NVIDIA TensorRT 的优势

推理速度提高 36 倍
基于 NVIDIA TensorRT 的应用程序在推理过程中的执行速度比纯 CPU 平台快达 36 倍,使您能够优化在所有主要框架上训练的神经网络模型,以高精度校准较低精度,并部署到超大规模数据中心、嵌入式平台或汽车产品平台。


加速每项工作负载
TensorRT 使用量化感知训练和训练后量化和浮点 16 (FP16) 优化来提供 INT8,用于部署深度学习推理应用程序,例如视频流、推荐、欺诈检测和自然语言处理。降低精度的推理可显着减少延迟,这是许多实时服务以及自主和嵌入式应用程序所必需的。

使用 Triton 进行部署、运行和扩展
TensorRT 优化的模型可以使用 NVIDIA Triton™ 进行部署、运行和扩展,这是一种开源推理服务软件,其中包含 TensorRT 作为其后端之一。使用 Triton 的优势包括动态批处理和并发模型执行的高吞吐量,以及模型集成、流式音频/视频输入等功能。
大型语言模型的推理
NVIDIA TensorRT-LLM
NVIDIA TensorRT-LLM 是一个开源库,可加速和优化 NVIDIA AI 平台上最新大型语言模型 (LLM) 的推理性能。它让开发人员可以尝试新的 LLM,提供高性能和快速定制,而无需深入了解 C++ 或 CUDA。
开发人员现在可以
通过同一工作流程无缝工作
,将 NVIDIA 数据中心系统上的LLM性能加速到本地台式机和笔记本电脑 GPU(包括本机 Windows 上的 NVIDIA RTX 系统)。
TensorRT-LLM 将 TensorRT 的深度学习编译器(包括 FasterTransformer 的优化内核、预处理和后处理以及多 GPU 和多节点通信)包装在一个简单的开源 Python API 中,用于定义、优化和执行LLM生产中的推理。
阅读我们的博客,了解如何开始

