在 Merlin HugeCTR 博文系列的第一部分,我们讨论了训练大型深度学习推荐系统所面临的挑战,以及 HugeCTR 如何解决这些问题。
深度学习推荐系统可能包含超大型嵌入表,这些嵌入表可能会超出主机或 GPU 显存。
我们专为推荐系统设计了 HugeCTR。
这是一个专门用于在 GPU 上训练和部署大型推荐系统的框架。
它为在多个 GPU 或节点上分配单个嵌入表提供了不同的策略。
HugeCTR 是 NVIDIA Merlin] 的主要训练引擎,后者是一种 GPU 加速框架,旨在为推荐系统工作提供一站式服务,从数据准备、特征工程、多 GPU 训练到本地或云中的生产级推理。
训练性能和可扩展性一直是 HugeCTR 的突出特性,为 MLPerf 训练 v0.7 推荐任务中的 NVIDIA 获奖作品提供支持,但我们近期采纳了早期采用者和客户的反馈,以帮助改进易用性。
这篇博文将着重讨论我们在易用性方面的持续承诺和近期改进。
HugeCTR 是一种定制的深度学习框架,使用 CUDA C++ 编写,专用于推荐系统。
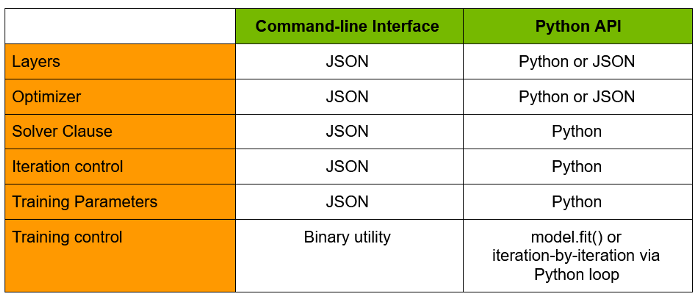
起初,超参数和神经网络架构在 JSON 配置中定义,然后通过命令行接口执行。
近期,我们添加了 Python API,使其更易于使用。
表 1 汇总了命令行和 Python API 之间的主要区别。
我们建议使用 Python API,并将在后面部分中重点介绍。
但是,如果您对命令行界面感兴趣,可以在此处找到一些示例。
直接从 Python 配置和训练 HugeCTR
自 v2.3 版本起,HugeCTR 开始提供易于使用的 Python 接口,用于定义模型架构、超参数、数据加载程序以及训练循环。
此接口使 HugeCTR 更接近于数据科学 Python 生态系统和实践。
利用此接口的方法有两种:
1. 类似于 Keras 的高级 Python API
HugeCTR 现在提供了一个类似 Keras 的高级 Python API 套件,用于定义模型、层、优化器和执行训练。
下文提供了一个示例代码段。
如下所示,此 API 模拟热门的 Keras 构建-编译-适应范式。
2. 低级 Python API
HugeCTR 低级 Python API 允许从 JSON 文件读取模型定义和优化器配置,从而提供向后兼容性。
此外,此 API 允许使用 Python 循环不断手动执行训练,从而获得对训练的精细控制。
在本博客的动手实践部分中,我们将详细介绍如何使用此 API 基于两个数据集训练模型。
我们将在以下示例中演示此 API。
使用预训练的 HugeCTR 模型进行预测
随着 v3.0 版本的发布,HugeCTR 增加了对基于 GPU 的推理的支持,可生成许多批次的预测。
HugeCTR 将参数服务器、嵌入缓存和推理会话分离开来,以便更好地管理资源以及更有效地利用 GPU。
- 参数服务器用于加载和管理嵌入表。
对于超过 GPU 显存的嵌入表,参数服务器将嵌入表存储在 CPU 内存上。
- 嵌入缓存为模型提供嵌入查找服务。活动嵌入条目存储在 GPU 显存上,以便快速查找。
- 推理会话将这两者与模型权重和其他参数结合起来,以执行前向传播。
下文提供了初始化 HugeCTR 推理的函数调用序列示例。
我们将使用 config_file、embedding_cache 和 parameter_server 初始化 InferenceSession。
HugeCTR Python 推理 API 需要一个 JSON 格式的推理配置文件,该文件类似于训练配置 JSON。
但是,在添加推理子句时,我们需要省略优化器和求解器子句。
我们还需要将输出层更改为 Sigmoid 类型。
推理子句中的 dense_model_file 和 sparse_model_file 参数应设置为指向由 HugeCTR 训练的模型文件(_dense_xxxx.model 和 0_sparse_xxxx.model)。
我们在 Github 存储库中提供了多个完整示例:电子商务行为数据集和 Microsoft 新闻数据集。
我们一起来看一些示例
我们在 Github 存储库中提供了 HugeCTR API 的多个端到端示例。这些笔记本基于实际数据集和应用领域提供了完整的 Merlin 演练,从数据下载、预处理和特征工程到模型训练和推理。
1. 高级 Python API 与 Criteo 数据集
Criteo 1TB Click Logs 数据集是公开可用于推荐系统的大型数据集。
它包含约 40 亿个示例的 1.3TB 未压缩点击日志。
在我们的示例中,数据集使用 Pandas 或 NVTabular 进行预处理,以规范化连续特征,并对分类特征进行分类。
之后,我们使用 HugeCTR 的高级 API 训练深度和交叉神经网络架构。
首先,我们定义求解器和优化器,以使用它初始化 HugeCTR 模型。
然后,我们可以逐层添加,这类似于 TensorFlow Keras API。
最后,我们只需要调用 .fit() 函数。
2. 低级 Python API 与电子商务行为数据集
在此演示笔记本中,我们将使用 REES46 营销平台中的多品类商店的电子商务行为数据[/u]作为我们的数据集。
此笔记本基于 RecSys 2020 大会上的 NVIDIA 教程构建而成。
我们使用 NVTabular 进行特征工程和预处理,并使用 HugeCTR 训练 Facebook 深度学习推荐系统模型 (DLRM)。
我们针对 Criteo 点击日志数据集改编了一个示例 Json 配置文件。
需要编辑以与此数据集匹配的几个参数为:
- slot_size_array:分类变量的基数,可以从 NVTabular 工作流程对象获取。
- dense_dim:密集特征的数量
- slot_num:分类变量的数量
以下 Python 代码会按批执行参数更新。
同样,我们针对 Microsoft 新闻数据集提供了第 2 个示例。
尝试使用 HugeCTR 的命令行和 Python API 训练推荐系统管线
我们致力于提供用户友好且易于使用的体验,以简化推荐系统工作流程。
我们近期根据早期采用者和客户的反馈对 HugeCTR 接口进行了改进。
HugeCTR Github 存储库提供了有关如何基于多个公共数据集(从小型到大型数据集都包含在内)使用此新接口的示例。
我们想邀请您针对您自己的领域改编这些示例,并见证 Merlin 的处理能力。
和往常一样,我们希望通过 Github 以及其他渠道获得您的反馈。
这是我们 HugeCTR 系列中关于“使用 HugeCTR 的新 API 训练大型深度学习推荐系统模型”的第二篇博文。
下一篇博文将讨论如何部署到生产。
敬请关注!