
近年来,建筑业和 采用机器学习 ( ML )工具。使用 GPU 加速计算日益密集的模型已成为一个突出的趋势。
为了增加用户访问,加速 WEKA 项目通过集成开源 RAPIDS 库,为在知名的 WEKA 算法中使用 GPU 提供了一个可访问的入口点。
在这篇文章中,我们将向您介绍加速 WEKA ,并学习如何使用 WEKA 软件利用图形用户界面( GUI )的 GPU 加速算法。这种 Java 开源替代方案适合于从不同环境或包中寻找各种 ML 算法的初学者。
什么是加速 WEKA ?
加速 WEKA 将 WEKA 软件(一种著名的开源 Java 软件)与利用 GPU 缩短 ML 算法执行时间的新技术相结合。针对没有系统配置和编码专业知识的用户,它有两个好处:易于安装和指导 ML 任务的配置和执行的 GUI 。
加速 WEKA 是一个可用于 WEKA 的软件包集合,它可以扩展以支持新的工具和算法。
什么是急流?
RAPIDS 是一组开源 Python 库,供用户在 NVIDIA GPU 上开发和部署数据科学工作负载。流行的库包括用于 GPU 加速数据帧处理的 cuDF 和用于 GPU 加速机器学习算法的 cuML 。 RAPIDS API 尽可能符合 CPU 对应项,例如 pandas 和 scikit-learn 。
%1 : %2 加速的 WEKA 架构
加速 WEKA 的构建块是 WekaDeeplearning4j 和 wekaRAPIDS (受 wekaPython 启发)等包。 WekaDeeplearning4j ( WDL4J )已经支持 GPU 处理,但在库和环境配置方面有非常特殊的需求。 WDL4J 为 Deeplearning4j 库提供了 WEKA 包装。
对于 Python 用户, weka Python 最初通过创建服务器并通过套接字与之通信来提供 Python 集成。有了它,用户可以在 WEKA 工作台内执行 scikit learn ML 算法(甚至 XGBoost )。此外, weka RAPIDS 通过在 wekaPython 中使用相同的技术提供与 RAPIDS cuML 库的集成。
总之,这两个包在用户友好的 WEKA 工作台内提供了增强的功能和性能。加速 WEKA 通过改进 JVM 和 Python 解释器之间的通信,在性能方面更进一步。它通过使用 Apache Arrow 和 GPU 内存共享等替代方法来实现这两种语言之间的高效数据传输。
加速 WEKA 还提供了与 RAPIDS cuML 库的集成,该库实现了在 NVIDIA GPU 上加速的机器学习算法。一些 cuML 算法甚至可以支持多 GPU 解。
支持的算法
加速 WEKA 目前支持的算法有:
- 线性回归
- 物流回归
- 山脊
- 套索
- 弹性网
- MBSGD 分类器
- MBSGDRegressor 公司
- 多项式 nb
- 伯努林
- 高斯 B
- 随机森林分类器
- 随机森林采伐
- 静止无功补偿器
- SVR 公司
- LinearSVC
- Kneighbors 回归器
- Kneighbors 分类器
多 GPU 模式下加速 WEKA 支持的算法有:
- Kneighbors 回归器
- Kneighbors 分类器
- 线性回归
- 山脊
- 套索
- 弹性网
- 多项式 nb
- 光盘
使用加速 WEKA GUI
在加速 WEKA 设计阶段,一个主要目标是使其易于使用。以下步骤概述了如何在系统上进行设置,并提供了一个简单的示例。
有关更多信息和全面入门,请参阅文档。加速 WEKA 的唯一先决条件是在系统中安装 Conda 。
- 加速 WEKA 的安装可通过提供包和环境管理的系统 Conda 获得。这种能力意味着一个简单的命令可以安装项目的所有依赖项。例如,在 Linux 机器上,在终端中发出以下命令以安装加速 WEKA 和所有依赖项。