领先的推理性能
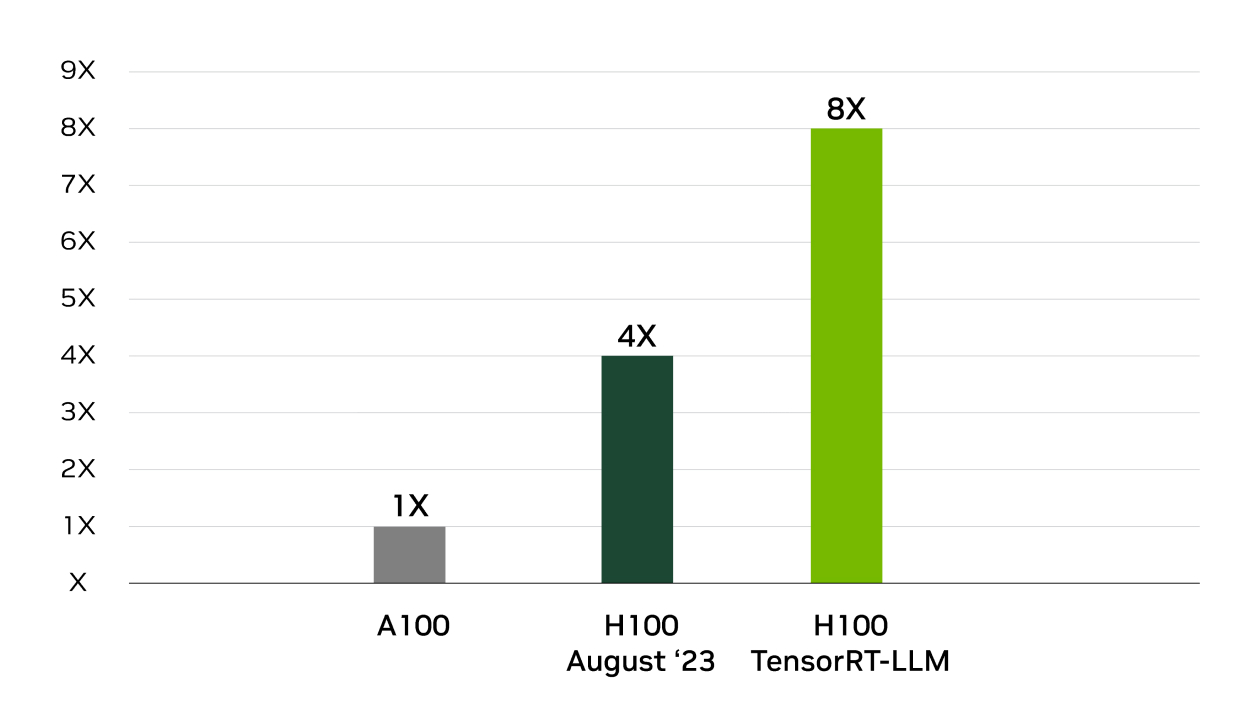
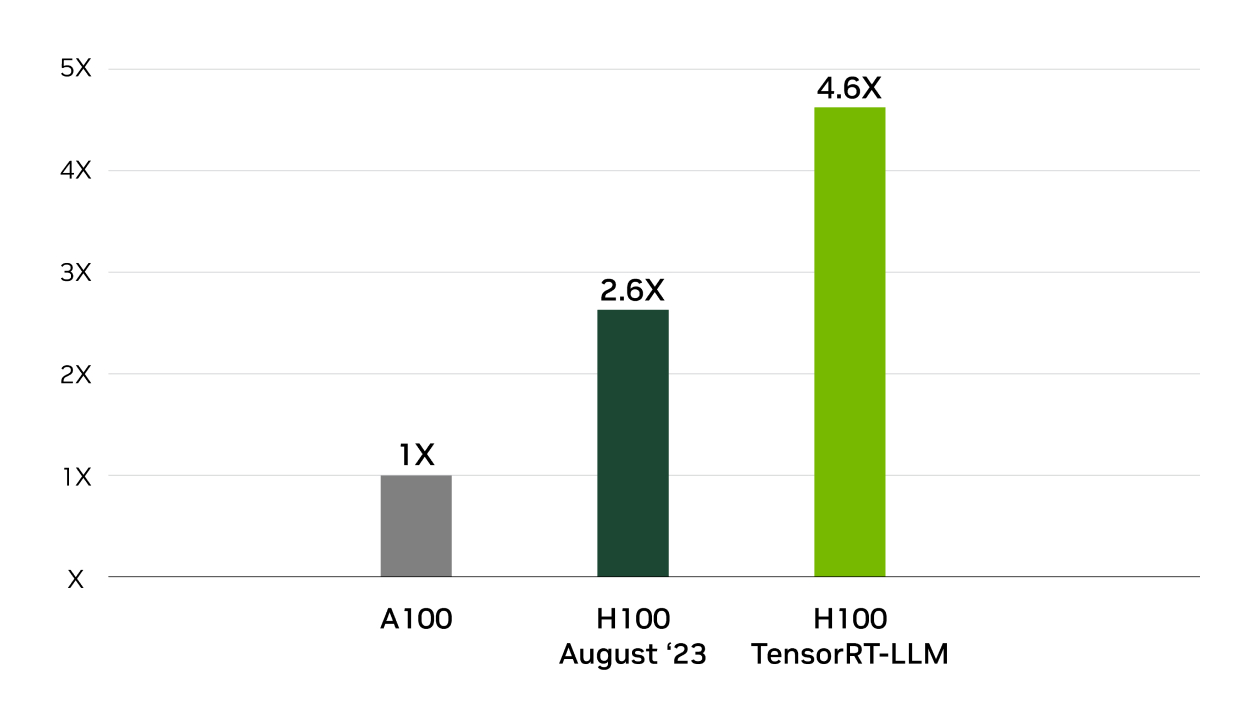
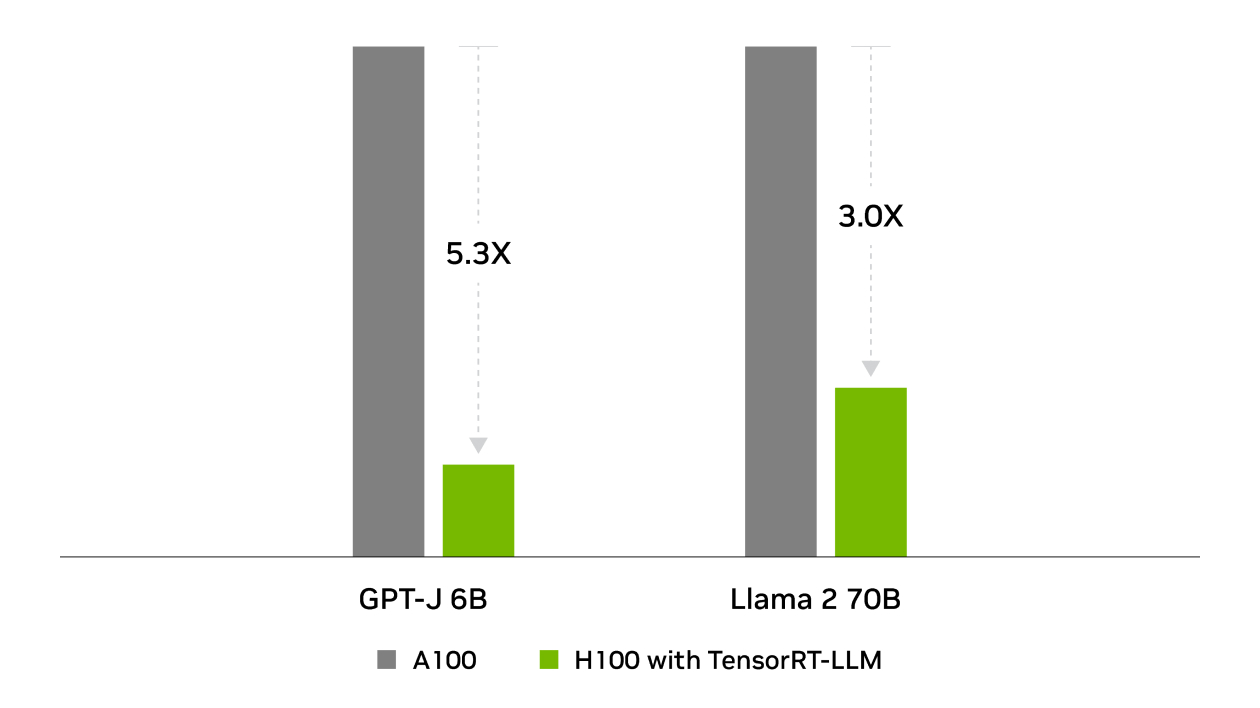
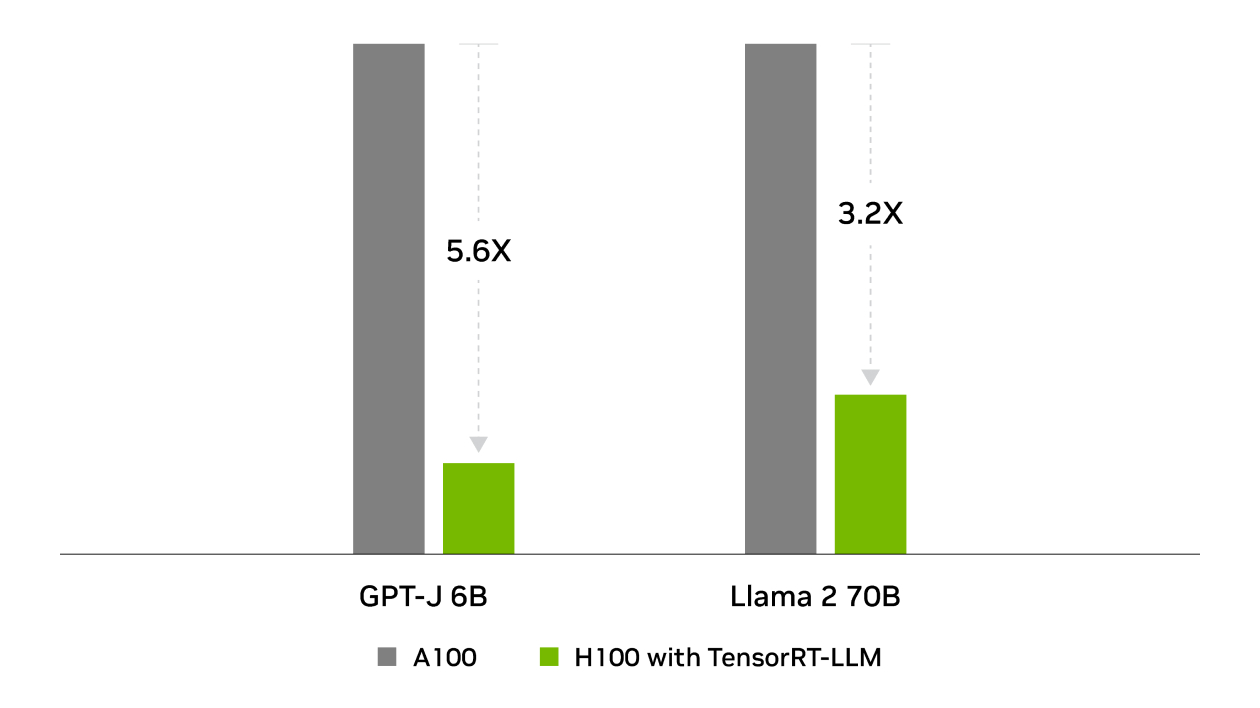
TensorRT 是 NVIDIA 在 MLPerf Inference 行业标准基准测试中获胜的幕后功臣。 TensorRT-LLM 加速了 用于生成 AI 的最新大型语言模型,性能提高了 8 倍,TCO 降低了 5.3 倍,能耗降低了近 6 倍。
开始使用 NVIDIA TensorRT

