
QHack 是一个教育会议,也是世界上最大的量子机器学习( QML )黑客马拉松。今年QHack 2023,来自 105 个不同国家的 2850 人参加了为期 8 天的比赛,为量子计算使用 NVIDIA 量子技术的应用程序。
活动由组织Xanadu,NVIDIA 赞助 QHack 2023 NVIDIA 挑战赛。作为挑战的一部分,顶级团队获得了由 NVIDIA 量子软件组成的 NVIDIA Quantum 平台的访问权限。其中包括 NVIDIAcuQuantum SDK以及 NVIDIA 的早期访问版本CUDA Quantum,现在有开源版本。这两个工具都针对世界上最强大的 NVIDIA GPU 进行了优化,与训练时使用的 GPU 相同ChatGPT.
QHack NVIDIA 挑战
为了支持 NVIDIA 挑战赛,Cyxtera提供了三个位于全球各地的 DGX A100 电台,以及Run:ai提供了用户管理和编排界面。排名前 72 的团队获得了一个独立的 NVIDIA A100 80 GB GPU ,每天 6 小时的使用权。
活动开始几天,团队被要求提交他们正在进行的项目,以供考虑增加电源。此时,其中 36 个团队获得了 CUDA Quantum 的私人测试版访问权限。此外,排名前 24 的团队还获得了第二个 NVIDIA A100 80 GB GPU
NVIDIA 挑战赛的参与者建造了 23 个令人难以置信的项目,包括但不限于:
- 量子混合现实
- 用于天气预报的 QML
- 基因组错误校正和重新测序
- 机器学习( ML )设计更好的变分量子算法
- 时空虫洞的量子动力学模拟
这些项目是根据创新理念、科学严谨性和基于 GPU 的模拟器和工作流程的能力进行评分的。
获奖项目强调量子计算用例
NVIDIA 挑战赛的前三名获奖项目(详见下文)授予了最严格的科学探索,并在允许的时间内进行了良好的性能优化和演示
第一名:使用 PennyLane Lightning 和 NVIDIA cuQuantum SDK 加速噪声算法研究
MFC 团队,由Lion Frangoulis,Cristian Emiliano Godínez Ramírez,Emily Haworth和Aaron Sander,在 NVIDIA 挑战赛中获得第一名。 MFC 团队的项目,Accelerating Noisy Algorithm Research with PennyLane-Lightning and NVIDIA cuQuantum SDK使用 PennyLane Lightning-GPU 插件和 NVIDIA cuQuantum SDK 解决了噪声模拟的计算复杂性
这项工作对于任何有兴趣在真实量子处理单元( QPU )上运行算法的人来说都至关重要。通过了解目标系统中存在的噪声源,开发人员可能能够设计模拟物来减轻噪声,甚至利用噪声
MFC 团队的工作依赖于 Trotter Suzuki 分解来近似哈密顿量的演化。通过在每次 CNOT 操作之后注入去极化噪声通道来对噪声进行建模。接下来,该团队使用变分量子本征解器( VQE )探索了这种噪声对寻找横向场海森堡模型基态的影响。
正如人们可能预期的那样,高水平的噪声导致了不稳定的解决方案。但最有趣的是,与图 1 所示的无噪声运行相比,中等水平的噪声可以导致更快、更准确的收敛
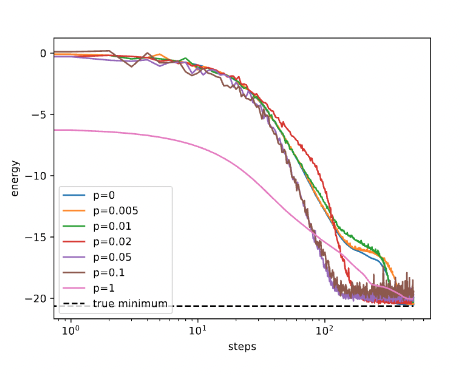
MFC 团队将他们的流程向前推进了一步,并进行了比较PennyLane Lightning Qubit( CPU – 状态向量模拟器)PennyLane-Lightning-GPU( GPU – 支持的状态向量模拟器cuQuantum) 与PennyLane default.mixed simulator后端通过本机密度矩阵后端
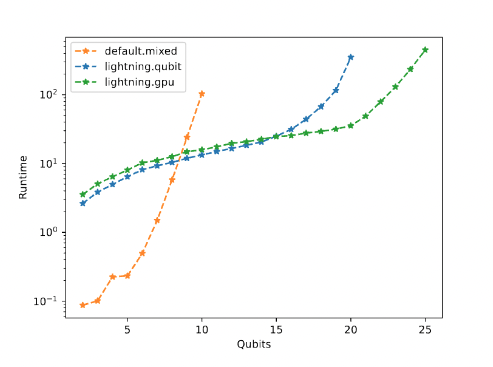
为了进行苹果对苹果的比较,该团队探索了改变轨迹数量对随机噪声算法保真度的影响。他们的探索表明,使用大约 200 条轨迹就足够了。 MFC 随后实现了不同量子位计数的各种后端的基准。很明显, PennyLane Lightning- GPU 非常适合更大的模拟,其性能优于 15 个量子位以上的 CPU 模拟器
该项目表明,对噪声量子电路的模拟是探索 NISQ 设备硬件高效替代品的宝贵工具
第二名:用于恒星分类的量子增强支持向量机
Louis Chen,Henry Makhanov和Felix Xu的团队因其对Quantum-Enhanced Support Vector Machines for Stellar Classification.
