
在游戏市场持续增长和对更好的 3D 图形的永不满足的需求的推动下, NVIDIA ®已经将 GPU 发展成为许多计算密集型应用的世界领先的并行处理引擎。除了渲染高度逼真和身临其境的 3D 游戏外, NVIDIA GPUs 还可以加速内容创建工作流、高性能计算( HPC )和数据中心应用程序,以及众多人工智能系统和应用程序。新的 NVIDIA 图灵 GPU 架构建立在 GPU 长期领导地位的基础上。
图灵代表了十多年来最大的体系结构飞跃,它提供了一个新的核心 GPU 体系结构,使 PC 游戏、专业图形应用和深度学习推理的效率和性能有了重大提高。
使用新的基于硬件的加速器和混合渲染方法,图灵融合了光栅化、实时光线跟踪、人工智能和模拟技术,在电脑游戏中实现令人难以置信的真实感、由神经网络驱动的惊人新效果、电影质量的交互体验以及创建或导航复杂 3D 模型时的流体交互。
在核心架构中,图灵显著提升图形性能的关键因素是一个新的 GPU 处理器(流式多处理器 SM )架构,它提高了着色器执行效率,以及一个新的内存系统架构,其中包括对最新 GDDR6 内存技术的支持。
图像处理应用程序,如 ImageNet Challenge 是深度学习的首批成功案例之一,因此,人工智能有潜力解决图形中的许多重要问题也就不足为奇了。图灵的张量核心支持一套新的基于深度学习的 神经服务 ,除了为基于云的系统提供快速的人工智能推断外,还为游戏和专业图形提供惊人的图形效果。
长期以来备受追捧的计算机图形绘制的圣杯——实时光线跟踪现在已经在具有 NVIDIA 图灵 GPU 体系结构的单 GPU 系统中实现。图灵 GPUs 引入了新的 RT 核心,加速器单元致力于以非凡的效率执行光线跟踪操作,消除了过去昂贵的基于软件仿真的光线跟踪方法。这些新装置与 NVIDIA RTX ™ 软件技术和复杂的过滤算法使图灵能够提供实时光线跟踪渲染,包括具有物理精确阴影、反射和折射的真实感对象和环境。
在图灵开发的同时,微软在 2018 年初发布了 directmlforai 和 DirectX 光线跟踪( DXR ) api 。通过图灵 GPU 架构和微软新的 AI 和光线追踪 API 的结合,游戏开发者可以在他们的游戏中快速部署实时 AI 和光线追踪。
除了具有开创性的人工智能和光线跟踪功能外,图灵还包括许多新的高级着色功能,这些功能可以提高性能,增强图像质量,并提供更高层次的几何复杂性。
图灵 GPUs 还继承了对 NVIDIA CUDA 的所有增强™ Volta 体系结构中引入的平台,可提高计算应用程序的能力、灵活性、生产力和可移植性。诸如独立线程调度、多应用程序地址空间隔离的硬件加速多进程服务( MPS )和协作组等特性都是图灵 GPU 体系结构的一部分。
一些新的 NVIDIA GeForce ®和 NVIDIA Quadro ™ GPU 产品将由图灵 GPUs 提供动力。在本文中,我们将重点介绍 NVIDIA 旗舰图灵 GPU 的体系结构和性能,该产品代号为 TU102 ,将在 GeForce RTX 2080 Ti 和 Quadro RTX 6000 上交付。技术细节,包括 TU104 和 TU106 图灵 GPUs 的产品规范,见附录。
图 1 展示了图灵如何用一个全新的架构来重塑图形,这个架构包括增强的张量核心、新的 RT 核心和许多新的高级着色功能。图灵结合了可编程着色、实时光线跟踪和人工智能算法,为游戏和专业应用程序提供了难以置信的真实感和物理精确的图形。

NVIDIA 图灵关键特性
NVIDIA 图灵是世界上最先进的 GPU 体系结构。高端 TU102 GPU 包括
在台积电 12 纳米 FFN ( FinFET NVIDIA )高性能制造工艺上制造了 186 亿个晶体管。
GeForce RTX 2080 Ti Founders Edition GPU 提供了以下卓越的计算性能:
 14 . 2 TFLOPS 公司1峰值单精度( FP32 )性能
14 . 2 TFLOPS 公司1峰值单精度( FP32 )性能
28 . 5 吨1半精度( FP16 )性能的峰值
14 . 2 提示1通过独立的整数执行单元与 FP 并行
113 . 8 张量 TFLOPS1,2
10 千兆射线/秒
78 太拉 RTX – 操作
Quadro RTX 6000 提供了专为专业工作流程设计的卓越计算性能:
16 . 3 TFLOPS 公司1峰值单精度( FP32 )性能
32 . 6 TFLOPS 公司1半精度( FP16 )性能的峰值
16 . 3 TIPS1 与 FP 并行,通过独立的整数执行单元
130 . 5 张量 TFLOPS1,2
10 千兆射线/秒
84 太拉 RTX – 操作
1基于 GPU 升压时钟。2FP16 矩阵数学与 FP16 累加。
下面的部分将以摘要格式描述图灵的主要新创新。本白皮书提供了每个领域的更详细描述。
新的流式多处理器( SM )
与图灵新一代处理器相比,新一代图灵处理器的效率提高了 50% 。这些改进是由两个关键的体系结构更改实现的。首先,图灵 SM 添加了一个新的独立整数数据路径,它可以与浮点数学数据路径同时执行指令。在前几代中,执行这些指令会阻止浮点指令的发出。其次, SM 内存路径被重新设计,将共享内存、纹理缓存和内存负载缓存统一到一个单元中。这意味着普通工作负载的一级缓存可用带宽增加 2 倍,容量增加 2 倍以上。