购买 NVIDIA AI Enterprise
购买 NVIDIA AI Enterprise,这是一个端到端 AI 软件平台,包括 TensorRT 和 TensorRT-LLM,用于任务关键型 AI 推理,并提供企业级安全性、稳定性、可管理性和支持。
申请 90 天 NVIDIA AI 企业评估许可证 联系我们了解有关购买TensorRT 的更多信息
下载容器、代码和版本
TensorRT 可作为多个不同平台上的二进制文件,或作为 NVIDIA NGC™ 上的容器。 TensorRT 还集成到 PyTorch 、 TensorFlow 和 Triton 推理服务器 的 NGC 容器中。
下载 TensorRT 从 NGC 中拉取 TensorRT 容器 访问 TensorRT-LLM 存储库 访问更多开发资源加速各种推理平台
TensorRT 可以优化应用程序并将其部署到数据中心以及嵌入式和汽车环境。它为 NVIDIA TAO 、 NVIDIA DRIVE™ 、 NVIDIA Clara™ 和 NVIDIA Jetpack™ 等关键 NVIDIA 解决方案提供支持。
TensorRT 还集成了特定于应用程序的 SDK,例如 NVIDIA DeepStream 、 NVIDIA Riva 、 NVIDIA Merlin™ 、 NVIDIA Maxine™ 、 NVIDIA Morpheus 和 NVIDIA Broadcast Engine ,为开发人员提供部署智能视频分析、语音 AI、推荐系统的统一路径系统、视频会议、基于 AI 的网络安全以及生产中的流媒体应用程序。

支持主要框架
TensorRT 与 PyTorch 和 TensorFlow 集成,因此您只需一行代码即可将推理速度提高 6 倍。如果您在专有或自定义框架中执行深度学习训练,请使用TensorRT C++ API 导入和加速您的模型。请阅读 TensorRT 文档 了解详情。
以下是一些集成以及有关如何开始的信息。
TensorFlow
TensorRT 和 TensorFlow 紧密集成,因此您可以通过 TensorRT 的强大优化获得 TensorFlow 的灵活性,例如使用一行代码将性能提高 6 倍。
了解详情ONNX
TensorRT 提供了 ONNX 解析器,因此您可以轻松地将 ONNX 模型从流行框架导入到 TensorRT 中。它还与 ONNX 运行时集成,提供了一种以 ONNX 格式实现高性能推理的简单方法。
了解详情MATLAB
MATLAB 通过 GPU Coder 与 TensorRT 集成,因此您可以自动为 NVIDIA Jetson™ 、 NVIDIA DRIVE 和数据中心平台生成高性能推理引擎。
了解详情阅读成功案例



被各行业广泛采用
TensorRT 资源
随时了解 NVIDIA 的最新推理新闻。