欺诈是许多金融服务公司的一个主要问题,据最近的一份报告 Federal Trade Commission report 称,每年损失数十亿美元。财务欺诈、虚假评论、机器人攻击、账户接管和垃圾邮件都是在线欺诈和有害活动的例子。
尽管这些公司采用技术打击在线欺诈,但这些方法可能有严重的局限性。简单的基于规则的技术和基于特征的算法技术(逻辑回归、贝叶斯信念网络、 CART 等)不足以检测所有欺诈或可疑的在线行为。
例如,欺诈者可能会建立许多协调账户,以避免触发对个人账户的限制。此外,由于要筛选的数据量巨大(数十亿行,数十 TB ),不断改进方法的复杂性,以及训练分类算法所需的欺诈活动真实案例的稀缺性,大规模检测欺诈行为模式很困难。有关更多详细信息,请参阅 Intelligent Financial Fraud Detection Practices: An Investigation 。
虽然欺诈的成本每年高达数十亿美元,但在许多合法交易中,欺诈交易很少,导致标记数据的不平衡,即使数据是可用的。由于个人数据的安全问题以及检测欺诈活动所用方法的透明度的需要,金融服务行业的欺诈检测变得更加复杂。
一个可解释的模型使欺诈分析人员能够了解分析中使用的算法输入内容以及标记交易的原因,从而在系统中建立更强的信任。其他好处包括能够向内部团队传达反馈并向客户提供解释。
近年来,图形神经网络( GNN )在欺诈检测问题上获得了广泛的应用,通过不同的关系聚合其邻域信息,从而揭示可疑节点(例如在账户和交易中)。换言之,通过检查某个特定账户过去是否向可疑账户发送了交易。
在欺诈检测的背景下, GNN 能够聚合包含在交易本地邻居中的信息,这使它们能够识别仅查看单个交易可能会遗漏的较大模式。
为了使开发人员能够快速利用 GNN 来优化和加速欺诈检测, NVIDIA 与深度图形库( DGL )团队和 PyTorch 几何( PyG )团队合作,提供了一个 GNN framework containerized solution ,其中包括最新的 DGL 或 PyG 、 PyTorch 、 NVIDIA -RAPIDS 和一组经测试的依赖项。 NVIDIA 优化的 GNN 框架容器针对 NVIDIA GPU 进行了性能调整和测试。
这种方法消除了管理包和依赖项或从源代码构建框架的需要。我们正在积极致力于提高这些顶级 GNN 框架的性能。我们添加了 GPU 对统一虚拟寻址( UVA )、 FP16 操作、邻域采样、小批量子图操作和优化稀疏嵌入、稀疏 adam 优化器、图形批处理、 CSR 到 COO 转换等的支持。
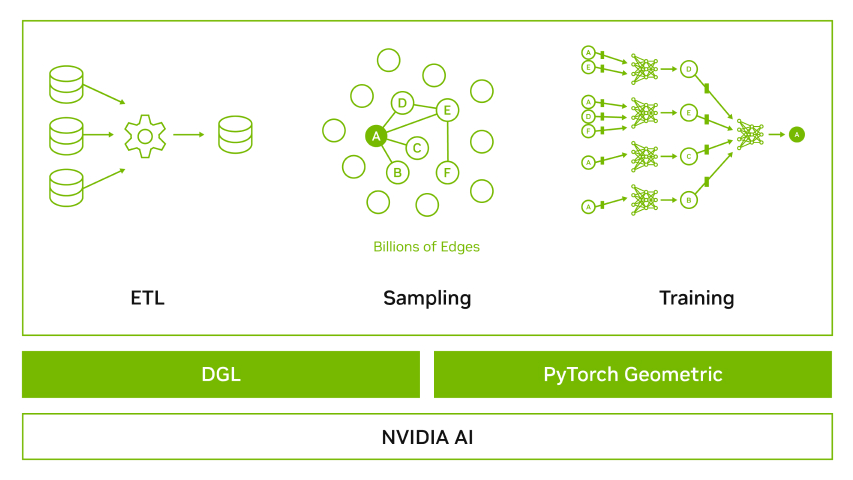
本文首先讨论了信用卡欺诈检测中的独特问题和最广泛使用的检测技术。它还强调了 GPU 加速的 GNN 如何以独特的方式解决这些问题。我们将介绍一个端到端的工作流,该工作流展示了使用图形神经网络在金融欺诈数据集上检测欺诈的预处理、培训和部署的最佳实践。最后,我们利用 NVIDIA 工程师在 DGL 中提供的优化,展示了两个行业级数据集上的端到端工作流基准。
欺诈检测概述
欺诈检测是一套流程和分析,使公司能够识别和防止未经授权的活动。它已成为大多数组织的主要挑战之一,尤其是银行、金融、零售和电子商务组织。
任何形式的欺诈都会对组织的底线和市场声誉产生负面影响,并阻碍未来的前景和当前的客户。鉴于这些脆弱组织的规模和影响范围,防止欺诈行为的发生,甚至实时预测可疑行为对它们来说至关重要。