![]() 图灵张量核
图灵张量核
张量核心是专门为执行张量/矩阵运算而设计的专用执行单元,这些运算是深度学习中使用的核心计算功能。与 Volta 张量核类似,图灵张量核在深度学习神经网络训练和推理操作的核心为矩阵计算提供了巨大的速度。图灵 GPUs 包括了一个新版本的张量核心设计,它已经增强了推断能力。图灵张量核心增加了新的 INT8 和 INT4 精度模式来推断可以容忍量化且不需要 FP16 精度的工作负载。图灵张量核心首次为 GeForce 游戏 PC 和基于 Quadro 的工作站带来了新的基于深度学习的人工智能能力。一种称为深度学习超级采样( DLSS )的新技术由张量核提供动力。 DLSS 利用深度神经网络提取渲染场景的多维特征,并智能地结合多帧图像中的细节来构造高质量的最终图像。与传统技术(如 TAA )相比, DLSS 使用更少的输入样本,同时避免了此类技术在透明度和其他复杂场景元素方面面临的算法困难。
实时光线跟踪加速
图灵引入了实时光线跟踪,使单个 GPU 能够渲染具有视觉真实感的 3D 游戏和复杂的专业模型,具有物理上精确的阴影、反射和折射。图灵的新 RT 核心加速射线追踪,并被系统和接口所利用,如 NVIDIA 的 RTX 射线追踪技术,以及微软 DXR , NVIDIA OptiX 等 API ™,以及 Vulkan 光线跟踪,提供实时光线跟踪体验。
新的着色技术
网格着色
网格着色改进了 NVIDIA 的几何处理架构,为图形管道的顶点、细分和几何体着色阶段提供了一个新的着色器模型,支持更灵活和高效的几何体计算方法。这种更灵活的模型,例如,通过将对象列表处理的关键性能瓶颈从 CPU 移开,并转移到高度并行的 GPU 网格着色程序中,使每个场景支持数量级更多的对象成为可能。网格着色还支持先进的几何合成和对象 LOD 管理的新算法。
可变速率着色( VRS )
VRS 允许开发人员动态控制着色速率,每 16 像素着色一次,或者每像素 8 次着色。应用程序使用着色速率曲面和每基本体(三角形)值的组合指定着色速率。 VRS 是一个非常强大的工具,它允许开发者更有效地进行阴影处理,减少了在全分辨率阴影处理不会给任何可见图像质量带来好处的屏幕区域的工作,从而提高了帧率。已经确定了几种基于 VRS 的算法,这些算法可以根据内容细节级别(内容自适应着色)、内容运动速率(运动自适应着色)以及 VR 应用、镜头分辨率和眼睛位置( Foveated Rendering )来改变着色工作。
纹理空间着色
使用纹理空间着色,对象在保存到内存的专用坐标空间(纹理空间)中着色,像素着色器从该空间采样,而不是直接计算结果。通过在内存中缓存着色结果并重用/重新采样的能力,开发人员可以消除重复的着色工作或使用不同的采样方法来提高质量。
多视图渲染( MVR )
MVR 有力地扩展了 Pascal 的单声道立体声( SP )。虽然 SPS 允许渲染除 X 偏移外的两个常见视图,但 MVR 允许在一个过程中渲染多个视图,即使这些视图基于完全不同的原点位置或视图方向。访问是通过一个简单的编程模型来实现的,在这个模型中,编译器自动将视图无关的代码分解出来,同时确定视图相关的属性以实现最佳执行。
图形的深度学习功能
NVIDIA NGX 公司™ 是 NVIDIA RTX 技术的新的基于深度学习的神经图形框架。 NVIDIA NGX 利用深度神经网络( DNNs )和一组“神经服务”来执行基于人工智能的功能,这些功能可以加速和增强图形、渲染和其他客户端应用程序。 NGX 将图灵张量核心用于基于深度学习的操作,并加速向最终用户直接交付 NVIDIA 深度学习研究。功能包括超高质量的 NGX DLSS (深度学习超级采样)、 AI 修复内容感知图像替换、 AI Slow-Mo 非常高质量和平滑的慢动作,以及 AI-Super-Rez 智能分辨率调整。
推理的深度学习特性
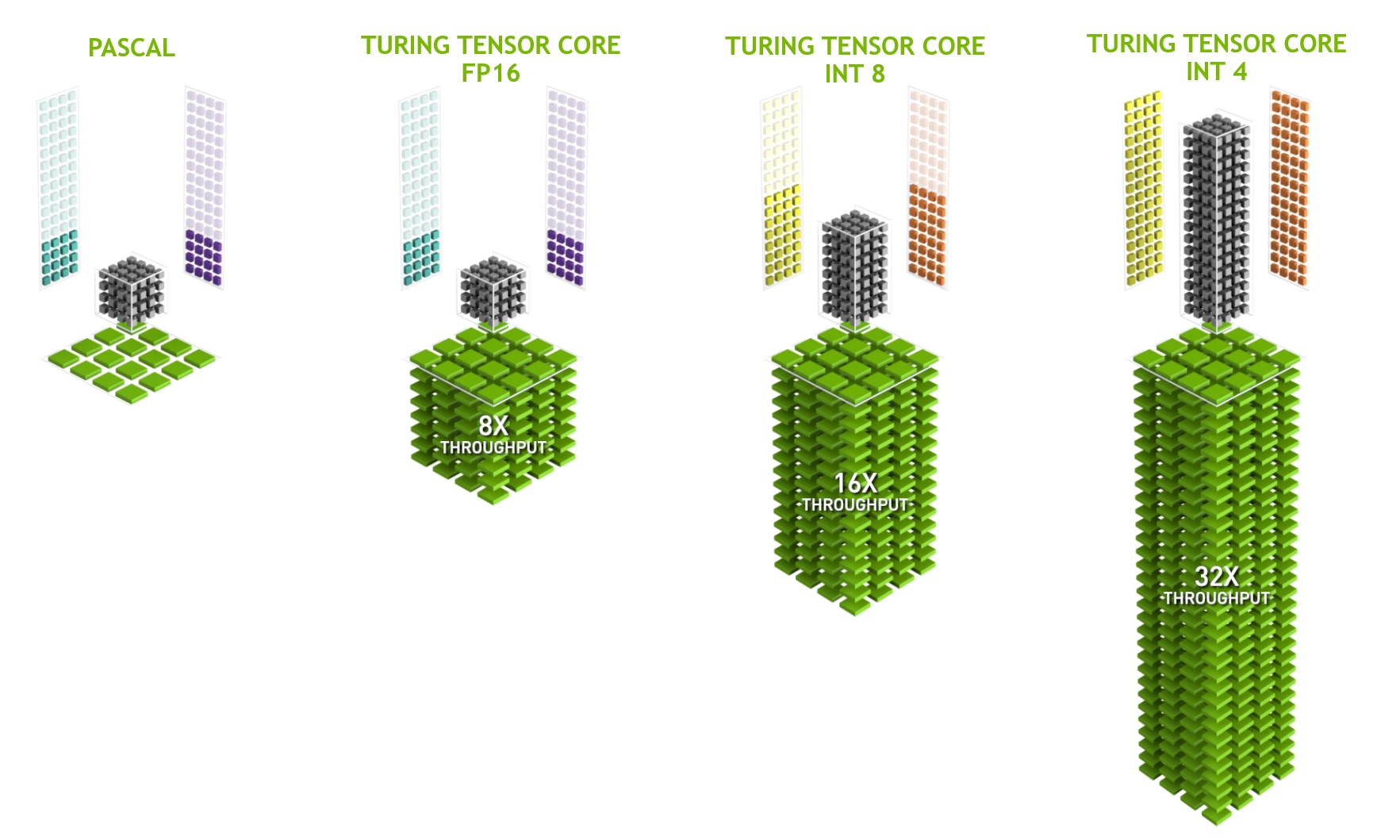
图灵 GPUs 提供了卓越的推理性能。图灵张量核心,加上 TensorRT ( NVIDIA 的运行时推断框架)、 CUDA 和 cuDNN 库的不断改进,使图灵 GPUs 能够为推理应用程序提供出色的性能。图灵张量核还增加了对快速 INT8 矩阵运算的支持,以最大程度地提高推理吞吐量,同时减少精确度损失。新的低精度 INT4 矩阵运算现在有可能与图灵张量核心,并将使研究和开发到亚 8 位神经网络。
GDDR6 高性能内存子系统
图灵是第一个支持 GDDR6 内存的 GPU 体系结构。 GDDR6 是高带宽 GDDRAM 内存设计的下一个重大进步。图灵 GPUs 中的 GDDR6 内存接口电路在速度、功率效率和噪音降低方面进行了彻底的重新设计,与 Pascal GPUs 中使用的 GDDR5X 内存相比,实现了 14 Gbps 的传输速率,功率效率提高了 20% 。
第二代 NVIDIA NVLink
