NVIDIA Merlin NVTabular
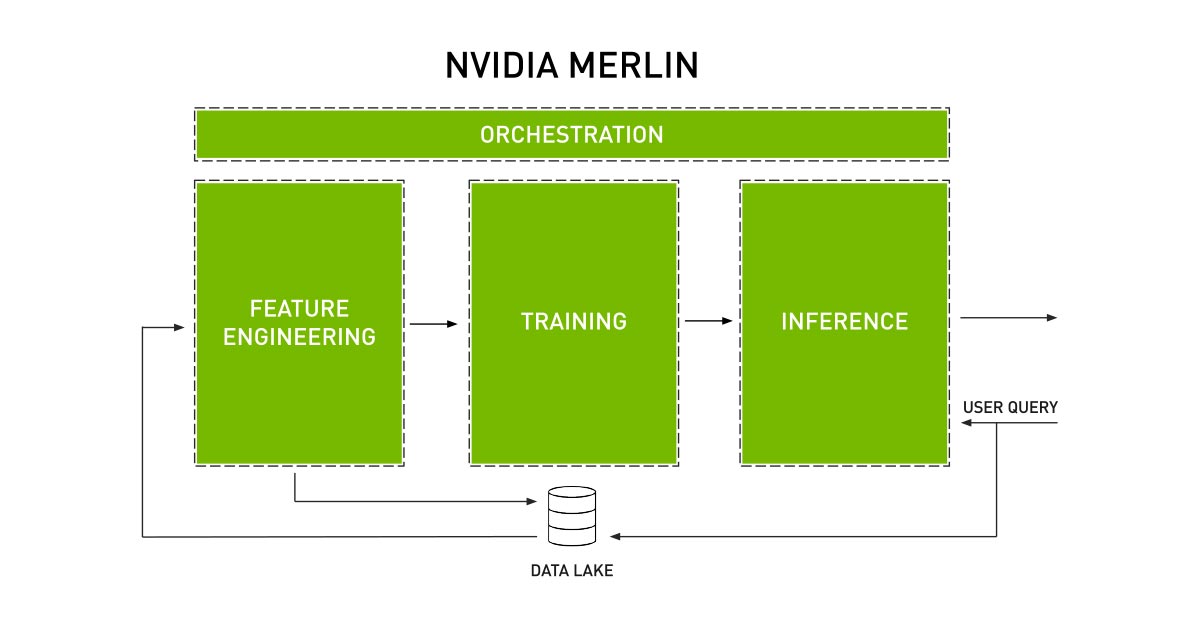
NVIDIA Merlin™ accelerates the entire pipeline, from ingesting and training to deploying GPU-accelerated recommender systems. Merlin NVTabular is a feature engineering and preprocessing library designed to effectively manipulate terabytes of recommender system datasets and significantly reduce data preparation time. It provides efficient feature transformations, preprocessing, and high-level abstraction that accelerates computation on GPUs using the RAPIDS™ cuDF library.
Download and Try It Today
Merlin NVTabular Core Features
Feature Engineering
NVTabular's fast feature transforms reduce data prep time and eases deploying recommender models to production. With NVTabular recommender focused APIs, data scientists and machine learning engineers are able to quickly process datasets of all sizes, implement more experimentation, and are not bound by CPU or GPU memory. Also, includes multi-hot categoricals and vector continuous passing support to ease feature engineering.
Run examplesInteroperability with Open Source
Data scientists and machine learning engineers use a hybrid of methods, tools, libraries, and frameworks, including open source. NVTabular native tabular data support includes comma-separated values (CSV) files, Apache Parquet, Apache Orc, and Apache Avro. Also, NVTabular data loaders are optimized for TensorFlow (TF), PyTorch, and Merlin HugeCTR. All Merlin components, including NVTabluar, are interoperable with open source.
Learn moreAccelerated on GPUs
NVTabular provides a high level abstraction that accelerates computation on GPUs using the RAPIDS cuDF library. Also, NVTabular's support for multi-node scaling and multi-GPU with DASK-CUDA and dask.distributed accelerates distributed parallelism.
Explore moreMerlin NVTabular Performance
NVTabular's multi-GPU support using RAPIDS cuDF, Dask, and Dask_cuDF enables a high-performance recommender-specific pipeline. Provides 95x speedup using NVTabular multi-GPU on the NVIDIA DGX™ A100 compared to Spark on a four-node, 96 vCPU core, CPU cluster processing 1.3 TB of data in the Criteo Terabyte dataset, Also provides a speedup of 5.3x using eight NVIDIA A100 GPUs, from 10 minutes on 1xA100 to 1.9 minutes on 8xA100.
Explore more benchmark detailsSpeedup Using NVTabular on Multi-GPU

Get Started with Merlin NVTabular
All NVIDIA Merlin components are available as open-source projects on GitHub. However, a more convenient way to make use of these components is by using Merlin NVTabular containers from the NVIDIA NGC catalog. Containers package the software application, libraries, dependencies, and runtime compilers in a self-contained environment. This way, the application environment is both portable, consistent, reproducible, and agnostic to the underlying host system software configuration.
Merlin NVTabular on NGC
Merlin Training
Enables users to do preprocessing and feature engineering with NVTabular and then train a deep learning-based recommender system model with HugeCTR.
Merlin Tensorflow Training
Utilize preprocessing and feature engineering with NVTabular and then train a deep learning-based recommender system model with TensorFlow.
Merlin Pytorch Training
Leverage preprocessing and feature engineering with NVTabular and then train a deep learning-based recommender system model with PyTorch.
Merlin Inference
Container allows users to deploy NVTabular workflows and HugeCTR or TensorFlow models to the NVIDIA Triton™ Inference Server for production.
Merlin NVTabular on GitHub
The GitHub repository helps users get started with NVTabular with documentation, tutorials, examples, and notebooks.

Merlin NVTabular Resources
Announcing NVTabular Open Beta
Discover how multi-GPU support and data loaders accelerate recommender workflows.
NVIDIA Merlin
NVIDIA Merlin consists of Merlin Feature Engineering: NVTabular, Merlin Training: HugeCTR, Merlin Inference: NVIDIA® TensorRT™ and Triton, and Merlin Reference Applications.
Industry Best Practices
Learn latest trends and insights about building, deploying, and optimizing recommender systems that effectively engage users and impact business value. Best practices from Tencent, Meituan, The New York Times, Magazine Luiza, and more.
Session-Based Recommenders
The NVIDIA Merlin team designed Transformers4Rec to help machine learning engineers and data scientists explore and apply transformers to building sequential and session-based recommenders.
NVTabular is available to download from the NVIDIA NGC catalog, the GitHub repository, or the Anaconda repository.