欺诈检测给机器学习研究人员和工程师带来了独特的问题,下面详细介绍了其中的一些问题。
复杂且不断变化的欺诈模式
欺诈者更新他们的知识并开发复杂的技术来欺骗系统,通常涉及复杂的交易链以避免被发现。
传统的基于规则的系统和表格机器学习( ML ),如 SVM 和 XGBoost ,通常只能考虑交易的直接边缘(谁向谁发送了资金),往往会忽略具有更复杂背景的欺诈模式。随着欺诈模式的改变和新漏洞的出现,基于规则的系统也需要随着时间的推移进行手动调整。
标签质量
可用的欺诈数据集通常既不平衡又没有详尽的标签。在现实世界中,只有一小部分人打算实施欺诈。领域专家通常将交易分类为欺诈或非欺诈,但无法保证数据集中已捕获所有欺诈。
这种类别不平衡和缺乏详尽的标签使得开发监督模型变得困难,因为根据我们现有的标签训练的模型可能会导致更高的误报率,而不平衡的数据集也可能导致模型产生更多的误报。因此,用替代目标培训 GNN 并利用其下游潜在代表可以产生有益的效果。
模型可解释性
预测交易是否欺诈,不足以满足金融服务行业的透明度期望。还需要了解为什么某些交易被标记为欺诈。这一解释对于理解欺诈是如何发生的,如何实施政策以减少欺诈,以及确保过程没有偏见都很重要。因此,欺诈检测模型必须是可解释的,这限制了分析师可以使用的模型的选择。
欺诈检测的图形方法
一系列事务可以精确地描述为一个图形,用户被表示为节点,它们之间的事务被表示为边。虽然基于特征的算法(如 XGBoost )和基于深度特征的模型(如 DLRM )侧重于单个节点或边的特征,但基于图的方法可以在预测中考虑本地图上下文(例如,邻居和邻居的邻居)的特征和结构。
在传统(非 GNN )图域中,有许多方法可以基于图结构生成显著预测。聚集相邻节点或边缘,甚至其邻居的特征的统计方法,可用于向基于特征的表格算法(如 XGBoost )提供有关位置的信息。
像 Louvain method 和 InfoMap 这样的算法可以检测图形上的社区和更密集的用户簇,然后可以使用这些算法检测社区并生成将图形结构表示为层次结构的特征。
虽然这些方法可以产生足够的结果,但问题仍然是所使用的算法缺乏对图形本身的表达能力,因为它们不考虑图形的原生格式。
图形神经网络建立在模型中本地表示局部结构和特征上下文的概念之上。来自边缘和节点特征的信息通过聚合和消息传递到相邻节点来传播。
当执行多层图卷积时,这会导致节点的状态包含来自多层以外节点的一些信息,从而有效地允许 GNN 具有节点或边的“接受域”,这些节点或边可以多次跳离所讨论的节点或边。
在欺诈检测问题的背景下, GNN 的这个巨大的接受域可以解释欺诈者可以用于混淆的更复杂或更长的交易链。此外,模式的变化可以通过模型的迭代再培训来解释。
图形神经网络还受益于在无监督或自我监督任务(如 Bootstrapped Graph Latents (BGRL) 或 link prediction with negative sampling )上进行训练时,能够对节点或边的有意义表示进行编码。这允许 GNN 用户预先训练一个没有标签的模型,并在管道中稍后在更稀疏的标签上微调模型,或输出图形的强表示。表示输出可以用于下游模型,如 XGBoost 、其他 GNN 或集群技术。
