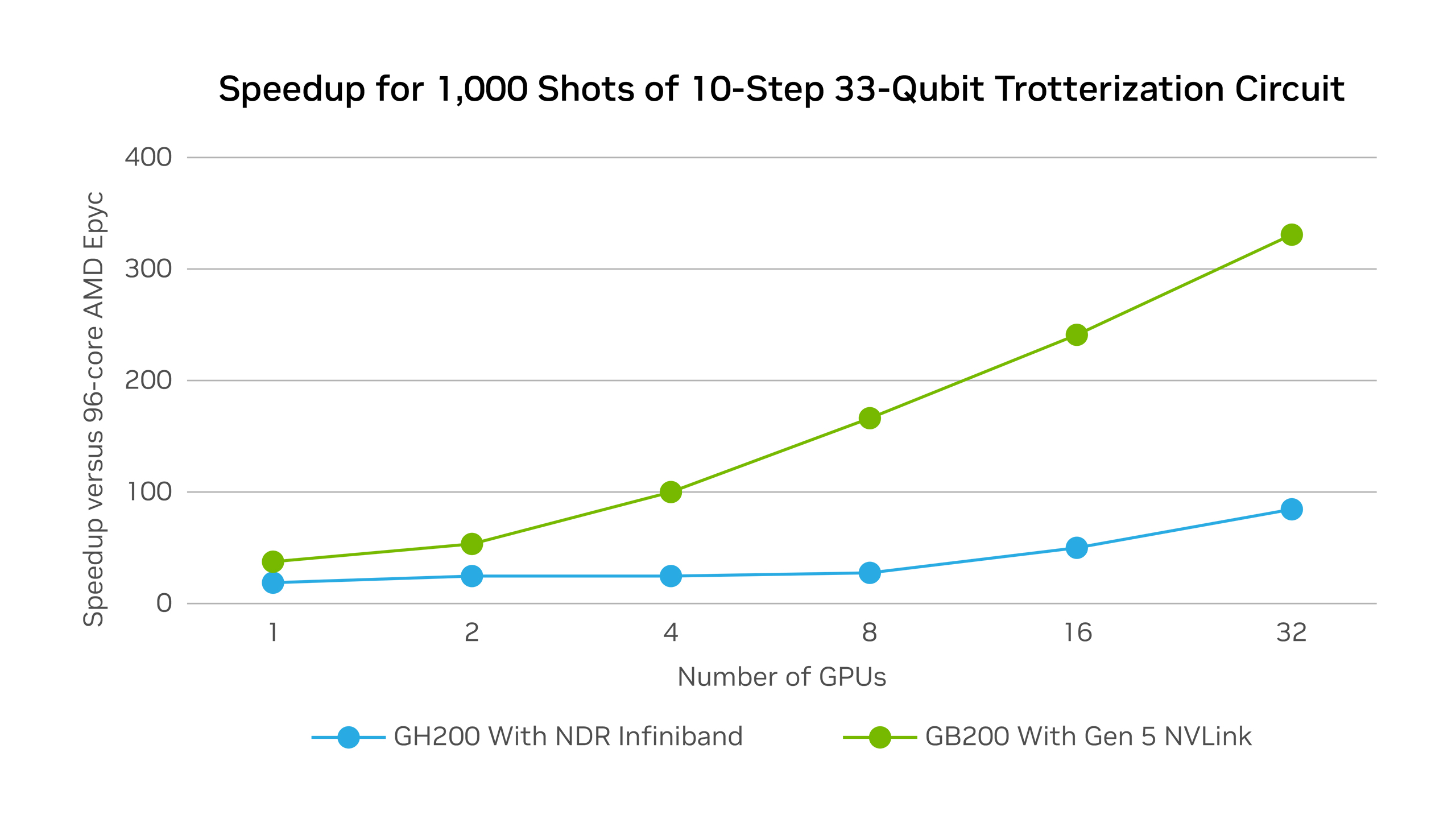
Multiple GPU Scaling
Multiple GPUs can scale the performance of quantum algorithm simulations by more than 300x.
Starter Kits
Optimization
Understand and solve the Max-Cut optimization problem with the Quantum Approximate Optimization Algorithm (QAOA).
Learn about CUDA-Q optimizers and use the observe function.
Quantum Error Correction
Learn how to do quantum error correction with CUDA-Q.
Dynamic Simulation
Learn about the dynamics capabilities in CUDA-Q.
Use Cases
Fault-Tolerant Qubits
Infleqtion demonstrated error-corrected, logical qubits using neutral atoms.
AI for Algorithm Design
The University of Toronto developed the Generative Quantum Eigensolver—a new class of quantum algorithms that uses AI to improve performance.
Solar Energy Prediction
The Chung Yuan Christian University developed a quantum neural network model for solar irradiance forecasting, showing faster training and improved performance.
Divisive Clustering
The University of Edinburgh developed a method of finding data patterns and clustering big data so it can be used in quantum computers.
Molecular Generation
Yale University developed a hybrid transformer with a quantized self-attention mechanism applied to molecular generation.
Circuit Synthesis
The University of Innsbruck used diffusion models to synthesize arbitrary unitaries into CUDA-Q kernels.
CUDA-Q Learning Resources
CUDA-Q Documentation
Browse documentation for the latest version of CUDA-Q.
CUDA-Q Application Hub
Run Python notebooks of real-life applications showing the power of CUDA-Q.
CUDA-Q Repo
Visit the CUDA-Q GitHub repository to contribute code and create issues.
CUDA-QX Libraries
Explore domain-specific CUDA-Q libraries for QEC and solvers.
CUDA-Q Academic
Explore CUDA-Q Academic materials, including self-paced Jupyter notebook modules for building and optimizing hybrid quantum-classical algorithms using CUDA-Q.
Quick-Start to Accelerated Quantum Supercomputing
Watch a hands-on session and explore the code to learn how to use CUDA-Q to bring together quantum algorithms with machine learning and generative AI to elevate quantum computing.
Latest CUDA-Q News
CUDA-Q Ecosystem
CUDA-Q is accelerating work across the quantum computing ecosystem, including partner integrations that range from building and controlling better quantum hardware to developing the first useful quantum algorithms.