图灵 TU102 和 TU104 GPUs 合并了 NVIDIA 的 NVLink ™ 高速互连,提供可靠、高带宽和低延迟连接对图灵 GPUs 。 NVLink 具有高达 100GB / s 的双向带宽,使定制的工作负载能够在两个 GPUs 之间高效地分割并共享内存容量。对于游戏工作负载, NVLink 增加的带宽和专用的 inter- GPU 通道为 SLI 提供了新的可能性,例如新的模式或更高分辨率的显示配置。对于大型内存工作负载,包括专业的光线跟踪应用程序,场景数据可以在 GPUs 的帧缓冲区中分割,提供高达 96 GB 的共享帧缓冲区内存(两个 48 GB Quadro RTX 8000 GPUs ),内存请求由硬件根据内存分配的位置自动路由到正确的 GPU 。
USB-C 和 VirtualLink
图灵 GPUs 包括对 USB Type-C 的硬件支持™ 和 VirtualLink ™. (为了准备新出现的 VirtualLink 标准,图灵 GPUs 已经根据 VirtualLink 高级概述 实现了硬件支持。要了解有关 VirtualLink 的更多信息,请参阅 http://www.virtuallink.org )VirtualLink 是一种新的开放式行业标准,旨在通过单个 USB-C 连接器满足下一代 VR 耳机的功率、显示和带宽需求。除了减轻目前 VR 耳机的安装麻烦之外, VirtualLink 还将把 VR 应用到更多的设备中。
![]() 深度图灵体系结构
深度图灵体系结构
图灵 TU102 GPU 是图灵 GPU 线路中性能最高的 GPU ,也是本节的重点。 TU104 和 TU106 GPUs 采用与 TU102 相同的基本架构,针对不同的使用模式和市场细分,进行了不同程度的缩减。 TU104 和 TU106 芯片架构和目标用途/市场的详细信息见 图灵体系结构白皮书 。
图灵 TU102 GPU
TU102 GPU 包括 6 个图形处理群集( GPC )、 36 个纹理处理群集( TPC )和 72 个流式多处理器( SMs )。(参见 图 2 了解带有 72 个 SM 单元的 TU102 full GPU 的图示。)每个 GPC 包括一个专用光栅引擎和六个 TPC ,每个 TPC 包括两个 SMs 。每个 SM 包含 64 个 CUDA 内核、 8 个张量内核、一个 256 KB 的寄存器文件、 4 个纹理单元和 96 KB 的 L1 /共享内存,这些内存可根据计算或图形工作负载配置为各种容量。
光线跟踪加速由每个 SM 内的新 RT 核心处理引擎执行( RT 核心和光线跟踪功能在完整的 NVIDIA 图灵体系结构白皮书 中有更深入的讨论)。
TU102 GPU 的全面实施包括以下内容:
4608 CUDA 颜色
72 个 RT 芯
576 张量核
288 个纹理单位
12 个 32 位 GDDR6 内存控制器(总计 384 位)。
每个内存控制器都有 8 个 ROP 单元和 512 KB 的二级缓存。完整的 TU102 表 1 由 96 个 ROP 单元和 6144 KB 的二级缓存组成。参见 GPU 表 1 中的图灵 TU102 GPU 比较了 Pascal GP102 的 GPU 特性和图灵 TU102 。
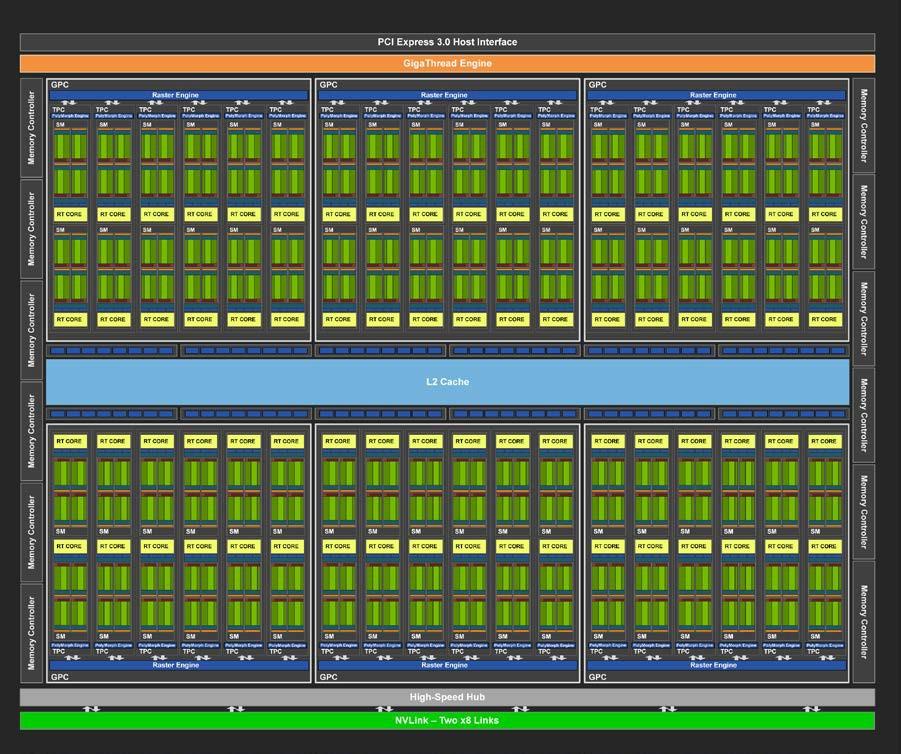
注: TU102 GPU 还具有 144 个 FP64 单元(每平方米两个),这在本图中没有描述。 FP64 TFLOP 速率是 FP32 操作的 TFLOP 速率的 1 / 32 。包含少量的 FP64 硬件单元,以确保任何使用 FP64 代码的程序都能正确运行。
| GPU Features | GTX 1080Ti | RTX 2080 Ti | Quadro 6000 | Quadro RTX 6000 |
| Architecture | Pascal | Turing | Pascal | Turing |
| GPCs | 6 | 6 | 6 | 6 |
| TPCs | 28 | 34 | 30 | 36 |
| SMs | 28 | 68 | 30 | 72 |
| CUDA Cores / SM | 128 | 64 | 128 | 64 |
| CUDA Cores / GPU | 3584 | 4352 | 3840 | 4608 |
| Tensor Cores / SM | NA | 8 | NA | 8 |
| Tensor Cores / GPU | NA | 544 | NA | 576 |
| RT Cores | NA | 68 | NA | 72 |
| GPU Base Clock MHz (Reference / Founders Edition) | 1480 / 1480 | 1350 / 1350 | 1506 | 1455 |
| GPU Boost Clock MHz (Reference / Founders Edition) | 1582 / 1582 | 1545 / 1635 | 1645 | 1770 |
| RTX-OPS (Tera-OPS)
(Reference / Founders Edition) |
