量子计算渴望在更快的时间内为目前无法用经典计算解决的问题提供更强大的计算能力。 NVIDIA 最近发布了 cuQuantum SDK ,这是一个用于加速量子信息科学发展的高性能库。 cuQuantum 最近被用于 打破在 DGX SuperPOD 上运行 MaxCut 量子算法模拟的世界纪录 ,比以前的工作多了 8 倍的量子位。
cuQuantum 的初始目标应用程序是 量子电路模拟, 的加速,它由两个主要库组成:
- cuStateVec :加速状态向量模拟。
- cuTensorNet :加速张量网络模拟。
在本文中,我们将对这两个库进行概述,并对 cuTensorNet 进行更详细的讨论。
为什么要使用 cuStateVec ?
cuQuantum SDK 中的 cuStateVec 库通过针对模拟器中出现的大多数用例优化 GPU 内核,为基于状态向量的模拟提供了高性能解决方案。虽然状态向量法非常适合运行深度量子电路,但即使在当今最大的超级计算机上,也不可能对具有大量量子比特的量子电路进行模拟,这些量子比特呈指数增长。
为什么要使用 cuTensorNet ?
作为替代方案,张量网络方法是一种将 N 量子位的量子态表示为一系列张量收缩的技术。这使得量子电路模拟器能够通过交换算法与计算所需的空间来处理具有许多量子位的电路。根据电路拓扑和深度的不同,这也可能会变得非常昂贵。然后,主要的挑战是有效地计算这些张量收缩。

cuQuantum SDK 中的 cuTensorNet 库为这些类型的张量网络计算提供了高性能解决方案。
cuTensorNet 库提供 C 和 Python API ,以提供对高性能张量网络计算的访问,从而加速量子电路模拟。这些 API 非常灵活,使您能够控制、探索和研究实现的每一种算法技术。
cuTensorNet 算法描述
在本节中,我们将讨论 cuTensorNet 中使用的不同算法和技术。它包括两个主要组件: pathfinder 和 execution 。
pathfinder 在短时间内提供了一条成本最低的最佳收缩路径,执行步骤使用高效内核在 GPU 上计算该路径。这两个组件相互独立,可以与提供类似功能的任何其他外部库进行互操作。
探路者
在高层, cuTensorNet 采用的方法是围绕基于图形分区的探路者进行超优化。有关更多信息,请参阅 超优化张量网络收缩 。
探路者的作用是找到一条收缩路径,使收缩张量网络的成本最小化。为了加快这一步,我们开发了许多算法改进和优化,而且这一步还会更快。
寻找最优收缩路径在很大程度上取决于网络的大小。网络越大,寻找最优收缩路径所需的技术和计算量就越大。
cuTensorNet pathfinder 由三个算法模块组成(图 2 )。