GNN 还有一套工具,可以解释输入图形。某些 GNN 模型,如异构图 transformer ( HGT )和图形注意网络( GAT ),可以在 GNN 的每一层上跨节点的相邻边缘启用注意机制,允许用户识别 GNN 用于导出其最终状态的消息路径。即使 GNN 模型没有注意机制,也提出了多种方法来解释整个子图背景下的 GNN 输出,包括 GNNExplainer 、 PGExplainer 和 GraphMask 。
下一节将介绍端到端信用卡欺诈检测工作流。此工作流使用 TabFormer (卡片交易欺诈数据集),并针对链接预测任务的变化训练 R-GCN (关系图卷积网络)模型,以生成丰富的节点嵌入。这些节点嵌入被传递给下游 XGBoost 模型,该模型经过培训,随后执行欺诈检测。
然后可以轻松部署此 XGBoost 模型。训练的嵌入可以随后用于其他无监督技术,如集群,以识别未发现的使用模式,而无需标签。最后,我们将利用 NVIDIA 工程师在 DGL 中提供的优化,在两个行业级数据集上展示端到端工作流的基准。
使用 GNN 构建端到端欺诈检测工作流
数据预处理
我们使用 IBM 提供的 Tabformer dataset 演示此工作流。 TabFormer 数据集是真实金融欺诈检测数据集的合成近似值,包括:
- 2400 万笔独特交易
- 6000 家独特商户
- 100000 张独特卡
- 30000 个欺诈样本(占总交易量的 0.1% )
首先,使用预定义的工作流预处理数据集。该工作流利用 cuDF (一个 GPU DataFrame 库)对原始数据集执行特征转换,为图形构建做好准备。 cuDF 是 pandas 的替代品,可以直接在 GPU 上预处理数据。
在这个数据集中,card_id被定义为一个用户的一张卡。一个特定用户可以有多张卡,对应于此图的多个不同card_ids。merchant_id是特征“商家名称”的分类编码。对数据进行拆分,使培训数据为 2018 年之前的所有交易,验证数据为 2018 年间的所有交易以及测试数据为 2018 之后的所有交易。
# Read the dataset
data = cudf.read_csv(self.source_path)
data[“card_id”] = data[“user”].astype(“str”) + data[“card”].astype(“str”)
# Split the data based on the year
data["split"] = cudf.Series(np.zeros(data["year"].size), dtype=np.int8)
data.loc[data["year"] == 2018, "split"] = 1
data.loc[data["year"] > 2018, "split"] = 2
train_card_id = data.loc[data["split"] == 0, "card_id"]
train_merch_id = data.loc[data["split"] == 0, "merchant_id"]
从“ Amount ”中去掉“$”,将该值转换为浮点值。仅当card_id和merchant_id包含在列车数据集中时,才将其保留在验证和测试数据集中。
该图由card_id和merchant_id之间的事务边构成。
进一步预处理包括一个热编码 Use chip 功能,标签编码“ Is Fraud ?”特征,以及对商户州、商户城市、邮政编码和 MCC 的分类表示进行编码的目标。此外,“错误?”的可能值是一个热编码。