11.3 / 11.3 | 76 / 78 | NA | 84 |
| Rays Cast (Giga Rays/sec) (Reference / Founders Edition) | 1.1 / 1.1 | 10 / 10 | NA | 10 |
| Peak FP32 TFLOPS✱
(Reference/Founders Edition) |
11.3 / 11.3 | 13.4 / 14.2 | 12.6 | 16.3 |
| Peak INT32 TIPS✱
(Reference/Founders Edition) |
NA | 13.4 / 14.2 | NA | 16.3 |
| Peak FP16 TFLOPS✱
(Reference/Founders Edition) |
NA | 26.9 / 28.5 | NA | 32.6 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate✱ (Reference/Founders Edition) | NA | 107.6 / 113.8 | NA | 130.5 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate✱ (Reference/Founders Edition) | NA | 53.8 / 56.9 | NA | 130.5 |
| Peak INT8 Tensor TOPS✱ (Reference/Founders Edition) | NA | 215.2 / 227.7 | NA | 261.0 |
| Peak INT4 Tensor TOPS✱
(Reference/Founders Edition) |
NA | 430.3 / 455.4 | NA | 522.0 |
| Frame Buffer Memory Size and Type | 11264 MB GDDR5X | 11264 MB GDDR6 | 24576 MB GDDR5X | 24576 MB GDDR6 |
| Memory Interface | 352-bit | 352-bit | 384-bit | 384-bit |
| Memory Clock (Data Rate) | 11 Gbps | 14 Gbps | 9 Gbps | 14 Gbps |
| Memory Bandwidth (GB/sec) | 484 | 616 | 432 | 672 |
| ROPs | 88 | 88 | 96 | 96 |
| Texture Units | 224 | 272 | 240 | 288 |
| Texel Fill-rate (Gigatexels/sec) | 354.4 / 354.4 | 420.2 / 444.7 | 395 | 510 |
| L2 Cache Size | 2816 KB | 5632 KB | 3072 KB | 6144 KB |
| Register File Size/SM | 256 KB | 256 KB | 256 KB | 256 KB |
| Register File Size/GPU | 7168 KB | 17408 KB | 7680 KB | 18432 KB |
| TDP★
(Reference/Founders Edition) |
250 / 250 W | 250 / 260 W | 250 W | 260 W |
| Transistor Count | 12 Billion | 18.6 Billion | 12 Billion | 18.6 Billion |
| Die Size | 471 | 754 | 471 | 754 |
| Manufacturing Process | 16 nm | 12 nm FFN | 16 nm | 12 nm FFN |
随着 GPU 加速计算变得越来越流行,具有多个 GPUs 的系统正越来越多地部署在服务器、工作站和超级计算机上。 TU102 和 TU104 GPUs 包括第二代 NVIDIA 的 NVLink ™ 高速互连,最初设计为 Volta GV100 GPU ,为 SLI 和其他多 GPU 用例提供高速多 GPU 连接。 NVLink 允许每个 GPU 直接访问其他连接的 GPUs 的内存,提供更快的 GPU – GPU 通信,并允许组合来自多个 GPUs 的内存以支持更大的数据集和更快的内存计算。
TU102 包括两个 NVLink x8 链路,每个链路在每个方向上的传输速率高达 25gb / s ,双向总带宽为 100gb / s 。

图灵流式多处理器( SM )体系结构