conda create-n accelweka-c rapidsai-c NVIDIA -c conda forge-c waikato weka
- Conda 创建环境后,使用以下命令将其激活:
激活时
- 这个终端实例刚刚加载了加速 WEKA 的所有依赖项。使用以下命令启动 WEKA GUI 选择器:
韦卡
- 图 1 显示了 WEKA GUI 选择器窗口。从那里,单击 Explorer 按钮访问 Accelerated WEKA 的功能。

- 在 WEKA Explorer 窗口(图 2 )中,单击 Open file 按钮以选择数据集文件。 WEKA 使用 ARFF 文件,但可以从 CSV 中读取。根据属性的类型,从 CSV 转换可能非常简单,或者需要用户进行一些配置。
- 加载了数据集的 WEKA Explorer 窗口如图 3 所示。假设不想预处理数据,单击“分类”选项卡将向用户显示分类选项。
分类选项卡如图 4 所示。单击“选择”按钮将显示已实现的分类器。由于数据集的特性,有些可能被禁用。要使用加速 WEKA ,用户必须选择急流。积云分类器。之后,单击粗体 CuMLClassifier 将使用户转到分类器的选项窗口。
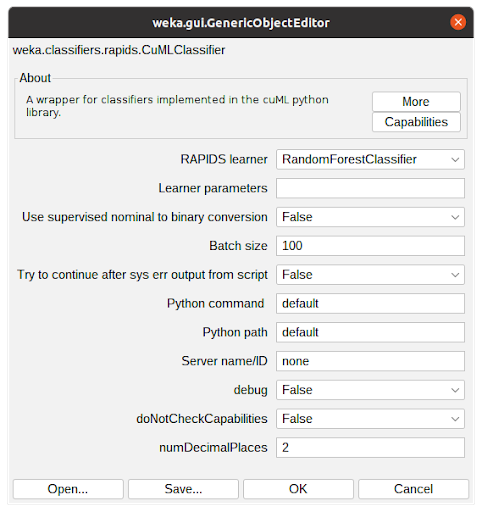
- 图 5 显示了 CuMLClassifier 的选项窗口。使用字段 RAPIDS 学习器,用户可以在软件包支持的分类器中选择所需的分类器。现场学习者参数用于修改 cuML 参数,其详细信息可在 cuML documentation 中找到。
其他选项用于用户微调属性转换,配置要使用的 Python 环境,并确定算法应操作的小数位数。为了学习本教程,请选择随机林分类器,并将所有内容保留为默认配置。单击“确定”将关闭窗口并返回到上一个选项卡。
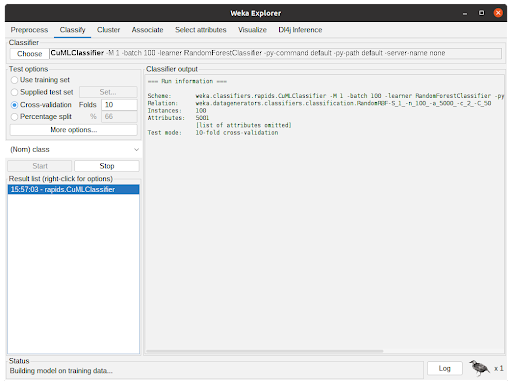
- 根据上一步配置分类器后,参数将显示在选择按钮旁边的文本字段中。单击开始后, WEKA 将开始使用数据集执行所选分类器。
图 6 显示了分类器的作用。分类器输出显示有关实验的调试和一般信息,例如参数、分类器、数据集和测试选项。状态显示执行的当前状态,底部的 Weka 鸟在实验运行时从一侧动画并翻转到另一侧。
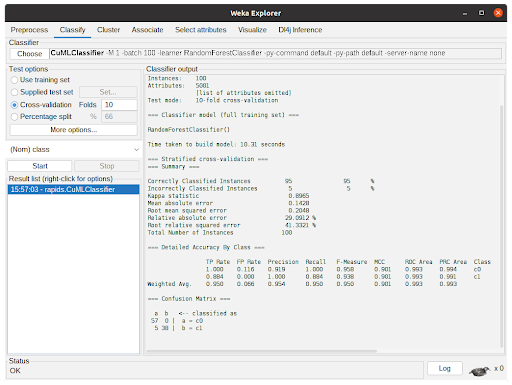
- 算法完成任务后,将输出执行摘要,其中包含有关预测性能和所用时间的信息。在图 7 中,输出显示了使用从 cuML 到 CuMLClassifier 的 RandomForestClassifier 进行 10 倍交叉验证的结果。
基准测试加速 WEKA
我们评估了加速 WEKA 的性能,比较了算法在 CPU 上的执行时间和使用加速 WEKA 的执行时间。实验中使用的硬件是 i7-6700K 、 GTX 1080Ti 和具有四个 A100 GPU 的 DGX 站。除非另有说明,否则基准测试使用单个 GPU 。
我们使用具有不同特征的数据集作为基准。其中一些是合成的,用于更好地控制属性和实例,如 RDG 和 RBF 生成器。 RDG 生成器基于决策列表构建实例。默认配置有 10 个属性, 2 个类,最小规则大小为 1 ,最大规则大小为 10 。我们将最小值和最大值分别更改为 5 和 20 。使用该生成器,我们创建了具有 1 、 2 、 5 和 1000 万个实例的数据集,以及具有 20 个属性的 500 万个实例。
RBF 生成器为每个类创建一组随机中心,然后通过获取属性值中心的随机偏移来生成实例。属性的数量用后缀 a _ uu 表示(例如, a5k 表示 5000 个属性),实例的数量用后缀 n _ u 表示(例如, n10k 表示 10000 个实例)。
最后,我们使用了 HIGGS 数据集 ,其中包含有关原子加速器运动学特性的数据。希格斯数据集的前 500 万个实例用于创建希格斯粒子。
