cuBLAS
Basic Linear Algebra on NVIDIA GPUs
Download Documentation Samples Support Feedback
NVIDIA cuBLAS is a GPU-accelerated library for accelerating AI and HPC applications. It includes several API extensions for providing drop-in industry standard BLAS APIs and GEMM APIs with support for fusions that are highly optimized for NVIDIA GPUs. The cuBLAS library also contains extensions for batched operations, execution across multiple GPUs, and mixed- and low-precision execution with additional tuning for the best performance.
The cuBLAS library is included in both the NVIDIA HPC SDK and the CUDA Toolkit.
Explore what’s new in the latest release.
cuBLAS API Extensions
cuBLAS Host API
cuBLAS Host APIs for CUDA-accelerated BLAS for Level 1 (vector-vector), Level 2 (matrix-vector), and Level 3 (matrix-matrix) operations. cuBLAS also includes custom GEMM extension APIs that are simple to use for drop-in hardware acceleration.
cuBLAS APIs are available in the cuBLAS library.
cuBLASLt Host API
cuBLASLt Host APIs are multi-stage GEMM APIs that are highly expressive, allowing applications to leverage the latest NVIDIA architecture features for the best performance with support for fusions and performance tuning options.
cuBLASLt APIs are available in the cuBLAS library.
cuBLASXt Single-Process Multi-GPU Host API
cuBLASXt Host API exposes a multi-GPU capable interface for efficiently dispatching Level 3 workloads across one or multiple GPUs in a single node.
cuBLASXt APIs are available in the cuBLAS library.
cuBLASMp Multi-Node Multi-GPU Host API (Preview)
cuBLASMp (Preview) is a high-performance, multi-process, GPU-accelerated library for distributed basic dense linear algebra. cuBLASMp is available for standalone download and as part of the HPC SDK.
Download cuBLASMp
cuBLASDx Device API (Preview)
cuBLASDx (Preview) is a device side API extension to cuBLAS for performing BLAS calculations inside your CUDA kernel. Fusing numerical operations decreases the latency and improves the performance of your application.
Download cuBLASDx
cuBLAS Key Features
- Complete support for all 152 standard BLAS routines
- Support for half-precision and integer matrix multiplication
- GEMM and GEMM extensions with fusion optimized for Tensor Cores
- GEMM performance tuned for sizes used in various Deep Learning models
- Supports CUDA streams for concurrent operations
cuBLAS Performance
The cuBLAS library is highly optimized for performance on NVIDIA GPUs, and leverages tensor cores for acceleration of low- and mixed-precision matrix multiplication.



cuBLAS Matrix Multiply performance on Datacenter GPUs for various precisions
cuBLASMp Key Features
- Multi-node multi-GPU basic linear algebra functionality
- 2D Block Cyclic data layout
- Fortran wrappers available through nvfortran
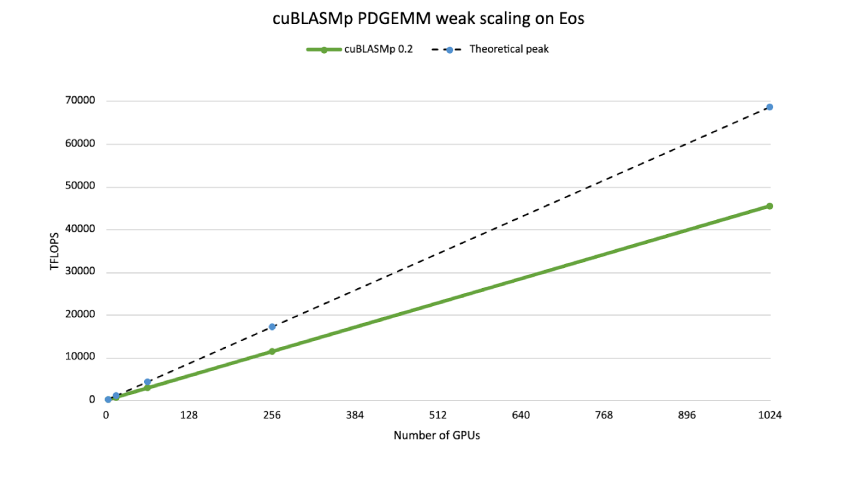
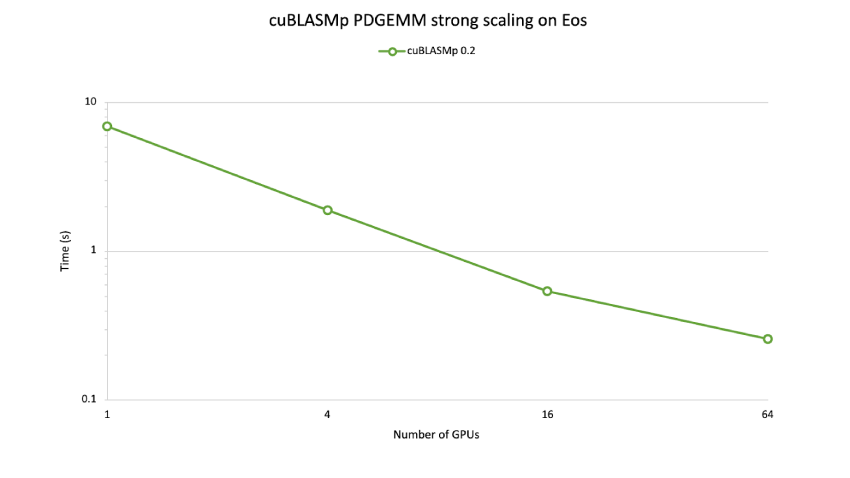
cuBLASMp Performance
cuBLASMp harnesses tensor core acceleration, while efficiently communicating between GPUs and synchronizing their processes.
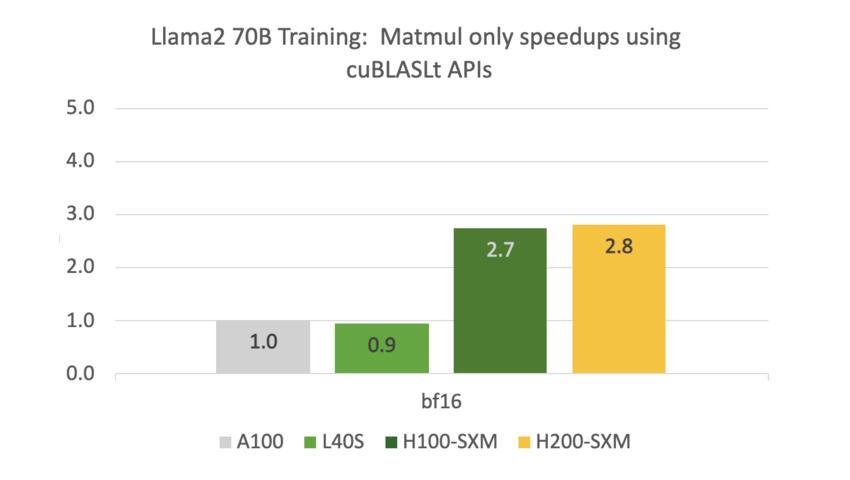
cuBLASLt Performance
Weak scaling of cuBLASMp distributed double precision GEMM. M,N,K = 55k per GPU