图灵架构的特点是一个新的 SM 设计,它包含了我们在 Volta GV100 SM 架构中引入的许多功能。每个 TPC 包括两个 SMs ,每个 SM 共有 64 个 FP32 核和 64 个 INT32 核。相比之下, Pascal GP10x GPUs 每个 TPC 有一个 SM ,每 SM 有 128 个 FP32 核。图灵 SM 支持 FP32 和 INT32 操作的并发执行(更多细节见下文),独立的线程调度类似于 voltagv100 GPU 。每个图灵 SM 还包括八个混合精度的图灵张量核心,在 下面的 图灵张量核 一节中有更详细的描述,还有一个 RT 核心,其功能在 图灵射线追踪技术 below . 中有描述,图灵 TU102 、 TU104 和 TU106 SM 的说明见 图 4 。
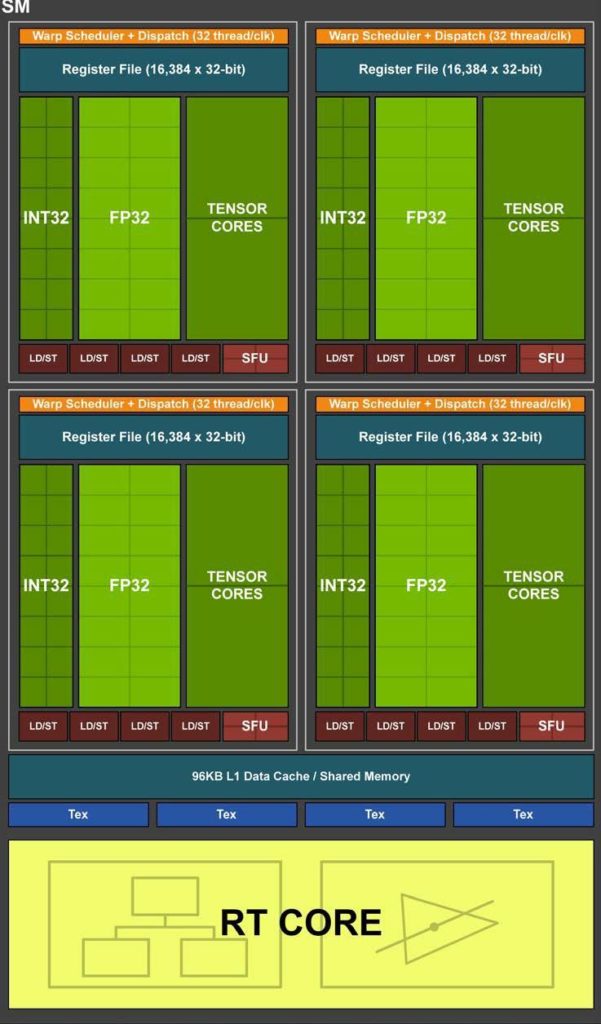
图灵 SM 被划分为四个处理块,每个处理块有 16 个 FP32 核、 16 个 INT32 核、两个张量核、一个 warp 调度器和一个调度单元。每个块包括一个新的 L0 指令缓存和一个 64kb 的寄存器文件。四个处理块共享一个组合的 96kbl1 数据缓存/共享内存。传统图形工作负载将 96 KB L1 /共享内存划分为 64 KB 的专用图形着色器 RAM 和 32 KB 的纹理缓存和寄存器文件溢出区域。计算工作负载可以将 96 KB 划分为 32 KB 共享内存和 64 KB L1 缓存,或 64 KB 共享内存和 32 KB L1 缓存。
图灵实现了核心执行数据路径的重大改进。现代着色器工作负载通常将 FP 算术指令(如 FADD 或 FMAD )与更简单的指令(如用于寻址和获取数据的整数加法、用于处理结果的浮点比较或最小/最大值)混合在一起。在以前的着色器体系结构中,每当这些非 FP 数学指令之一运行时,浮点数学数据路径就处于空闲状态。在第二个并行执行单元 kzc0 上,用一个并行的 CUDA 执行一个浮点指令。
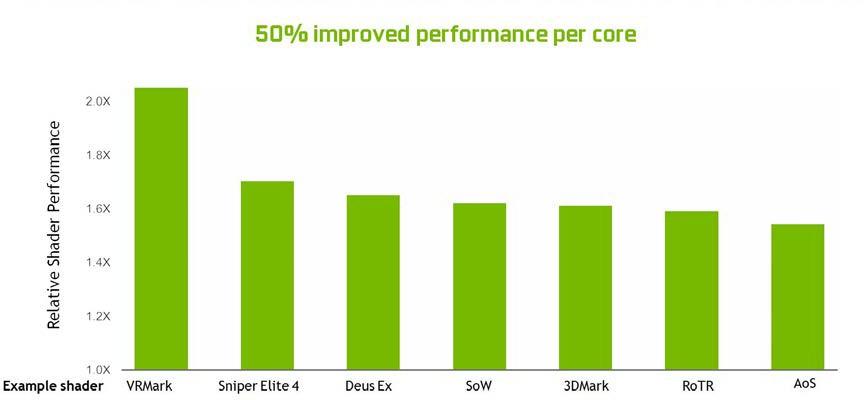
图 5 表明整数管道指令与浮点指令的混合情况各不相同,但在一些现代应用程序中,我们通常会看到每 100 条浮点指令增加 36 条整数管道指令。将这些指令移动到一个单独的管道中,这意味着浮点的有效吞吐量增加了 36% 。
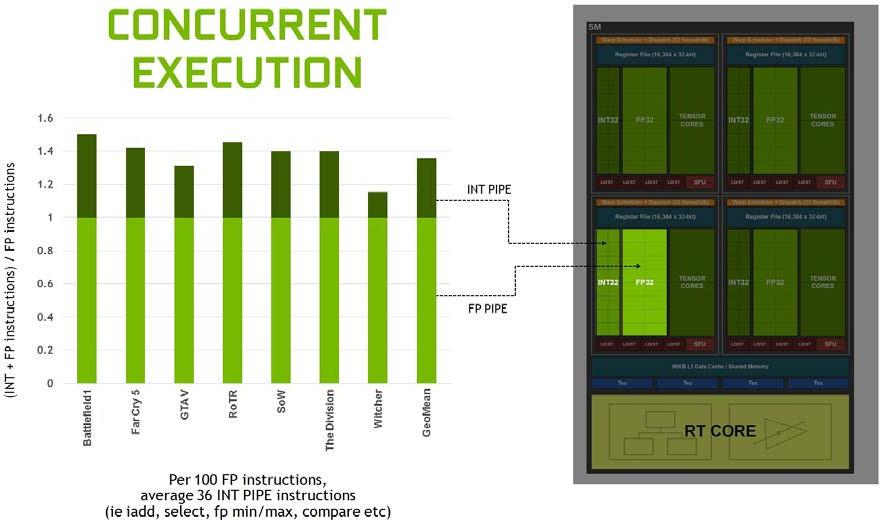
分析许多工作负载时,平均每 100 个浮点操作就有 36 个整数操作。
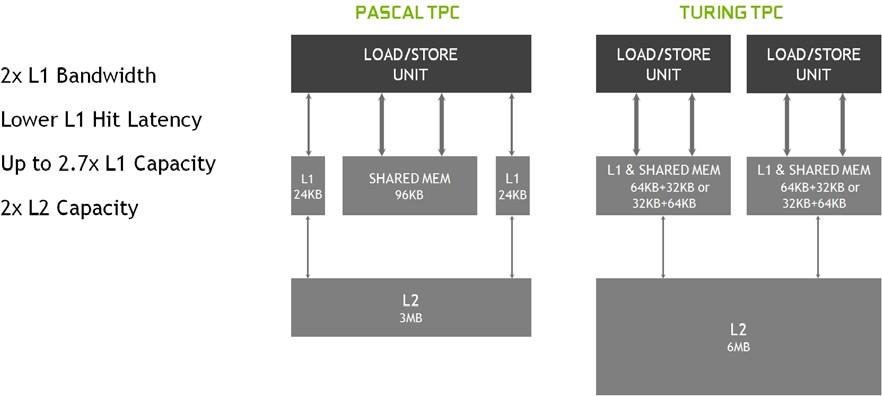
图灵还为 L1 的共享内存引入了统一的纹理缓存和架构。这种统一的设计允许一级缓存利用资源,与 Pascal 相比,每 TPC 增加 2 倍的命中带宽,并允许在共享内存分配未使用所有共享内存容量时对其进行重新配置,使其更大。图灵 L1 的大小可以达到 64kb ,再加上每个 SM 共享内存分配 32kb ,或者它可以减少到 32kb ,允许 64kb 的分配用于共享内存。图灵的二级缓存容量也有所增加。
图 6 展示了图灵 SM 新的组合 L1 数据缓存和共享内存子系统如何显著提高性能,同时简化编程并减少达到或接近峰值应用程序性能所需的调整。将一级数据缓存与共享内存相结合可以减少延迟,并提供比先前在 Pascal GPUs 中使用的一级缓存实现更高的带宽。
总的来说, SM 的变化使图灵能够在每个 CUDA 核心上实现 50% 的性能改进。 图 7 显示当前游戏应用程序的一组着色器工作负载的结果。
图灵张量核
图灵 GPUs 包括一个增强版的张量核心首次引入 voltagv100 GPU 。图灵张量核心设计增加了 INT8 和 INT4 精确模式,用于推断可以容忍量化的工作负载。对于需要更高精度的工作负载, FP16 也完全受支持。
在基于图灵的 GeForce 游戏 GPUs 中引入张量核,使得首次将实时深度学习引入游戏应用成为可能。图灵张量核心加速了 NVIDIA NGX 神经服务基于人工智能的特性,增强了图形、渲染和其他类型的客户端应用。 NGX 人工智能功能的例子包括深度学习超级采样( DLSS )、 AI 修复、 AI 超级 Rez 和 AI Slow-Mo 。关于 DLSS 的更多细节可以在本文后面找到。您可以在完整的 NVIDIA 图灵体系结构白皮书 中找到有关其他 NGX 功能的附加信息。
图灵张量核加速矩阵乘法是神经网络训练和推理功能的核心。图灵张量核特别擅长推理计算,在推理计算中,有用的和相关的信息可以由一个训练好的深层神经网络( DNN )基于给定的输入进行推断和传递。推理的例子包括识别 Facebook 照片中朋友的图像,识别和分类不同类型的汽车、行人和自动驾驶汽车中的道路危险,实时翻译人类语言,以及在在线零售和社交媒体系统中创建个性化的用户推荐。
TU102 GPU 包含 576 个张量核心:每个 SM 8 个, SM 内每个处理块 2 个。每个张量核心可以执行多达 64 个浮点融合乘法加法( FMA )操作,每个时钟使用 FP16 输入。一个 SM 中的八个张量核心每时钟执行 512 个 FP16 乘法和累加运算,或每个时钟总共执行 1024 次浮点运算。新的 INT8 精度模式以两倍的速率工作,即每时钟 2048 次整数运算。
图灵张量核为矩阵运算提供了显著的加速,除了新的神经图形功能外,还用于深度学习训练和推理操作。有关基本张量核心操作细节的更多信息,请参阅 NVIDIA Tesla V100 GPU 体系结构白皮书 .