# Target encoding
high_card_cols = ["merchant_city", "merchant_state", "zip", "mcc"]
for col in high_card_cols:
tgt_encoder = TargetEncoder(smooth=0.001)
train_df[col] = tgt_encoder.fit_transform(
train_df[col], train_df["is_fraud"])
valtest_df[col] = tgt_encoder.transform(valtest_df[col])
# One hot encoding `use_chip`
oneh_enc_cols = ["use_chip"]
data = cudf.concat([data, cudf.get_dummies(data[oneh_enc_cols])], axis=1)
# Label encoding `is_fraud`
label_encoder = LabelEncoder()
train_df["is_fraud"] = label_encoder.fit_transform(train_df["is_fraud"])
valtest_df["is_fraud"] = label_encoder.transform(valtest_df["is_fraud"])
# One hot encoding the errors
exploded = data["errors"].str.strip(",").str.split(",").explode()
raw_one_hot = cudf.get_dummies(exploded, columns=["errors"])
errs = raw_one_hot.groupby(raw_one_hot.index).sum()
数据集经过预处理后,将数据集的表格格式转换为图形。
将表格数据建模为图形
将一个表(或多个表)转换为图形的中心是将现有表映射为两个结构的边、节点和特征。对于这个数据集,我们首先使用交易表在卡和商家之间创建边缘。在当代 GNN 框架中,图的边缘在基本级别上由成对的节点 ID 表示。根据边列表中包含的 ID ,节点是隐式的。
# Defining node type
for ntype in ["card", "merchant"]:
node_type = {MetadataKeys.NAME: ntype, MetadataKeys.FEAT: []}
self.node_types.append(node_type)
# Adding attributes of edge data
self.edge_data = dict()
self.edge_data["transaction"] = cudf.DataFrame({
MetadataKeys.SRC_ID: data["card_id"],
MetadataKeys.DST_ID: data["merchant_id"],})
# Defining features
features = []
for key in data.keys():
if key not in ["card_id", "merchant_id"]:
self.edge_data["transaction"][key] = data[key]
feat = {
MetadataKeys.NAME: key,