恒星分类是一种基于恒星光谱数据的技术,用于对恒星进行分类。每种光谱类型都依赖于温度和光度,并且可以进一步划分为光度类别。还包括化学成分。由于数据的性质,人类分类很难标准化,这就是 ML 模型被广泛用于该任务的原因
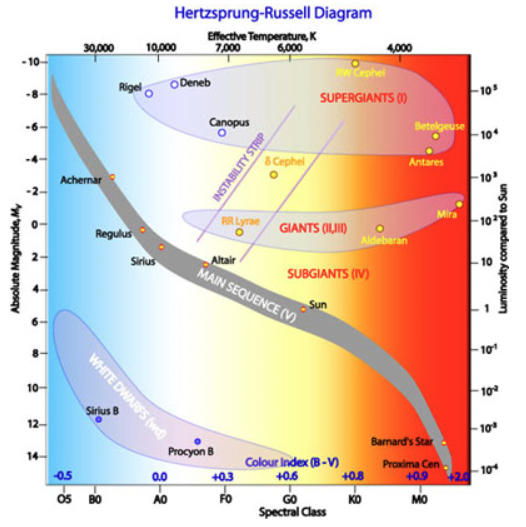
Durchmusterung 团队探讨了这些最先进的方法与量子支持向量机( QSVM )的比较。赫罗图是研究恒星演化及其分类的常用工具。请参见图 3 ,了解由人类完成这一过程的复杂程度,有时是主观的。
虽然量子 SVM 很有前途,但这些方法仍然需要经典的预处理和后处理。为了实现该 ML 模型的量子核方法,需要特征工程来降低数据集的维数,并提取可能对计算负载或模型精度产生负面影响的某些特征。
在为量子核学习准备好数据集后, Durchmusterung 在准确性、敏感性和特异性等多个指标上探索了其与经典 SVM 相比的有效性。这种方法的目标是确定量子核是否可以与正在研究的经典方法竞争
很明显,该模型具有竞争性的准确性,同时始终优于所研究的经典模型的特异性。量子模型的灵敏度也比经典模型略强,这表明这种方法在规模上是有用的
Durchmusterung 还探索了其他经典的基准测试模型,如 k 近邻( KNN )和逻辑回归。他们发现,虽然这些方法在二元分类中取得了成功,准确率约为 86% ,但在多标记分类中,准确率降至约 78% 。量子核模型能够实现大约 81% 的精度
总的来说,这一探索证明了团队的辛勤工作以及 NVIDIA 量子平台为 QML 和量子电路模拟提供的价值。
第三名:强化学习量子局部搜索
2023 年 QHack NVIDIA 挑战赛的三等奖授予了 TaipeiQCReinforcement Learning Quantum Local Search。两人团队,由Chen-Yu Liu和 Ya Chi Lu ,考虑了量子局部搜索( QLS ),它利用小型 QPU 来解决具有一些随机起点的组合优化问题。他们研究了强化学习( RL )是否可以改善初始选择过程,从而使量子局部搜索表现更好
