PC GPU Performance Hot Spots
Introduction
Game developers shipping titles for PC and consoles are faced with many interesting rendering optimization challenges. The GPU cost of techniques like tile-based lighting or the CPU cost of the rendering API are going to impact performance very differently based on which platform is being used.
As a member of the Developer Technology (Devtech) team at NVIDIA I’m working closely with game developers to help them optimize their titles for PCs. Before joining Devtech I’ve worked for several game studios and shipped a number of PC and console games. This has given me some insight into the great variation of performance optimizations applicable to each platform.
In this article I’ll be giving a select overview of some of the most impactful performance optimizations and considerations I’m frequently encountering when analyzing PC games. I won’t be diving deep into each topic; instead each section is meant to be a starting point and I’ll be providing references to existing material which will go into much more detail.
Table of Contents
- Introduction
- Table of contents
- Tile-based lighting and structured buffers
- Constant buffer updates
- Frametime spikes
- Measuring spikes
- Hardware variability
- Memory overcommitment
- Texture and buffer creation
- Shader creation
- DirectX 12
- SLI Performance Considerations
- Conclusion
Tile-based lighting and structured buffers
Tile-based lighting techniques such as Tiled Deferred Shading and Tiled Forward Lighting are some of the most commonly used techniques in modern games to accumulate large amounts of light sources. Lighting is often the most expensive pass in the frame so it is an obvious target for optimizations.
The light sources affecting the scene usually change every frame as lights are moved, animated and culled. To feed a tiled lighting shader with light source information, a single structured buffer is commonly used. The buffer contains a light structure similar to the following:
struct Light
{
float3 Position;
float Radius;
float4 Color;
float3 AttenuationParams;
}; // 352 bits
StructuredBuffer LightBuf;
The above setup is straightforward and will work for reading from on the GPU but this particular example is leaving performance on the table.
Structured buffer alignment
First of all, most GPUs prefer to read from aligned structures. Just like on the CPU, aligning a structure to a certain stride will result in improved read performance. One typical reason for this performance gain is cache alignment. In general, aligning structures in structured buffers to 128-bits will result in much more efficient reads. If no fields can be moved around, added, or removed, you could consider simply padding the structure:
struct Light
{
float3 Position;
float Radius;
float4 Color;
float3 AttenuationParams;
float pad0;
}; // 384 bits, 3x128
Aligning structured buffers to 128-bit structure sizes is an important performance optimization which should be considered for all structured buffers. This simple change can result in large (in one notable case 5%) whole-frame performance gains.
Aligning the struct members to 128-bits can also improve read performance for the same reasons. So it’s a good idea to place members larger than 32 bits at 128-bit intervals. Padding the struct may also be required here.
struct LightBad
{
float4 Position; // 128 bits
float Radius; // 32 bits
float3 AttenuationParams; // Not 128-bit aligned!
};
struct LightGood
{
float4 Position;
float3 AttenuationParams; // 128-bit aligned
float Radius;
};
Constant buffer performance
On NVIDIA hardware (up to and including our recently released Pascal architecture), a second optimization can improve performance further: Converting the structured buffer to a constant buffer. Note, however, that this only makes sense when the data is accessed coherently! This is the case when all threads in the warp access the same lights, which is fortunately common in the shading stage of tile-based lighting shaders. The constant buffer solution can be declared in the shader like so:
cbuffer LightCBuf
{
Light LightBuf[MAX_LIGHTS];
};
This will be more efficient to access than an aligned structured buffer, which in turn will be more efficient than an unaligned buffer. Again, this is only a useful optimization when the data is accessed coherently. When different threads within the warp access different lights, a structured buffer is still preferred. Because the culling phase of tiled lighting is often divergent (each thread culls a different set of lights), consider supplying the tiled lighting passes with both a structured buffer and a constant buffer for optimal performance of each pass.
As an aside: The performance penalty for incoherently accessing data in constant buffers holds true even in other situations. For example, accessing skinning matrices in the vertex shader using constant buffers carries this penalty. In this case you may also consider storing the skinning matrices in 128-bit aligned structured buffers for optimal incoherent read access.