MetadataKeys.DTYPE: str(self.edge_data["transaction"][key].dtype),
MetadataKeys.SHAPE: self.edge_data["transaction"][key].shape,}
if key in ["is_fraud"]:
feat[MetadataKeys.LABEL] = True
features.append(feat)
创建基础图后,是时候将事务特性添加到图的边上了。请注意,在这种情况下,事务数据只是边缘特定的,因此输出图没有节点特征。
创建图形并填充特征后,可以将模型应用于该图形。
培训 GNN 模型
考虑到数据集的标签不平衡和标签不完善,我们选择使用无监督任务链接预测来训练模型,以创建有意义的节点表示。链路预测的目的是预测两个节点之间存在边缘的概率。在金融服务业中,这被转化为预测个人和商户之间存在交易的可能性。
批处理中的一些目标节点是真实边,即存在于图形中的实际边,而其他由负采样器生成的节点是不真实存在的负边。在这种情况下,负面边缘是必要的,因为我们的训练任务是区分真假。生成负边的方法有多种,但简单地对节点进行均匀采样以获得节点端点被广泛采用,并取得了良好的效果。虽然使用这种方法可以对实际边进行负采样,但大多数图形都足够稀疏,因此这种可能性几乎可以忽略不计。
由于大多数事务图太大,无法在 GPU 内存中表示,因此我们需要使用子采样技术,以便生成较小的位置供图处理。 DGL 通常分两个阶段进行采样。
首先,执行种子采样,以识别 GNN 要预测的目标边缘或节点。接下来,执行块采样,也称为邻域采样,以生成种子周围的子图,用作 GNN 的输入。
该图包含可能从测试集中泄漏未来信息的边和节点,因此我们必须为训练、验证和测试集创建单独的数据加载器和采样例程。序列数据加载器相当简单,只利用训练集中的边进行种子采样,利用序列集图进行块采样。
对于验证数据加载器,使用验证边进行种子采样,但仅使用训练集图进行块采样,以防止信息泄漏。将同样的思想应用于测试集,其中测试边用于种子采样,而图则由块采样的训练集和验证集的联合定义。
为了加速数据加载,使用一个名为 Universal Virtual Addressing ( UVA )的功能,它允许我们实例化图形,以便所有 GPU 都可以直接访问它,而不是通过主机。当图形具有高度特色时, UVA 可以将模型吞吐量提高 5 倍。
定义数据加载器并构建图形后,实例化 R-GCN 模型。众所周知,图卷积网络对结构化邻域的特征进行编码,为连接到源节点的边分配相同的权重。 R-GCN 在此基础上构建,并提供依赖于边的类型和方向的特定于关系的转换。
边缘的类型信息补充了为每个节点计算的消息。节点的特征和边的类型作为输入传递给 R-GCN 模型,并转换为嵌入。 R-GCN 层可以通过消息传递和图卷积提取高级节点表示。
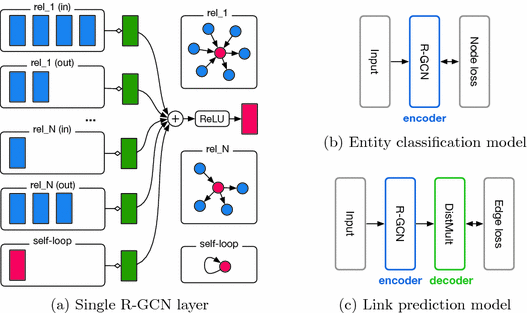
首先创建一个可学习的节点级嵌入,为每个节点存储 64 个元素的表示张量。鉴于无法使用(负边无特征),且图形没有节点特征,此处的节点嵌入将作为节点上的数字特征,而不仅仅是图形的纯结构。该嵌入表用作模型 R-GCN 的输入,该模型使用标准化超参数定义。