- Simplification :对张量网络进行预处理以找到所有明显的直接收缩集的技术。它将它们从网络中移除,并用其最终张量替换每个集合。其结果是更小的网络,更容易在以下模块中处理。
- Path computation :探路者组件的核心。它基于一个图分区步骤,然后是使用重新配置调整和切片技术的第二个步骤。递归地调用图分区来分割网络并形成收缩路径(例如,成对收缩树)。
- Hyper-optimizer: 路径计算模块上的一个循环,在每次迭代中形成一条收缩路径。对于每次迭代,超级优化器都会为路径计算创建不同的参数配置,同时跟踪找到的最佳路径。您可以随意更改或修复这些配置参数。所有配置参数都可以通过
cutensornetContractionOptimizerConfigSetAttribute设置。有关更多信息,请参阅 cuTensorNet documentation 。
从第一步生成的路径可能不接近最优,因此通常会执行重构调整。重构在整体收缩树中选择几个小的子树,并试图提高它们的收缩成本,如果可能的话,降低总体成本。
路径计算模块的另一个特点是切片技术。切片的主要目标是将网络收缩过程放入可用的设备内存中。切片通过排除某些张量模式并显式展开它们的范围来实现这一点。这将生成许多类似的收缩树,或 slices ,其中每一个对应于排除模式之一。
收缩路径或树不会改变。在这种情况下,只有一些模式被排除在外,每个切片的计算独立于其他模式。因此,切片可以被认为是为不同设备创建独立工作的最佳技术之一。
实践经验表明,找到最佳收缩路径对这里使用的每种技术的配置参数的选择都很敏感。为了提高找到最佳收缩路径的概率,我们将该模块封装在一个超级优化器中。
寻路性能
在考虑探路者的性能时,有两个相关的指标:找到的路径的质量和找到该路径所需的时间。前者如图 3 所示,以失败导致的收缩成本来衡量。用于基准测试的电路是谷歌量子人工智能 2019 年量子优势论文 的随机量子电路,深度为 12 、 14 和 20 。
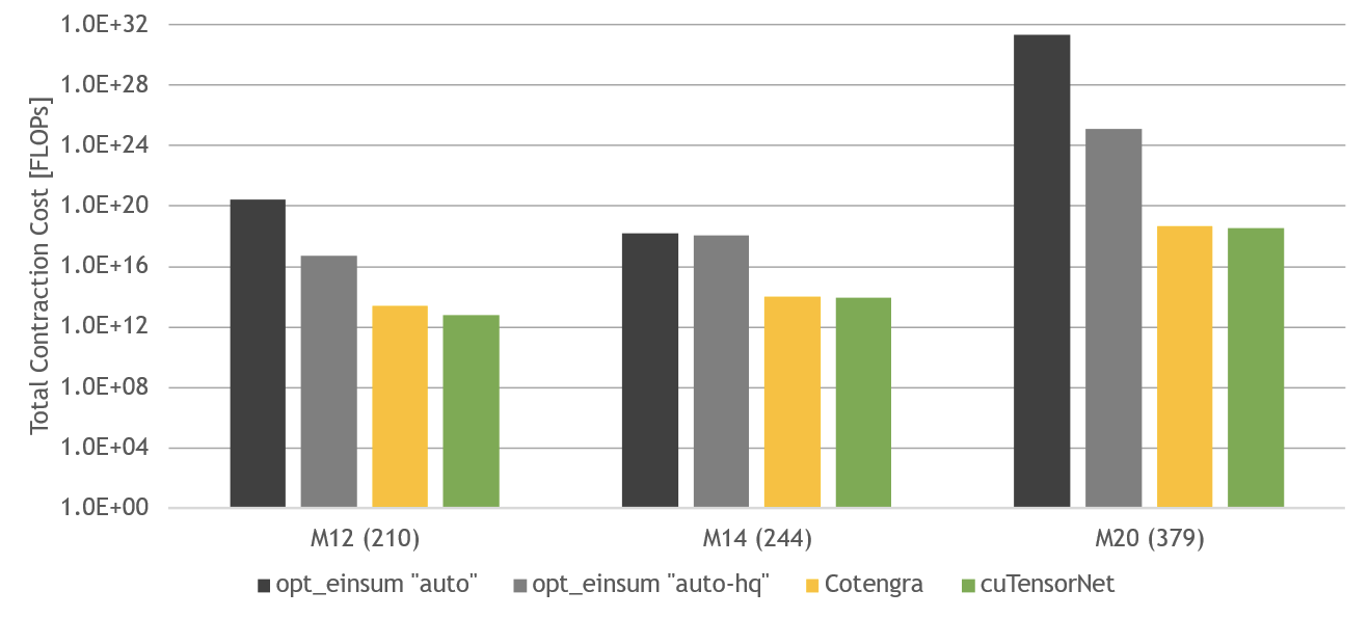
与 opt_einsum 库相比, cuTensorNet 在寻找最佳路径方面表现良好,在这些电路方面略优于 Cotengra 。
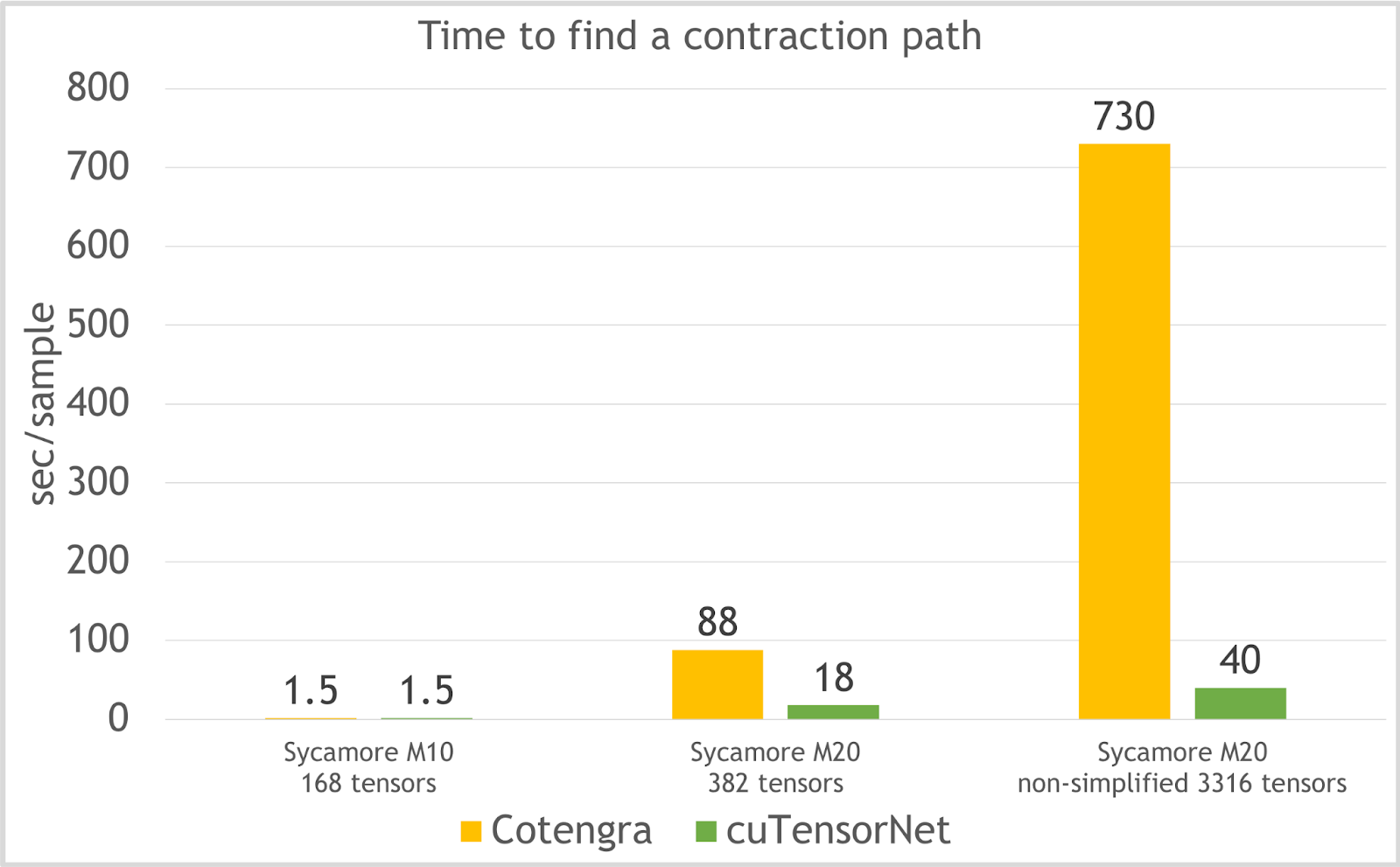
cuTensorNet 也能快速找到高质量的路径。对于不同深度的悬铃木量子电路问题,图 4 绘制了 cuTensorNet 与科滕格拉相比的收缩所需时间。对于网络中有 3000 多个张量的最复杂问题, cuTensorNet 仍能在 40 秒内找到最佳路径。