为数据中心应用程序优化的图灵
除了为高端游戏和专业图形带来革命性的新功能外,图灵还为下一代 Tesla ® GPUs 提供卓越的性能和能效。 NVIDIA 目前在数据中心用于推断应用程序的基于 Pascal 的 GPUs 已经比基于 CPU 的服务器提供了高达 10 倍的性能和 25 倍的能效。在图灵张量核心的支持下,下一代基于图灵的 Tesla GPUs 将在数据中心提供更高的推断性能和能源效率。基于图灵的 Tesla GPUs 优化后可在 70 瓦以下运行,这将为超大规模数据中心带来显著的效率和性能提升。
除了图灵张量核心之外,图灵 GPU 体系结构还包括一些提高数据中心应用程序性能的特性。一些关键功能包括:
增强视频引擎
与上一代 Pascal 和 Volta GPU 架构相比,图灵支持额外的视频解码格式,如 HEVC 4 : 4 : 4 ( 8 / 10 / 12 位)和 VP9 ( 10 / 12 位)。图灵中增强的视频引擎能够解码比等效的基于 Pascal 的 Tesla GPUs 多得多的并发视频流。(见 视频显示引擎 下面的 . 一节)
图灵多进程服务
图灵 GPU 体系结构继承了 Volta 体系结构中首次引入的增强型多进程服务( MPS )特性。与基于 Pascal 的 Tesla GPUs 相比,基于图灵的 Tesla 板上的 MPS 提高了小批量的推理性能,减少了启动延迟,提高了服务质量,可以处理更多的并发客户端请求。
更高的内存带宽和更大的内存大小
即将推出的基于图灵的 Tesla 板具有更大的内存容量和更高的内存带宽,而上一代基于 Pascal 的 Tesla 板针对相似的服务器段,为虚拟桌面基础设施( VDI )应用提供了更高的用户密度。
图灵存储器结构和显示特性
本节将深入探讨图灵体系结构的关键新内存层次结构和显示子系统特性。
内存子系统的性能对于应用程序加速至关重要。图灵改进了主内存、缓存和压缩架构,以增加内存带宽并减少访问延迟。改进和增强的 GPU 计算功能有助于加速游戏和许多计算密集型应用程序和算法。新的显示和视频编码/解码功能支持更高分辨率和 HDR 功能的显示器、更先进的 VR 显示器、数据中心不断增加的视频流需求、 8K 视频制作和其他视频相关应用。详细讨论了以下特点:
GDDR6 内存子系统
随着显示分辨率不断提高,着色器功能和渲染技术变得更加复杂,内存带宽和大小在 GPU 性能中扮演着更大的角色。为了保持最高的帧速率和计算速度, GPU 不仅需要更多的内存带宽,还需要一个大的内存池来提供持续的性能。
NVIDIA 与 DRAM 行业密切合作,开发了世界上第一款使用 HBM2 和 GDDR5X 内存的 GPUs 。现在图灵是第一个使用 GDDR6 内存的 GPU 架构。
GDDR6 是高带宽 GDDRAM 内存设计的下一个重大进步。随着许多高速 SerDes 和 RF 技术的增强,图灵 GPUs 中的 GDDR6 内存接口电路已经完全重新设计,以实现速度、功率效率和降噪。这种新的接口设计带来了许多新的电路和信号训练改进,最大限度地减少了噪声和工艺、温度和电源电压的变化。广泛的时钟门控被用来最小化低利用率期间的功耗,从而显著提高整体功率效率。与 Pascal GPUs 中使用的 GDDR5X 内存相比, Turing 的 GDDR6 内存子系统提供了 14 Gbps 的信令速率和 20% 的能效改进。
实现这种速度提升需要端到端的优化。利用广泛的信号和电源完整性仿真, NVIDIA 精心设计了图灵的封装和电路板设计,以满足更高的速度要求。例如,信号串扰降低 40% ,这是大型存储系统中最严重的损伤之一。
为了实现 14 Gbps 的速度,内存子系统的各个方面都经过精心设计,以满足如此高频率操作所需的高要求标准。设计中的每个信号都经过了仔细的优化,以提供尽可能干净的内存接口信号(参见 图 9 )。

二级缓存和 ROPs
图灵 GPU 除了新的 GDDR6 内存子系统之外,还增加了更大更快的二级缓存。 TU102 GPU 附带 6mb 的二级缓存,是上一代 GP102 GPU 在 Xp 中使用的 3mb 二级缓存的两倍。 TU102 还提供比 GP102 更高的二级缓存带宽。
和上一代 NVIDIA GPU 一样,图灵图灵中的每个 ROP 分区包含 8 个 ROP 单元,每个单元可以处理一个单一的颜色样本。一个完整的 TU102 芯片包含 12 个 ROP 分区,总共 96 个 ROP 。
图灵存储器压缩
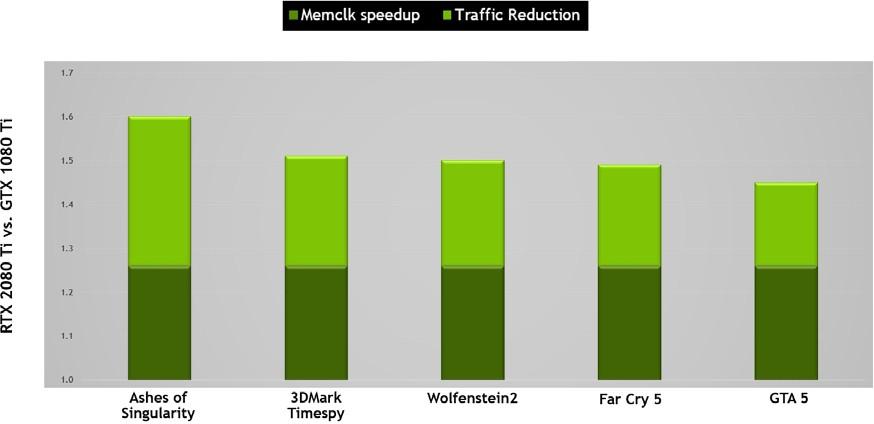
NVIDIA GPUs 利用几种无损内存压缩技术,在数据被写入帧缓冲存储器时减少对内存带宽的需求。 GPU 的压缩引擎有各种不同的算法,这些算法根据数据的特性来确定最有效的压缩方法。这减少了写入内存和从内存传输到二级缓存的数据量,并减少了客户端(如纹理单元)和帧缓冲区之间传输的数据量。图灵对 Pascal 最先进的内存压缩算法进行了进一步的改进,在 GDDR6 的原始数据传输速率提高之外,提供了更大的有效带宽。如 图 10 , 所示,原始带宽的增加和通信量的减少意味着图灵上的有效带宽比 Pascal 增加了 50% ,这对于保持架构平衡和支持新图灵 SM 架构提供的性能至关重要。
基于图灵 TU102 的存储子系统和压缩(流量减少)改进
RTX 2080 Ti 比基于 Pascal GP102 的 1080 Ti 提供大约 50% 的有效带宽改进。
视频显示引擎
消费者对高分辨率显示器的需求逐年增加。例如, 8K 分辨率( 7680 x 4320 )需要的像素是 4K ( 3820 x 2160 )的四倍。游戏玩家和硬件发烧友也希望显示器除了更高的分辨率外,还有更高的刷新率,以体验尽可能平滑的图像。