指定的模型输出宽度为 64 。请注意,该数字并不反映许多类:使用链接预测, R-GCN 模型应生成一个节点表示,下游操作可以使用该表示预测两个节点之间的边缘概率。有许多建议的方法可以做到这一点,包括多层感知器。本例使用两个节点的余弦相似性,以生成节点实际通过边连接的概率。因此,该模型被封装在链接预测模块中,以输出给定输入表示的概率。
接下来,定义优化器,每个优化器对应于模型本身和嵌入表。这两个优化器设置在涉及嵌入表的其他上下文中很常见,在这里用于提高模型收敛性。
定义了组件后,现在是训练模型的时候了。与其他域一样,可以使用分布式数据并行( DDP )在单个节点上对模型进行训练,以进一步加速多个 GPU 上的模型。
为下游任务使用 GNN 嵌入
R-GCN 模型经过训练后,使用网络生成健壮的节点嵌入。为此,对整个图形的每个图形层以一跳的比例执行图形卷积,并使用模型生成的后期激活作为图形节点的嵌入。
生成节点嵌入后,将嵌入连接到各自节点 ID 上的原始预处理数据集。接下来,将 XGBoost 模型拟合到边缘特征数据集,并使用从上游 GNN 模型提取的嵌入值进行增强。
首先,通过连接到 LocalCUDACluster 创建一个 Dask client ,这是一个基于 Dask 的 CUDA 集群,能够在多个 GPU 上执行 Python 进程。然后将边缘特征数据集读入 Dask 并进行采样,以使最终训练数据集(定义为通过嵌入值增强的边缘特征)的大小不超过总 GPU 存储的 40% 。这对于 Dask XGBoost 来说是必要的,因为完整的列车数据必须在 GPU 内存中,而创建 DMatrix 的过程会消耗剩余的内存。
接下来,读取上游模型的嵌入内容,并将节点特征附加到相应的 ID 中。最后,对 XGBoost 模型进行训练,以预测“是否欺诈?”并在测试集上输出 AUPRC 分数 0.9 。为了证明 GNN 创建的节点嵌入的有效性,在没有事务的情况下训练的最佳 XGBoost 模型在测试集中的 AUCPR 得分为 0.79 。
模型检查点可进一步用于在 NVIDIA Triton 推理服务器上部署此模型。
部署
XGBoost 模型经过训练后,部署该模型并启动一个推理服务器,使用 Python backend 处理嵌入查找,使用 Forest Inference Library ( FIL )后端执行 GPU 加速林库推理。
部署管道由三部分组成:
- Python 后端模型,称为嵌入模型。它读取嵌入张量。此后端接受卡 ID 和商家 ID 作为输入,并返回其嵌入内容。
- FIL 后端模型,称为 XGBoost 模型。它从培训中加载保存的 XGB 模型。此后端接受扩展数据(功能和嵌入),并返回每行的 XGB 预测。
- 另一个 Python 后端模型,我们称之为下游模型。该模型统一了整个部署。此后端接受卡 ID 、商家 ID 和功能。首先,它使用业务逻辑脚本( BLS )调用嵌入模型来获取嵌入。接下来,它连接特性和嵌入来创建扩展数据。然后,它再次使用 BLS 调用 XGB 模型,并返回其预测。
使用数据样本查询此服务,以获取交易欺诈的可能性。然后,可以将此概率用于开发后续业务逻辑。
基准
我们分别对一个欺诈检测和一个基准数据集 TabFormer 和 MAG240M 进行了广泛测试。为了使我们的实验具有可重复性,我们在所有基准测试运行中都使用了 DGX A100 ( 80 GB )。此服务器具有 64 核双插槽 AMD EPYC 7742 CPU 处理器和八个 NVIDIA A100 ( 80 GB SXM4 ) GPU 处理器。
