VRWorks - VR SLI
VR SLI provides increased performance for virtual reality apps where multiple GPUs can be assigned a specific eye to dramatically accelerate stereo rendering. With the GPU affinity API, VR SLI allows scaling for systems with more than 2 GPUs.
| Hardware: | Compatible with: Maxwell or more recent GPUs. (GeForce GTX 900 series and Quadro M5000 and higher) |
| Software: | Compatible with the following APIs: DX11, OpenGL (Multicast) and Vulkan. Integrated with Unreal Engine and Unity |
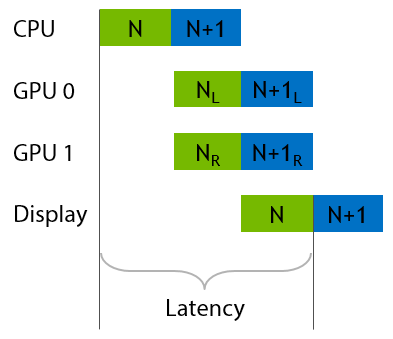
Given that the two stereo views are independent of each other, it’s intuitively obvious that you can parallelize the rendering of them across two GPUs to get a massive improvement in performance.

Before we dig into VR SLI, let's first explain how “normal”, non-VR SLI works. For years, we’ve had alternate-frame SLI, in which the GPUs trade off frames. In the case of two GPUs, one renders the even frames and the other the odd frames. The GPU start times are staggered half a frame apart to try to maintain regular frame delivery to the display.
This works well to increase framerate relative to a single-GPU system, but it doesn’t really help with latency. So this isn’t the best model for VR.
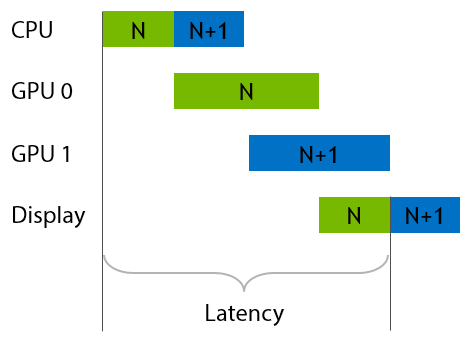
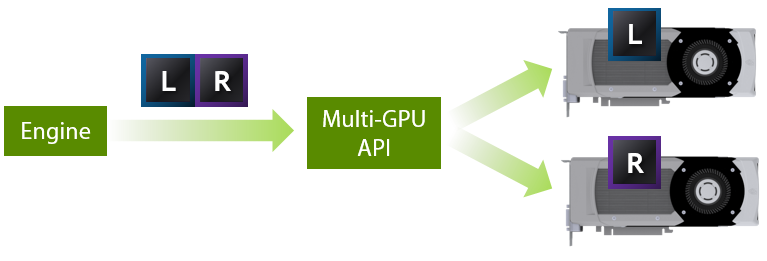
A better way to use two GPUs for VR rendering is to split the work of drawing a single frame across them—namely, by rendering each eye on one GPU. This has the nice property that it improves both framerate and latency relative to a single-GPU system.
Here are some of the main features of our VR SLI API. First, it enables GPU affinity masking: the ability to select which GPUs a set of draw calls will go to. With our API, you can do this with a simple API call that sets a bitmask of active GPUs. Then all draw calls you issue will be sent to those GPUs, until you change the mask again.
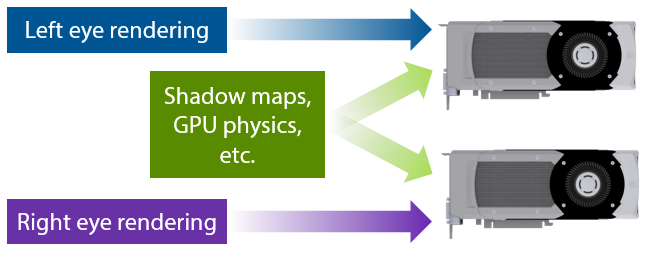
With this feature, if an engine already supports sequential stereo rendering, it’s very easy to enable dual-GPU support. All you have to do is add a few lines of code to set the mask to the first GPU before rendering the left eye, then set the mask to the second GPU before rendering the right eye. For things like shadow maps, or GPU physics simulations where the data will be used by both GPUs, you can set the mask to include both GPUs, and the draw calls will be broadcast to them. It really is that simple, and incredibly easy to integrate in an engine.
By the way, all of this extends to as many GPUs as you have in your machine, not just two. So you can use affinity masking to explicitly control how work gets divided across 4 or 8 GPUs, as well.
GPU affinity masking is a great way to get started adding VR SLI support to your engine. However, note that with affinity masking you’re still paying the CPU cost for rendering both eyes. After splitting the app’s rendering work across two GPUs, your top performance bottleneck can easily shift to the CPU.
To alleviate this, VR SLI supports a second style of use, which we call broadcasting. This allows you to render both eye views using a single set of draw calls, rather than submitting entirely separate draw calls for each eye. Thus, it cuts the number of draw calls per frame—and their associated CPU overhead—roughly in half.
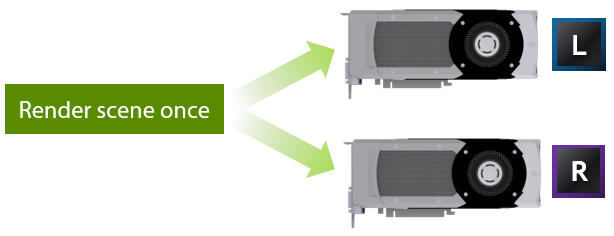
This works because the draw calls for the two eyes are almost completely the same to begin with. Both eyes can see the same objects, are rendering the same geometry, with the same shaders, textures, and so on. So when you render them separately, you’re doing a lot of redundant work on the CPU.
The only difference between the eyes is their view position—just a few numbers in a constant buffer. So, VR SLI lets you send different constant buffers to each GPU, so that each eye view is rendered from its correct position when the draw calls are broadcast.
So, you can prepare one constant buffer that contains the left eye view matrix, and another buffer with the right eye view matrix. Then, in our API we have a SetConstantBuffers call that takes both the left and right eye constant buffers at once and sends them to the respective GPUs. Similarly, you can set up the GPUs with different viewports and scissor rectangles.
Altogether, this allows you to render your scene only once, broadcasting those draw calls to both GPUs, and using a handful of per-GPU state settings. This lets you render both eyes with hardly any more CPU overhead then it would cost to render a single view.
VR SLI for OpenGL is accessed through a new OpenGL extension called “GL_NVX_linked_gpu_multicast” that can be used to greatly improve the speed of HMD rendering. With this extension, it is possible to control multiple GPUs that are in an NVIDIA SLI group with a single OpenGL context to reduce overhead and improve frame rates. .

For stereo rendering of a frame in VR, the GPU must render the same scene from two different eye positions. A normal application using only one GPU must render these two images sequentially, which means twice the CPU and GPU workload (see image above).

With the OpenGL multicast extension, it’s possible to upload the same scene to two different GPUs and render it from two different viewpoints with a single OpenGL rendering stream. This distributes the rendering workload across two GPUs and eliminates the CPU overhead of sending the rendering commands twice, providing a simple way to achieve substantial speedup.
Additional Information: VR SLI: Accelerating OpenGL Virtual Reality with Multi-GPU Rendering