处决
执行组件依赖 cuTENSOR 库作为后端,以便在 GPU 上高效执行。它包括以下几个阶段:
- Planning :执行组件的决策引擎。它分析收缩路径,决定使用最小工作空间在 GPU 上执行它的最佳方式。它还决定了每个成对收缩使用的最佳内核。
- Computation :此阶段使用 cuTENSOR 库计算所有成对收缩。
- Autotuning :(可选)基于不同启发式的不同内核尝试成对收缩,并选择最佳内核。
执行性能
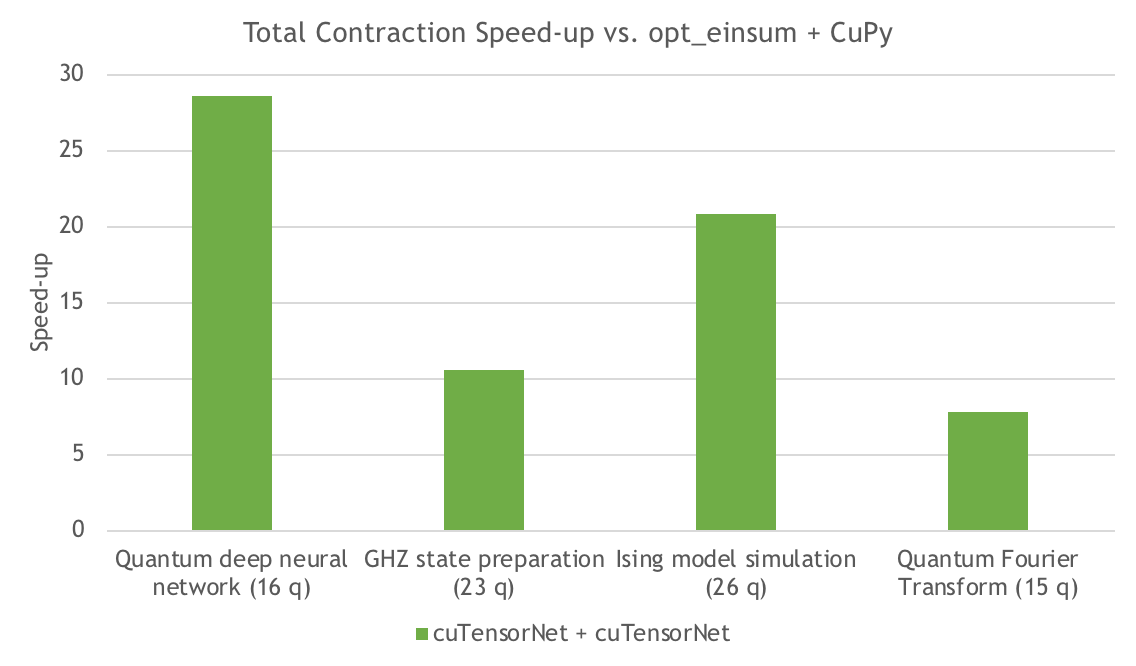
图 5 测量了 cuTensorNet 与 CuPy 在几个不同电路中收缩执行的加速比。根据赛道的不同, cuTensorNet 提供了约 8-20 倍的收缩执行加速。
cuTensorNet 示例
cuTensorNet 提供了 C 和 Python API ,允许您高效地计算张量网络收缩,而无需任何关于如何找到最佳收缩路径或如何在 GPU 上执行收缩的专业知识。
高级 Python API
cuTensorNet 提供高级 Python API ,可与 NumPy 和 PyTorch 张量互操作。例如,张量网络的einsum表达式可以在对contract的单个函数调用中使用。 cuTensorNet 执行所有必需的步骤,结果返回约定的网络。
import cupy as cp
import cuquantum # Compute D_{m,x,n,y} = A_{m,h,k,n} B_{u,k,h} C_{x,u,y} # Create an array of extents (shapes) for each tensor extentA = (96, 64, 64, 96) extentB = (96, 64, 64) extentC = (64, 96, 64) extentD = (96, 64, 96, 64) # Generate input tensor data directly on GPU A_d = cp.random.random(extentA, dtype=cp.float32) B_d = cp.random.random(extentB, dtype=cp.float32) C_d = cp.random.random(extentC, dtype=cp.float32) # Set the pathfinder options options = cuquantum.OptimizerOptions() options.slicing.disable_slicing = 1 # disable slicing