For more information on this important topic please see the series of articles by Evan Hart on which this fragment is based:
- https://developer.nvidia.com/content/understanding-structured-buffer-performance
- https://developer.nvidia.com/content/redundancy-and-latency-structured-buffer-use
- https://developer.nvidia.com/content/how-about-constant-buffers
Constant buffer updates
One of the well-known contributors to CPU load in DirectX 11 is updating constant buffers per-draw call. These buffers typically contain per-draw constants such as world (+view+projection) matrices which are unique per object and often change every frame. Unfortunately updating these buffers for each draw call is a time-consuming CPU operation, and there are limits on how frequently you can update the same buffer before incurring extra performance penalties. So in DX11, our advice is to minimize the number of updates made to constant buffers in between draw calls whenever possible.
DirectX 11.1 and DirectX 12 alleviate this problem by allowing you to update constant buffers for multiple draws and binding with an offset before each Draw. In DX 11.1 this is accomplished using PSSetConstantConstantBuffers1. The CPU time saved by removing the per-draw Map/Unmap calls may allow for an order of magnitude more draw calls before becoming CPU-limited. This feature alone is a compelling reason to support DX11.1 in your application.
For all the details on DirectX 11 and 11.1 constant buffer updates please see Holger Gruen’s article on the subject: https://developer.nvidia.com/content/constant-buffers-without-constant-pain-0
Frametime spikes
While average frame time is the most commonly investigated aspect of game performance, frame spikes (also known as “stutters” or “hitches”) are also very much worth our attention. Very long single frames or groups of frames are most usually caused by spikes in CPU workload. This could be, for example: Gameplay code, physics, loading assets, or “spawning” assets after loading them. When displaying a loading screen these frame spikes aren’t objectionable, but during gameplay they cause disruption to animation and input, severely degrading the user experience.
Ideally the extra workload caused by loading assets during gameplay should be carefully spread out over multiple frames so the per-frame CPU impact is low, and by using threads on a multi-core CPU the additional work is kept out of the critical path of game simulation and rendering. This should cause even a CPU-bound game to have minimal spikes. Game developers are justifiably spending a lot of effort architecting their engines to minimize these hitches and provide a smooth uninterrupted experience. However, on PC the resource model of the rendering API (such as DirectX) has to be taken into consideration because naïve implementations will cause hitching.
Measuring spikes
Before you are able to effectively address stutter in your application, you should implement a way of measuring it. Virtually all games have some way of showing average frame times and Frames Per Second, but measuring frame spikes is just as important. Logging and graphing frame times over time is a useful visualization which will highlight the occurrences of stutter. Once the worst frames have been identified, investigation can begin into what is causing the stutter to take place.
Another handy tool to visualize the smoothness of the game experience is to graph the frame times using percentiles. A graph of the top 10 percentile of frame times can be tracked during development to keep a finger on the pulse of stutter.
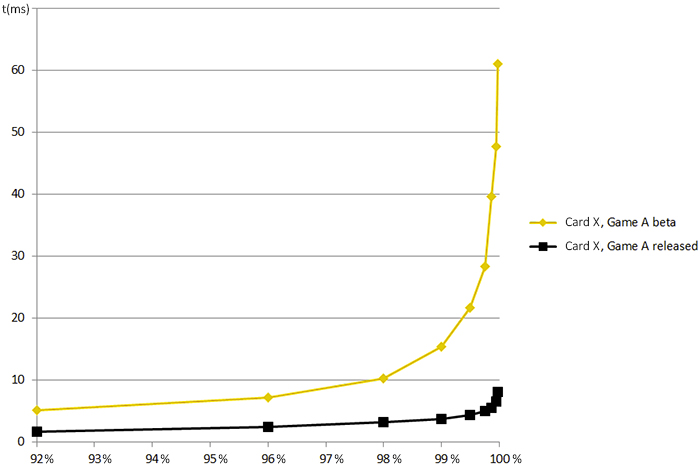
For more information on measuring stutter and graphing percentiles please take a look at Iain Cantlay’s post: Analysing Stutter – Mining More from Percentiles and his GDC 2015 presentation on stutter avoidanceNVIDIA SLI and Stutter Avoidance.
Hardware variability
The frequency and intensity of stutter can be heavily dependent on the hardware. In order to identify all possible sources of stutter it is a good idea to test your game on different hardware configurations with different possible bottlenecks. Testing with GPUs with limited VRAM is obviously important, as well as testing with limited system RAM, slower CPUs and slower HDDs. An SSD’s amazing speed may hide sources of stutter which could occur when the OS or the game is installed on a mechanical hard drive. For example, paging memory to disk can be much less noticeable with an SSD.