图灵 GPUs 包括一个全新的显示引擎,为新一轮的显示设计,支持更高的分辨率,更快的刷新率,以及 HDR 。图灵支持 DisplayPort1 . 4a ,在 60Hz 下支持 8K 分辨率,并包括 VESA 的显示流压缩( DSC ) 1 . 2 技术,提供更高的压缩,视觉无损。 表 2 显示了图灵 GPUs 中对 DisplayPort 的支持。
| Bandwidth/Lane | Max Resolution Supported | |
| DisplayPort 1.2 | 5.4 Gbps | 4K @ 60 Hx |
| DisplayPort 1.3 | 8.1 Gbps | 5K @ 60 Hx |
| DisplayPort 1.4a | 8.1 Gbps | 8K @ 60 Hx |
图灵 GPUs 可以驱动两个 60hz 的 8K 显示器,每个显示器有一根电缆。 8K 分辨率也可以通过 USB-C 发送(有关更多详细信息,请参见 下面的 USB-C 和 VirtualLink 部分)。
图灵的新显示引擎支持显示管道中的 HDR 本地处理。色调映射也被添加到了 HDR 管道中。色调映射是一种用于在标准动态范围显示器上近似显示高动态范围图像的技术。图灵支持 ITU-R 建议 BT . 2100 标准定义的色调映射公式,以避免不同 HDR 显示器上的颜色偏移。
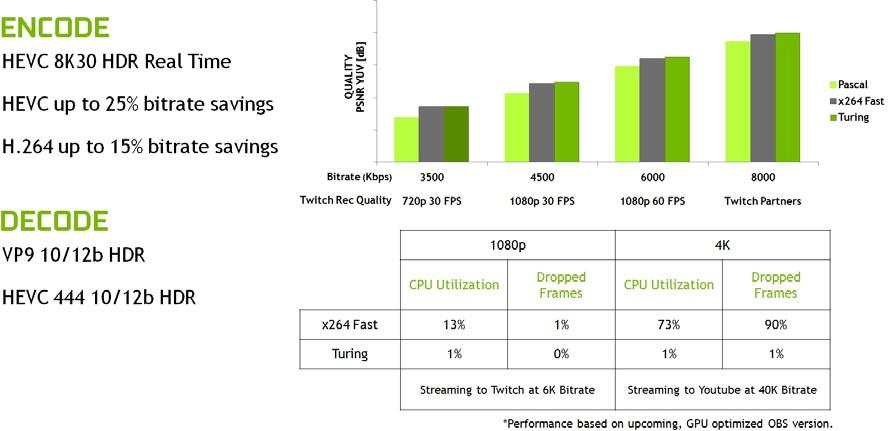
图灵 GPUs 还附带了一个增强的 NVENC 编码器单元,它增加了对 H . 265 ( HEVC ) 8K 编码的支持,每秒 30 帧。新的 NVENC 编码器为 HEVC 提供了高达 25% 的比特率节省,为 H . 264 提供了高达 15% 的比特率节省。
图灵的新 NVDEC 解码器也已更新,以支持在 30 帧/秒、 H . 264 8K 和 VP9 10 / 12b HDR 解码 HEVC YUV444 10 / 12b HDR 。
与上一代 Pascal GPU 和软件编码器相比,图灵改进了编码质量。 图 11 显示,在常见的 Twitch 和 YouTube 流媒体设置中, Turing 的视频编码器超过了使用 快速的 编码设置的基于 x264 软件的编码器的质量,同时 CPU 利用率显著降低。在典型的 CPU 设置上, 4K 流对于编码来说是一个太重的工作负载,但是图灵的编码器使 4K 流成为可能。
USB-C 和 VIRTUALLINK
在今天的 PC 机上支持 VR 耳机需要在耳机和系统之间连接多条电缆;一条显示电缆将图像数据从 GPU 发送到耳机中的两个显示器,一条电缆用于为耳机供电,以及一个 USB 连接,用于传输摄像机流并从耳机读取后头姿势信息(以更新由 GPU 渲染的帧)。电缆的数量可能会让最终用户感到不舒服,并限制了他们在使用耳机时四处走动的能力。耳机制造商需要适应电缆,使其设计复杂化,并使其体积更大。
为了解决这个问题, Turing GPUs 设计了支持 USB Type-C 的硬件™ 和 VirtualLink ™. VirtualLink 是一种新的开放式行业标准,包括领先的硅、软件和耳机制造商,由 NVIDIA 、 Oculus 、 Valve 、 Microsoft 和 AMD 领衔。
VirtualLink 是为了满足当前和下一代 VR 耳机的连接需求而开发的。 VirtualLink 采用了一种新的 USB-C 替代模式,旨在通过一个 USB-C 接口提供为 VR 耳机供电所需的电源、显示器和数据。
VirtualLink 同时支持四个通道的高比特率 3 ( HBR3 )显示端口,以及连接到耳机的超高速 USB 3 链路,用于运动跟踪。相比之下, USB-C 只支持四个通道的 HBR3 显示端口 或者 两个通道的 HBR3 显示端口+两个通道的超高速 USB 3 。
除了减轻目前 VR 耳机的安装麻烦之外, VirtualLink 还将把 VR 应用到更多的设备中。单连接器解决方案将虚拟现实技术带到可以容纳单个、小尺寸 USB-C 连接器(如轻薄笔记本)的小型设备上,而不是现在的虚拟现实基础设施,后者需要一台能够容纳多个连接器的 PC 机。
NVLINK 改善了 SLI
在 Pascal GPU 架构之前, NVIDIA GPUs 使用单个多输入/输出( MIO )接口作为 SLI 桥接技术,允许第二个(或第三个或第四个) GPU 将其最终渲染帧输出传输到物理连接到显示器的主 GPU 。帕斯卡通过使用更快的双 MIO 接口增强了 SLI 桥,提高了 GPUs 之间的带宽,允许更高分辨率的输出,以及 NVIDIA 环绕的多个高分辨率监视器。
图灵 TU102 和 TU104 GPUs 使用 NVLink 代替 MIO 和 PCIe 接口进行 SLI GPU – GPU 数据传输。图灵 TU102 GPU 包括两个 x8 第二代 NVLink 链路, Turing TU104 包括一个 x8 第二代 NVLink 链路。每条链路在两个 GPUs 之间的每个方向提供 25 GB / s 的峰值带宽( 50 GB / s 双向带宽)。双向链路为 100 GB /秒,或每秒钟提供两个 GB /秒的双向链路。具有 NVLink 的图灵 GPUs 支持双向 SLI ,但不支持 3 路和 4 路 SLI 配置。
与以前的 SLI 网桥相比,新的 NVLink 网桥的带宽增加了以前不可能实现的高级显示拓扑(参见 图 12 )。
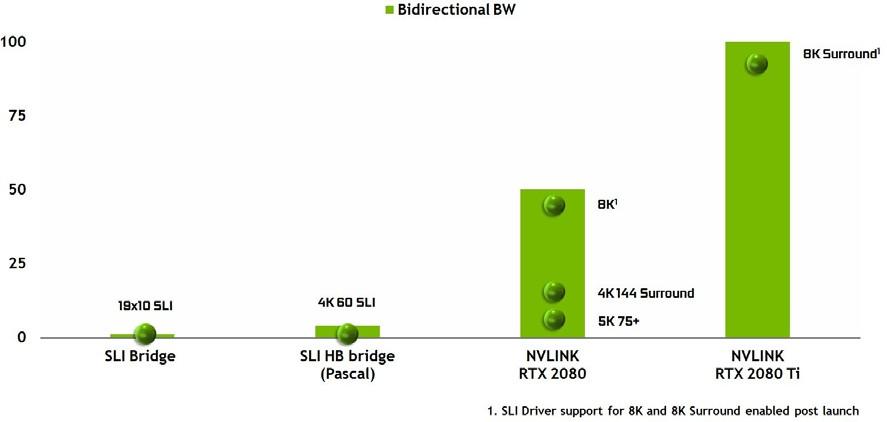
启动和 8POST 驱动支持将启用。
图灵射线追踪技术
光线跟踪是一种计算密集的渲染技术,可以真实地模拟场景及其对象的照明。基于图灵 GPU 的光线跟踪技术可以实时渲染物理上正确的反射、折射、阴影和间接照明。有关光线跟踪如何工作的详细信息可以在完整的 图灵白皮书 中找到。