options.samples = 100 # number of hyper-optimizer samples # Run the contraction on a CUDA stream stream = cp.cuda.Stream() D_d, info = cuquantum.contract( 'mhkn,ukh,xuy->mxny', A_d, B_d, C_d, optimize=options, stream=stream, return_info=True) stream.synchronize() # Check the optimizer info print(f"{info[1].opt_cost/1e9} GFLOPS")
从这个代码示例中,您可以看到所有 cuTensorNet 操作都封装在一个contract API 中。本例的输出为 14.495514624 GFLOPS :基于路径查找器找到的收缩路径估计的浮点操作数。要手动执行相同的步骤,还可以使用 cuQuantum.Network object 。
低级 API
如前所述, C 和 Python API 是以一种直观的表达方式设计的。您可以调用 pathfinder 函数以获得优化的路径,然后调用以使用该路径在 GPU 上执行收缩。
对于高级用户, cuTensorNet library API 旨在授予访问该领域研究可用的所有算法选项的权限。例如,您可以控制 pathfinder 可以尝试找到最佳收缩路径的 hyper optimizer 样本数。
有几十个参数可以修改或控制。这些都可以通过 helper 函数访问,并允许简单功能 API 保持不变。你也可以提供自己的路径。有关较低级别选项的更多信息以及如何使用它们的示例,请参阅 cuquantum.Network 。
总结
NVIDIA CuQuin SDK 的 CursSnReNET 库旨在加速 GPU 上的张量网络计算。在这篇文章中,我们展示了最先进的张量网络库对关键量子算法的加速。
在改进 cuTensorNet 并通过新的算法改进和多节点、多 GPU 执行来扩展它方面有着广泛的发展。
cuTensorNet 图书馆的目标是为量子计算领域的突破性发展提供一个有用的工具。有没有关于如何改进 cuQuantum 库的反馈和建议?发送电子邮件至 cuquantum-feedback@nvidia.com 。
有关更多信息,请参阅以下参考资料:
- cuQuantum beta (包括 Cutensornet )
- cuQuantum documentation
- NVIDIA/cuQuantum GitHub