组合优化问题非常常见。路由优化(如旅行推销员问题)和资源分配(如投资组合优化)是组合优化问题的好例子。有许多方法试图用量子处理器来解决这些问题, QLS 就是其中之一
TaipeiQC 选择探索 32 、 64 和 128 个变量的组合 Ising 问题,每个问题都有一个五变量解算器。 TaipeiQC 利用近端策略优化( PPO )方法来培训其代理,生成了问题图和历史配置数据,以帮助策略网络了解其可以采取行动的状态
该团队不仅限于此,他们还探索了重要性加权参与者学习架构( IMPALA )进行培训
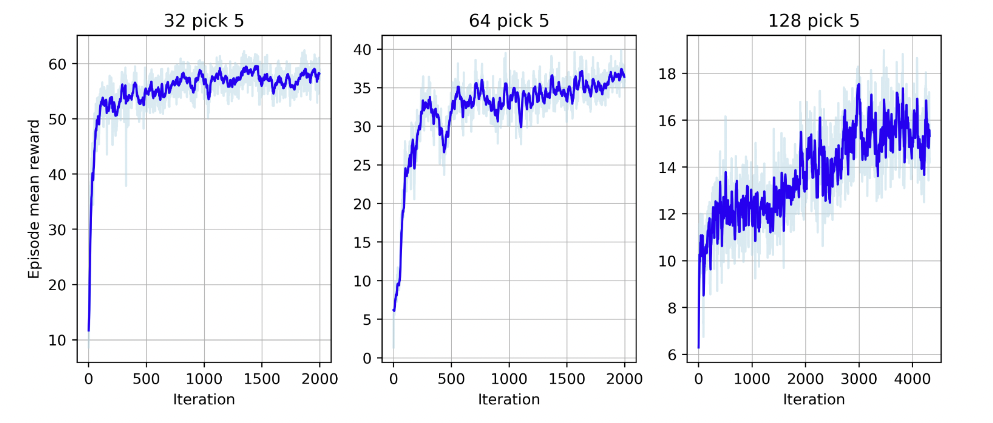
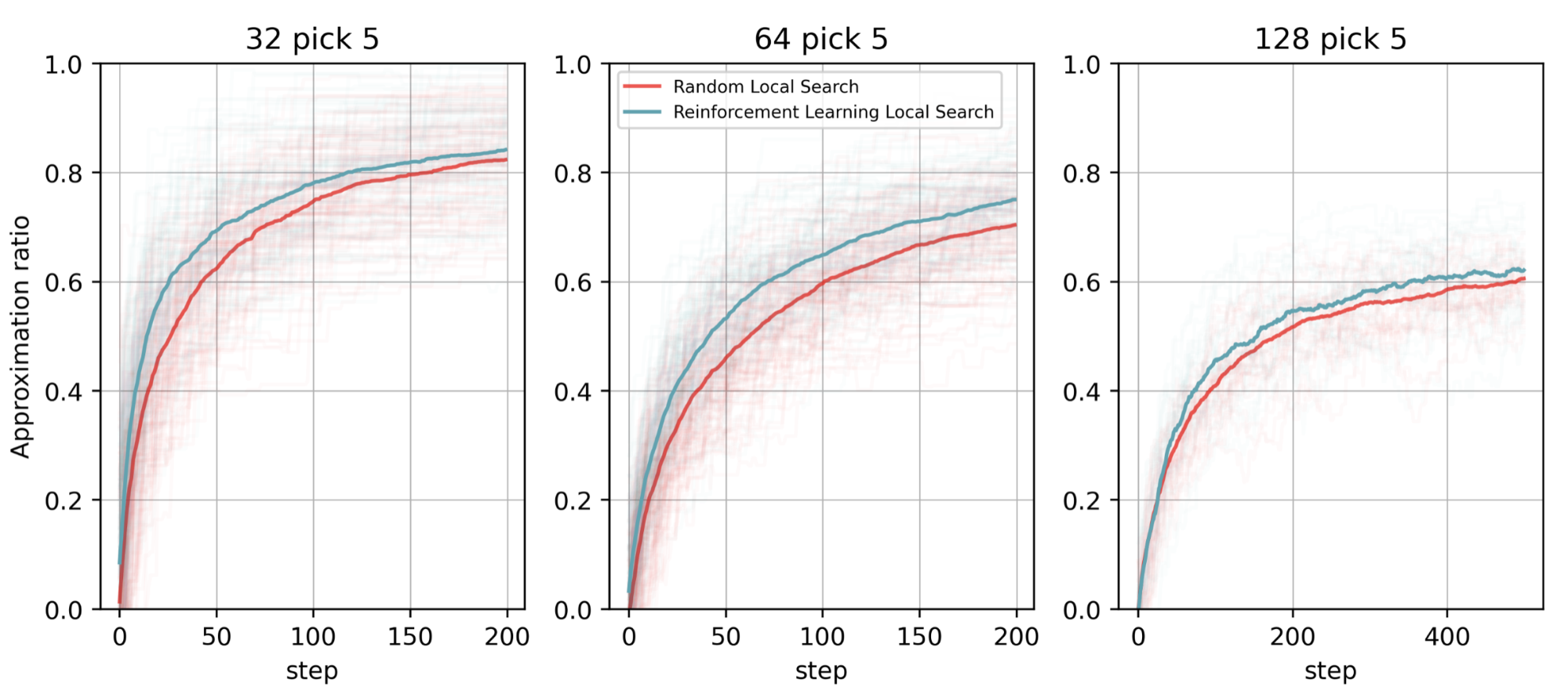
平均回报越高越好,在所有这些情况下, RL-QLS 方法的性能都比 QLS 好,在每种情况下都有更好的近似率(图 6 )。应用 ML 技术来设计更好的量子算法是 ML 和量子计算之间有趣的交叉点
正如 TaipeiQC 项目所表明的那样,将这些技术应用于量子算法设计是有希望的。 NVIDIA GPU 和 NVIDIA Quantum 平台对于此类工作负载至关重要。
NVIDIA 量子计算
我们很高兴看到所有 QHack 2023 项目将进行哪些后续工作。 NVIDIA 提供的技术是加速此类算法开发和实现的关键。更快的吞吐量使研究人员和开发人员能够以前所未有的规模和速度进行创新
要了解更多关于量子计算应用程序和参与者在 QHack 2023 期间可访问的技术的信息,请查看NVIDIA cuQuantum和NVIDIA CUDA Quantum.