显示了 weka RAPIDS 积分的结果,其中我们直接比较了基线 CPU 执行和加速 weka 执行。 WDL4J 的结果如表 5 所示。
| XGBoost (CV) | i7-6700K | GTX 1080Ti | Speedup |
| dataset | Baseline (seconds) | AWEKA SGM (seconds) | |
| RDG1_1m | 266.59 | 65.77 | 4.05 |
| RDG1_2m | 554.34 | 122.75 | 4.52 |
| RDG1_5m | 1423.34 | 294.40 | 4.83 |
| RDG1_10m | 2795.28 | 596.74 | 4.68 |
| RDG1_5m_20a | 2664.39 | 403.39 | 6.60 |
| RBFa5k | 17.16 | 15.75 | 1.09 |
| RBFa5kn1k | 110.14 | 25.43 | 4.33 |
| RBFa5kn5k | 397.83 | 49.38 | 8.06 |
| XGBoost (no-CV) | i7-6700K | GTX 1080Ti | Speedup | A100 | Speedup |
| dataset | Baseline (seconds) | AWEKA CSV (seconds) | AWEKA CSV (seconds) | ||
| RDG1_1m | 46.40 | 21.19 | 2.19 | 22.69 | 2.04 |
| RDG1_2m | 92.87 | 34.76 | 2.67 | 35.42 | 2.62 |
| RDG1_5m | 229.38 | 73.49 | 3.12 | 65.16 | 3.52 |
| RDG1_10m | 461.83 | 143.08 | 3.23 | 106.00 | 4.36 |
| RDG1_5m_20a | 268.98 | 73.31 | 3.67 | – | |
| RBFa5k | 5.76 | 7.73 | 0.75 | 8.68 | 0.66 |
| RBFa5kn1k | 23.59 | 13.38 | 1.76 | 19.84 | 1.19 |
| RBFa5kn5k | 78.68 | 34.61 | 2.27 | 29.84 | 2.64 |
| HIGGS_5m | 214.77 | 169.48 | 1.27 | 76.82 | 2.80 |
| RandomForest (CV) | i7-6700K | GTX 1080Ti | Speedup |
| dataset | Baseline (seconds) | AWEKA SGM (seconds) | |
| RDG1_1m | 494.27 | 97.55 | 5.07 |
| RDG1_2m | 1139.86 | 200.93 | 5.67 |
| RDG1_5m | 3216.40 | 511.08 | 6.29 |
| RDG1_10m | 6990.00 | 1049.13 | 6.66 |
| RDG1_5m_20a | 5375.00 | 825.89 | 6.51 |
| RBFa5k | 13.09 | 29.61 | 0.44 |
| RBFa5kn1k | 42.33 | 49.57 | 0.85 |
| RBFa5kn5k | 189.46 | 137.16 | 1.38 |
| KNN (no-CV) | AMD EPYC 7742 (4 cores) | NVIDIA A100 | Speedup | 4X NVIDIA A100 | Speedup |
| dataset | Baseline (seconds) | wekaRAPIDS (seconds) | wekaRAPIDS (seconds) | ||
