RAPIDS Apache 的加速器 Spark v21 。现在有 10 个!作为一个开源项目,我们重视我们的社区、他们的声音和请求。此版本构成了社区对最适合 GPU 加速的操作的请求。
此版本的重要标注:
- Speed up –性能改进和成本节约。
- New Functionality –新的 I / O 和嵌套数据类型鉴定和分析工具功能。
- Community Updates – 对 spark-examples repository 的更新。
加快
用于 Apache 的 RAPIDS 加速器 Spark 在功能和性能方面都以惊人的速度增长。标准行业基准是衡量一段时间内绩效的好方法,但衡量绩效的另一个晴雨表是衡量数据预处理阶段或数据分析中使用的普通操作员的绩效。
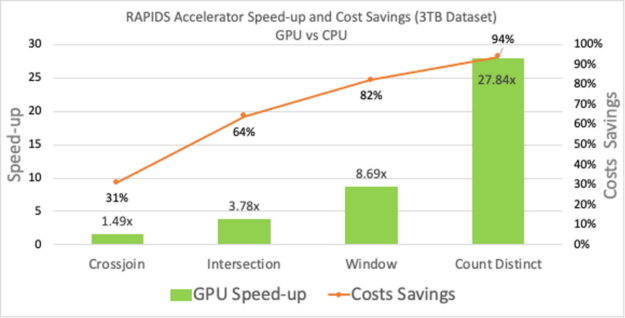
我们使用了如下表所示的四个此类查询:
- Count Distinct :用于估计访问电子商务站点的唯一页面浏览量或唯一客户数的函数。
- Window: 在分析市场营销或金融行业的时间戳事件数据时,对组件进行预处理所需的关键操作员。
- Intersect: 用于删除数据帧中的重复项的运算符。
- Cross-join: 交叉联接的一个常见用途是获取项目的所有组合。
这些查询在谷歌云平台( GCP )机器上运行,每台机器有 2xT4 GPU 和 104GB 内存。使用的数据集大小为 3TB ,具有多种不同的数据类型。有关设置和查询的更多信息可以在 GitHub 上的 spark-rapids-examples 存储库中找到。这四个查询不仅显示了性能和成本优势,而且速度范围( 27 倍到 1.5 倍)因计算强度而异。这些查询的计算和网络利用率不同,类似于数据预处理中的实际用例。
新功能
插入
大多数 Apache Spark 用户都知道 Spark 3.2 于今年 10 月发布。 v21 。 10 版本支持 Spark 3.2 和 CUDA 11.4 。在这个版本中,我们着重于扩展对 I / O 、嵌套数据处理和机器学习功能的支持。 RAPIDS Apache 的加速器 Spark v21 。 10 发布了一个新的插件 jar ,以支持 Spark 中的机器学习。
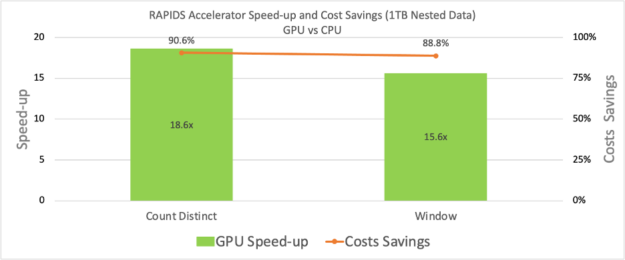
目前,该 jar 支持主成分分析算法的训练。 ETL jar 扩展了对拼花地板和 ORC 的输入类型支持。它现在还为用户提供了在嵌套数据上使用HashAggregate、Sort、JoinSHJ和Join BHJ的功能。除了支持嵌套数据类型外,还运行了性能测试。
在下图中,我们展示了使用嵌套数据类型输入的两个查询的速度。 v21 中添加的其他一些有趣的特性。 10 个是pos_explode、create_map等等。请参阅 RAPIDS Apache Spark 文档加速器 有关新功能的详细列表。
分析和鉴定工具
除了插件之外, ApacheSpark 鉴定和分析工具的 RAPIDS 加速器还添加了多个新功能。鉴定工具现在可以报告存在的不同嵌套数据类型和写入数据格式。它现在还支持添加连接和分离过滤器,以及基于过滤器的正则表达式和用户名。
资格鉴定工具并不是唯一一个具有新技巧的工具:分析工具现在提供结构化输出格式,并支持扩展和运行大量事件日志。
社区更新
我们很高兴地宣布我们进入了 Azure 上的公开预览 ,我们欢迎 Azure 用户在 Azure Synapse 上尝试 RAPIDS 加速版 Apache Spark 。
我们邀请您观看我们在 11 月 8 日至 11 日举行的 NVIDIA 旗舰活动 GTC 上的演讲,了解 AI 如何改变世界。 RAPIDS 加速器团队进行了两次会谈; 加速 ApacheSpark 概述了新功能和其他即将推出的功能。而且 通过 RAPIDS 和 NVIDIA RAPIDS 发现常见的 Apache GPU 操作 涵盖 Apache Spark 上的许多微基准。
马上就来
即将发布的版本将引入对 128 位十进制数据类型的支持、对主成分分析算法的推理支持以及对多级结构和映射的额外嵌套数据类型支持。
此外,请注意对基于 NVIDIA 安培体系结构的 GPU ( A100 / A30 )的 MIG 支持,这有助于提高使用 A100 运行多个 Spark 作业的吞吐量。和往常一样,我们要感谢你们所有人使用 RAPIDS Apache 加速器 Spark ,我们期待收到你们的来信。请在 GitHub 上与我们联系,让我们知道如何在 Apache Spark 上使用 RAPIDS 加速器继续改进您的体验。