Memory overcommitment
GPU video memory is a limited resource. In DirectX 11 and OpenGL the application is allowed to overcommit video memory without crashing. Overcommitment means allocating more memory than is physically available. However, just like with CPU memory, this forces the OS and the graphics driver to start paging the memory in and out of VRAM which is as slow as it sounds! If a rendering operation is dependent on a non-resident resource, the GPU will have to stall, and these stalls can take a long time. Therefore you should never rely on video memory paging. Instead; query the GPUs memory size and use this to limit the amount of requested resident data. Please be aware on PC there are always other users of VRAM so budget your application appropriately.
For more information on identifying and visualizing video memory overcommitment please check out Louis Bavoil’s article Detecting Video-Memory Overcommitment using GPUView
Texture and buffer creation
On most game consoles, a game engine’s streaming system writes directly into GPU-accessible memory. When the carefully metered streaming system is done loading an asset, it can immediately be used for rendering. On PC, however, the memory has to be passed into API objects using a call to something like CreateBuffer or CreateTexture. This step is not free and is performed “on the clock”. In other words this takes time within the API on the calling thread. It is therefore strongly encouraged to perform all API object creation calls within the same metered streaming system and before the object is considered loaded and ready for use on the render thread. This will prevent unexpected hitches where an object is spawned prematurely and CreateBuffer or CreateTexture calls are performed within the critical path of a frame (usually blocking the render thread).
Shader creation
Similar thought has to be given to the cost of creating shaders. On consoles, shaders are compiled directly to native GPU instructions during the build which means they are ready to use for rendering as soon as they are in memory. However, on PC the variability of hardware means shaders have to be compiled by the local driver. This can be a very expensive operation so just like with buffers and textures care has to be taken when creating them during gameplay.
Creating shaders in the same frame as when they are used for rendering is likely to result in a large stall. NVIDIA’s driver currently has two strategies for shader creation in DirectX 11:
- If the application only calls CreatePixelShader (or one of the variants for other shader types) from one thread per frame, then these calls will return immediately and the driver will itself handle shader compilation asynchronously. It can be useful to rely on the driver to perform shader compilation in the background. However, if the shader is used for a draw call before the compilation is finished the driver is forced to stall until compilation has been completed.
- If the application creates shaders on multiple threads per frame, the driver will assume the application’s job system takes responsibility for creating shaders in a way that will not stall rendering. This will cause calls to CreatePixelShader to run “on the clock”, so they won’t return until shader compilation has been completed.
The second scenario is more controllable for the game engine. When calling CreatePixelShader on multiple threads (outside of the critical path of simulation and rendering!), the engine can delay spawning objects for rendering until it can guarantee all shaders have been created and are ready for rendering.
In DirectX 12 it is likewise highly advisable to create Pipeline State Objects in an asynchronous, threaded way. Creating PSO’s asynchronously while streaming in data will reduce the CPU impact and improve the smoothness of your game. Because PSO’s encapsulate so much more state than just shaders, it may be more complicated to create PSO’s up-front (compared to only compiling shaders) but keeping PSO creation out of the rendering critical path is necessary to avoid stalls.
Note that our driver does cache compiled shaders on disk after they are first encountered to improve the performance of subsequent application runs. Regardless, the ideas discussed here are key to providing a good user experience on “first-run”, or when a driver installation invalidates the disk cache! During development, we recommend that you disable the “Shader cache” functionality in the NVIDIA Control Panel’s “Manage 3D settings” tab to ensure the actual shader compilation cost is always exposed and you’re testing for the first-run experience (the worst case).
DirectX 12
DirectX 12 is a radically new rendering API for Windows 10. While, previously, the application provided rendering and resource allocation instructions in an abstract way and relied on the driver to optimize them, now the application has been given a great degree of control over both. This can result in more efficient use of system resources but requires a high degree of sophistication in your rendering engine’s design. Please carefully weigh the pros and cons of explicit API’s before committing to support them, as DirectX 11 remains a simple, performant, and very well supported rendering API on Windows.
There are too many topics here to list so I will summarize some of the most critical considerations and encourage you to read our comprehensive DX12 Do’s and Don’ts article.
- Thread all resource creation and work submission. This was an important factor in DirectX 12’s design and a requirement of an efficient implementation.
- Create PSOs asynchronously during loading of assets and avoid creating them while recording command lists to prevent stutter.
- Expect to optimize for different hardware vendors. Previously, each IHV’s driver implemented their own optimal strategy, but now more of this work is expected on the application side.
- Carefully manage your video memory usage and residency. This, also, is now entirely the application’s responsibility.
- Make use of the multi-adapter API to optimize SLI specifically for your game engine.