| covertype | 3755.80 | 67.05 | 56.01 | 42.42 | 88.54 |
| RBFa5kn5k | 6.58 | 59.94 | 0.11 | 56.21 | 0.12 |
| RBFa5kn10k | 11.54 | 62.98 | 0.18 | 59.82 | 0.19 |
| RBFa500n10k | 2.40 | 44.43 | 0.05 | 39.80 | 0.06 |
| RBFa500n100k | 182.97 | 65.36 | 2.80 | 45.97 | 3.98 |
| RBFa50n10k | 2.31 | 42.24 | 0.05 | 37.33 | 0.06 |
| RBFa50n100k | 177.34 | 43.37 | 4.09 | 37.94 | 4.67 |
| RBFa50n1m | 21021.74 | 77.33 | 271.84 | 46.00 | 456.99 |
| 3,230,621 params Neural Network | i7-6700K | GTX 1080Ti | Speedup |
| Epochs | Baseline (seconds) | WDL4J (seconds) | |
| 50 | 1235.50 | 72.56 | 17.03 |
| 100 | 2775.15 | 139.86 | 19.84 |
| 250 | 7224.00 | 343.14 | 21.64 |
| 500 | 15375.00 | 673.48 | 22.83 |
该基准测试表明,加速 WEKA 为具有较大数据集的计算密集型任务提供了最大的好处。像 RBFa5k 和 RBFa5kn1k 这样的小数据集(分别拥有 100 个和 1000 个实例)呈现出糟糕的加速,这是因为数据集太小,无法使将内容移动到 GPU 内存的开销值得。
这种行为在 A100 (表 4 )实验中很明显,其中架构更为复杂。使用它的好处开始在 100000 个实例或更大的数据集上发挥作用。例如,具有 100000 个实例的 RBF 数据集显示了约 3 倍和 4 倍的加速,这仍然不太明显,但显示出了改进。更大的数据集,如 covertype 数据集(约 700000 个实例)或 RBFa50n1m 数据集( 100 万个实例),分别显示了 56X 和 271X 的加速。请注意,对于深度学习任务,即使使用 GTX 1080Ti ,加速也可以达到 20 倍以上。
关键要点(与行动要求挂钩)
加速 WEKA 将帮助您使用激流为 WEKA 增压。加速 WEKA 有助于 RAPIDS 的高效算法实现,并具有易于使用的 GUI 。使用 Conda 环境简化了安装过程,从一开始就可以直接使用加速 WEKA 。
如果您使用 AcceleratedWEKA ,请在社交媒体上使用标签“ AcceleratedWEKA ”。此外,请参阅 文档 以获取在学术工作中引用加速 WEKA 的正确出版物,并了解有关该项目的更多详细信息。
加速 WEKA
WEKA 在 GPL 开源许可证 下免费提供,因此加速了 WEKA 。事实上, Accelerated WEKA 是通过 Conda 提供的,用于自动安装环境所需的工具,对源代码的添加将发布到 WEKA 的主包中。贡献和错误修复可以作为补丁文件贡献并发布到 WEKA 邮件列表 。
致谢
我们要感谢来自 NVIDIA 的 Ettikan Karuppiah 、 Nick Becker 、 Brian Kloboucher 和 Johan Barthelemy 博士在项目执行期间提供的技术支持。他们的见解对于帮助我们实现与 RAPIDS 库高效集成的目标至关重要。此外,我们要感谢 Johan Barthelemy 在额外的图形卡中运行基准测试。