下一节介绍了通过优化 GPU 的端到端工作流实现的加速。
TabFormer 数据集
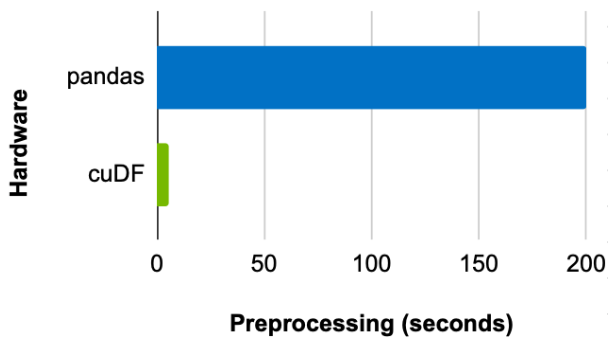
比较使用 CPU 上的 pandas 和 GPU 上的 cuDF 预处理数据集所需的时间,发现批次大小为 8192 时,使用 GPU 可以实现 39x 的加速(图 2 )。
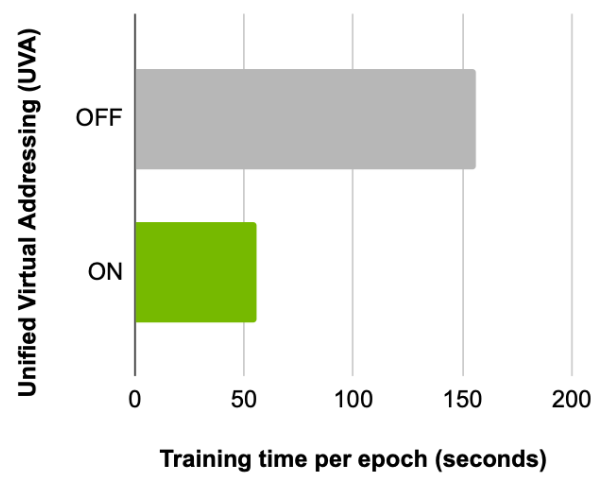
接下来,比较启用此功能前后每个历元的训练时间,显示使用 UVA 的优势。使用相同的批量大小和[5 , 5]配置的扇出,单个 GPU 可以实现 2.8x 的加速(图 3 )。
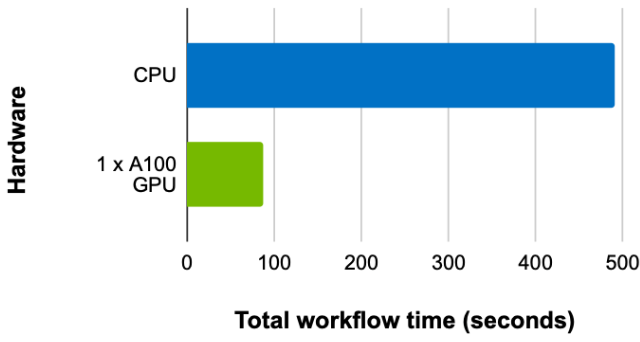
最后,比较具有相同批次大小和扇出配置的训练时间,但在 CPU 和 GPU (启用 UVA )上,单个 GPU 的加速比为 5.63 倍(图 4 )。
MAG240M 数据集
MAG240M 数据集是 OGB Large Scale Challenge 的一部分。它是节点级任务的最大公共基准数据集,具有约 2.45 亿个节点和约 17 亿条边。
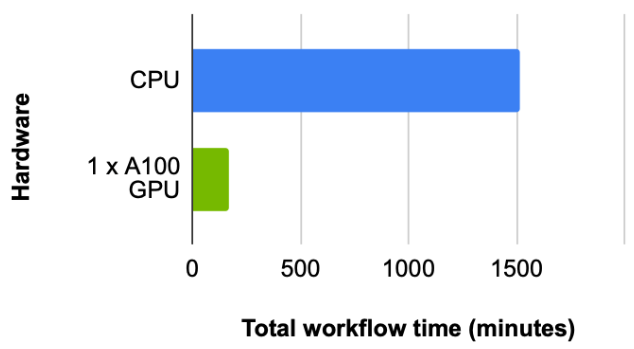
对于这个数据集,我们首先查看总工作流时间(预处理数据所需的时间)、加载、加上构造图形和训练 RGCN 模型。批次大小为 4096 ,扇出为[150100](用于在超参数搜索中获得最佳结果),我们观察到大约 9 倍的加速,其中 CPU 需要 1514 分钟, 1x NVIDIA A100 GPU 需要 169 分钟(图 5 )。
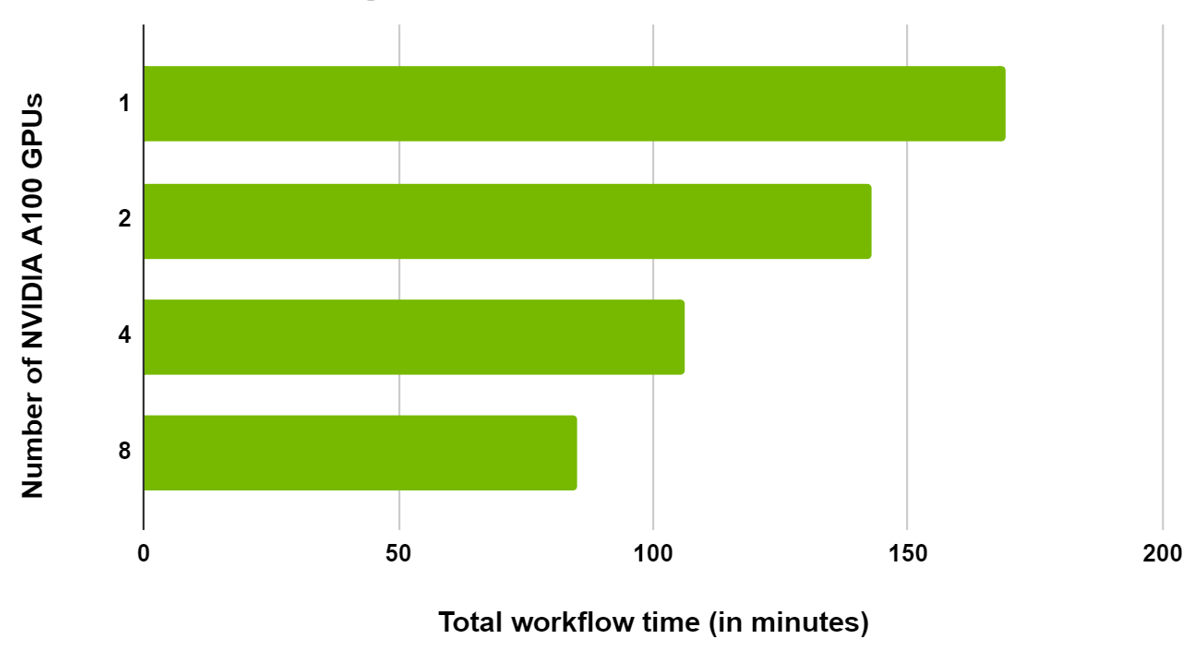
由于这是一个大型数据集,工作流已在同一节点中的多个 GPU 之间进行了扩展。我们观察到,当从 1 缩放到 2 GPU 时,总时间减少了 20% ,从 1 缩放至 8 GPU 时减少了 50% (图 6 )。
总结
NVIDIA 已与 DGL 和 PyG 合作,为 GPU 上的图形操作添加支持,并优化预处理和培训操作。了解更多有关 NVIDIA 如何积极促进这些顶级 GNN frameworks 的信息。
本文介绍了使用 GNN 进行欺诈检测的端到端工作流,包括预处理、将表格数据建模为图形、培训 GNN 、将 GNN 嵌入用于下游任务以及部署。这种方法利用了 NVIDIA 优化的 DGL ,以及一组依赖项,如 RAPIDS cuDF 和 NVIDIA Triton 推断服务器。我们在两个数据集上进一步演示了基准测试,其中我们观察到一个 NVIDIA A100 GPU 上的 MAG240M 数据集上的 RGCN 相对于 CPU 有 29x 的加速。
要了解更多信息,请与 AWS 高级应用科学家 Da Zheng 一起观看 GTC 会议 Accelerate and Scale GNNs with Deep Graph Library and GPUs 。另请参阅由 NVIDIA 工程师主持的 Accelerating GNNs with Deep Graph Library and GPUs 和 Accelerating GNNs with PyTorch Geometric and GPUs 。
如果您有 DGL early access 或 PyG early access ,现在可以尝试针对 NVIDIA GPU 进行性能优化和测试的容器。