SLI Performance Considerations
Enthusiast gamers often install multiple GPUs in their machines in order to reach processing power beyond the limits of the fastest single GPUs. Making your game SLI-compatible is absolutely worth it, as the highest quality bar on PCs is always moving to new heights. For example, the upcoming 4k 144hz displays are capable of processing an astonishing 1 billion pixels per second, and feeding this can push even the highest-end PCs of today to their limits.
The most common mode of SLI rendering (outside of VR) is Alternate Frame Rendering (AFR). In this mode, the rendering of each whole frame is executed on another GPU in the configuration, in an alternating fashion. In ideal GPU-bound situations, this mode can scale the output framerate linearly with the number of GPUs.
AFR considerations
AFR provides the application with the illusion of a single physical GPU, but some considerations have to be taken into account to allow for optimal scaling. At a very high level, there are several limiting factors to keep in mind:
- Rendering on multiple GPUs increases the number of frames in flight. Don’t artificially restrict the amount of frames in flight or wait too early on the CPU for a frame to complete.
- GPU-GPU transfer bandwidth is a limited resource. A transfer occurs when a frame consumes data produced by a previous frame, on a different physical GPU. These data transfers between GPUs consume the system’s PCIE bandwidth, and the amount of bytes transferred between GPUs can limit the maximum achievable output framerate.
- The access pattern of transferred resources is also important. Data produced at the end of a frame, and consumed at the beginning of the next frame, could cause rendering to become serialized.
Advice
Much has been said about optimizing applications for SLI. I will try to summarize this advice to satisfy the above constraints and achieve optimal SLI scaling:
- First of all, please test SLI. We recommend to use NVIDIA Nsight’s “SLI Events” feature to identify which transfers take place each frame during gameplay. Then, mark unnecessary transfers for removal and investigate necessary transfers for optimization strategies.
- Be aware of increased rendering latency with multiple GPUs. Don’t read back data (queries or buffers) on the CPU until N+1 frames have been rendered, where N is the number of GPUs.
- Avoid all unnecessary inter-frame dependencies. By default, in AFR mode, the driver is conservative and transfers all resources which are detected as dependencies to ensure correctness. However, some of these resources may not need to be transferred. For example, a rendertarget which is always completely overwritten before being read from can be removed from the transfer list. Identify these unnecessary transfers using Nsight and then add rendertarget clears or NVAPI annotations to hint to the driver when resources don’t need to be transferred.
-
Deploy strategies to reduce the impact of necessary inter-frame transfers:
- Reduce memory footprint of resources which have to be transferred.
- Avoid reading data from an inter-frame dependent resource in the beginning of the current frame if the resource was last modified at the end of the previous frame. Where possible, move work in the frame to allow as much time between these events as you can in order to allow for maximum GPU rendering overlap.
- Recalculate the data computed in the previous frame instead of transferring. This can be much faster than a transfer as GPU power scales linearly while GPU-GPU bandwidth is fixed.
- Read data from N frames ago when using N GPUs, so the data never needs to leave the GPU.
- Avoid partial updates of surfaces (texture atlases) since they have to be transferred in their entirety. Texture arrays are resolved on a per-slice basis.
- If you support DirectX 12 we encourage you to use its multi-adapter API, as you will be able to precisely specify which resources need to be shared between adapters and how they are synchronized using cross-adapter barriers. However keep in mind GPU-GPU bandwidth is still limited and the above strategies will still help with optimizing scaling.
For more up-to-date guidance on SLI programming please see Iain Cantlay and Lars Nordskog’s GDC 2015 presentation on the subject NVIDIA SLI and stutter avoidance.
SLI VR
In Virtual Reality rendering, the use of SLI goes beyond AFR. It’s obvious how rendering two views (one per eye) can map exactly to two GPUs. While AFR works more or less implicitly, rendering the same frame on multiple GPUs for VR requires the use of some special interfaces. Our VR team at NVIDIA has created a VR SLI SDK which enables you to render the view for each eye on separate GPUs with minimal effort.
For more information on VR SLI and many other advanced tools created to improve VR performance please check out the complete NVIDIA VRWorks™ SDK.
Conclusion
Thanks for taking the time to read this article! I hope it will prove helpful for your optimization work. Finally, I encourage you to not just rely solely on PC’s great hardware power. As a gamer and as a developer I think it’s well worth the engineering time to make games run even smoother. Good luck, and please don’t hesitate to reach out to our team if you have any questions.