在过去, GPU 体系结构无法使用单个 GPU 为游戏或图形应用程序执行实时光线跟踪。尽管 NVIDIA 的 GPU 加速 NVIDIA Iray ®插件和 OptiX 光线跟踪引擎多年来一直为设计师、艺术家和技术总监提供逼真的光线跟踪渲染,但高质量的光线跟踪效果无法实时执行。类似地,当前的 NVIDIA Volta GPUs 可以渲染逼真的电影级光线跟踪场景,但不能在单个 GPU 上实时渲染。由于其处理密集的性质,光线跟踪在游戏中尚未用于任何重要的渲染任务。相反,需要 30 到 90 帧/秒动画的游戏多年来一直依赖快速 GPU 加速光栅化渲染技术,而牺牲了完全逼真的场景。
在 GPUs 上实现实时光线跟踪是一个巨大的技术挑战,需要 NVIDIA 的研究、 GPU 的硬件设计和软件工程团队进行近 10 年的合作。通过在图灵 TU102 、 TU104 和 TU106 GPUs 中加入称为 RT Cores 的多个新的基于硬件的光线跟踪加速引擎,结合 NVIDIA RTX 软件技术 . ,使得游戏和其他应用中的实时光线跟踪成为可能
在图灵 TU102 GPU 上实时运行的采用 RTX NVIDIA 技术的 NVIDIA SOL ray Tracking demo 的 SOL MAN 如 图 13 ( 参见演示 )。
如前所述,光栅化技术多年来一直是实时渲染的规范,尤其是在计算机游戏中,虽然许多光栅化场景看起来非常好,但基于光栅化的渲染有很大的局限性。例如,仅使用光栅化渲染反射和阴影需要简化可能导致许多不同类型瑕疵的假设。类似地,静态光照贴图可能看起来是正确的,直到有东西移动,光栅化阴影通常会出现锯齿和光泄漏,屏幕空间反射只能反射屏幕上可见的对象。这些人工制品有损于游戏体验的真实感,对于开发者和艺术家来说,试图用额外的效果来修复是非常昂贵的。
图 13 。来自 NVIDIA 的 SOL MAN 太阳射线追踪演示
虽然光线跟踪可以产生比栅格化更真实的图像,但它也需要大量的计算。我们发现最好的方法是混合渲染,光线跟踪和光栅化的结合。使用这种方法,光栅化用于最有效的地方,而光线跟踪用于与光栅化相比提供最大视觉好处的地方,例如渲染反射、折射和阴影。 图 14 显示混合渲染管道。
混合渲染结合了渲染管道中的光线跟踪和光栅化技术,以充分利用每种技术在渲染场景时的最佳效果。 SEED 为他们的 PICA-PICA 实时光线跟踪实验使用了一个混合的渲染模型,该实验在程序化组装的世界中具有自学习代理。 PICA-PICA 使用 SEED 的研发引擎 Halcyon 构建,使用 microsoftdxr 和 NVIDIA GPUs 实现实时光线跟踪。

光栅化和 z 缓冲在确定对象可见性方面要快得多,并且可以替代光线跟踪过程中的主要光线投射阶段。然后,可以使用光线跟踪来拍摄次光线,以生成高质量的物理校正反射、折射和阴影。
开发人员还可以使用材质属性阈值来确定要在场景中执行光线跟踪的区域。一种技术是规定只有具有一定反射率水平(比如 70% )的表面才会触发是否应在该表面上使用光线跟踪来生成二次光线。
我们期望许多开发人员使用混合光栅化/光线跟踪技术来获得高帧速率和出色的图像质量。或者,对于图像保真度是最高优先级的专业应用程序,我们希望看到在整个渲染工作负载中使用光线跟踪,投射主光线和次光线以创建令人惊叹的逼真渲染。
图灵 GPUs 不仅包括专用的光线跟踪加速硬件,还使用了下一节描述的高级加速结构。本质上,一个全新的渲染管道可以使用单个图灵 GPU 在游戏和其他图形应用程序中实现实时光线跟踪(参见 图 15 )。
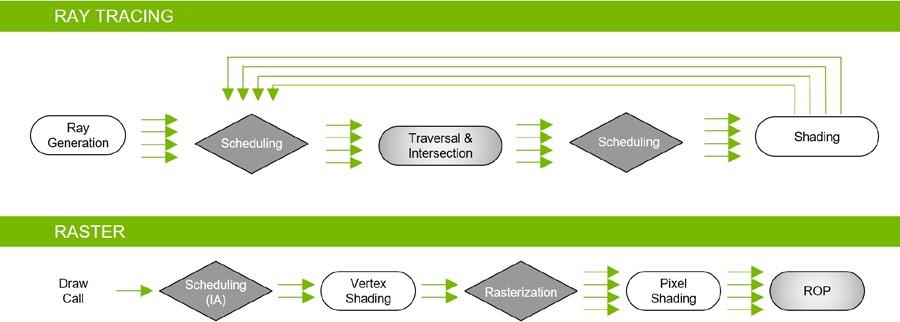
在图灵 GPUs 中使用的混合绘制模型中,光线跟踪和光栅化流水线同时工作并协同工作。
虽然图灵 GPUs 支持实时光线跟踪,但每个像素或曲面位置投射的主光线或次光线数量会根据许多因素而变化,包括场景复杂性、分辨率、场景中渲染的其他图形效果,当然还有 GPU 马力。不要期望每像素实时投射数百条光线。事实上,当使用图灵 -RT 核心加速与先进的去噪滤波技术相结合时,每像素所需的光线要少得多。
NVIDIA 实时光线跟踪去噪模块可以显著减少每个像素所需的光线数,并且仍然可以产生出色的效果。
对选定对象的实时光线跟踪可以使游戏和应用程序中的许多场景看起来与高端电影特效一样逼真,或与使用基于专业软件的非实时渲染应用程序创建的光线跟踪图像一样逼真。 图 16 显示了 Epic Games 与 ILMxLAB 和 NVIDIA 合作创建的反射演示示例。
光线跟踪反射、光线跟踪区域光阴影和光线跟踪环境光遮挡可以在单个四边形 RTX 6000 或 GeForce RTX 2080 Ti GPU 上运行,提供几乎无法与电影区分的渲染质量,如这个不真实的引擎演示所示。
图 16 。虚幻引擎反射光线跟踪演示
图灵光线跟踪硬件与 NVIDIA 的 RTX 光线跟踪技术、 NVIDIA 实时光线跟踪库、 NVIDIA OptiX 、 Microsoft DXR API 和即将推出的 Vulkan 光线跟踪 API 一起工作。用户将在游戏中以可播放的帧速率体验实时、电影级的光线跟踪对象和角色,或者在专业图形应用程序中体验到视觉真实感,而这在以前的 GPU 架构中是不可能实现的。
图灵 GPUs 可以加速光线跟踪技术,用于以下许多渲染和非渲染操作:
反射和折射
阴影和环境光遮挡
全局照明
即时离线光照图烘焙
美女照片和高质量预览
用于中心凹虚拟现实绘制的主光线
遮挡剔除
物理学,碰撞检测,粒子模拟
音频模拟(例如, NVIDIA VRWorks 音频构建在 OptiX API 之上)
AI 可见性查询
引擎内路径跟踪(非实时)生成参考屏幕截图,用于调整实时渲染技术和去噪器、材质合成和场景照明。
在下面的章节中,将详细介绍使用图灵光线跟踪加速渲染光线跟踪阴影、环境光遮挡和反射。 NVIDIA 开发者网站 有更详细的描述可以用图灵光线跟踪加速的渲染操作。
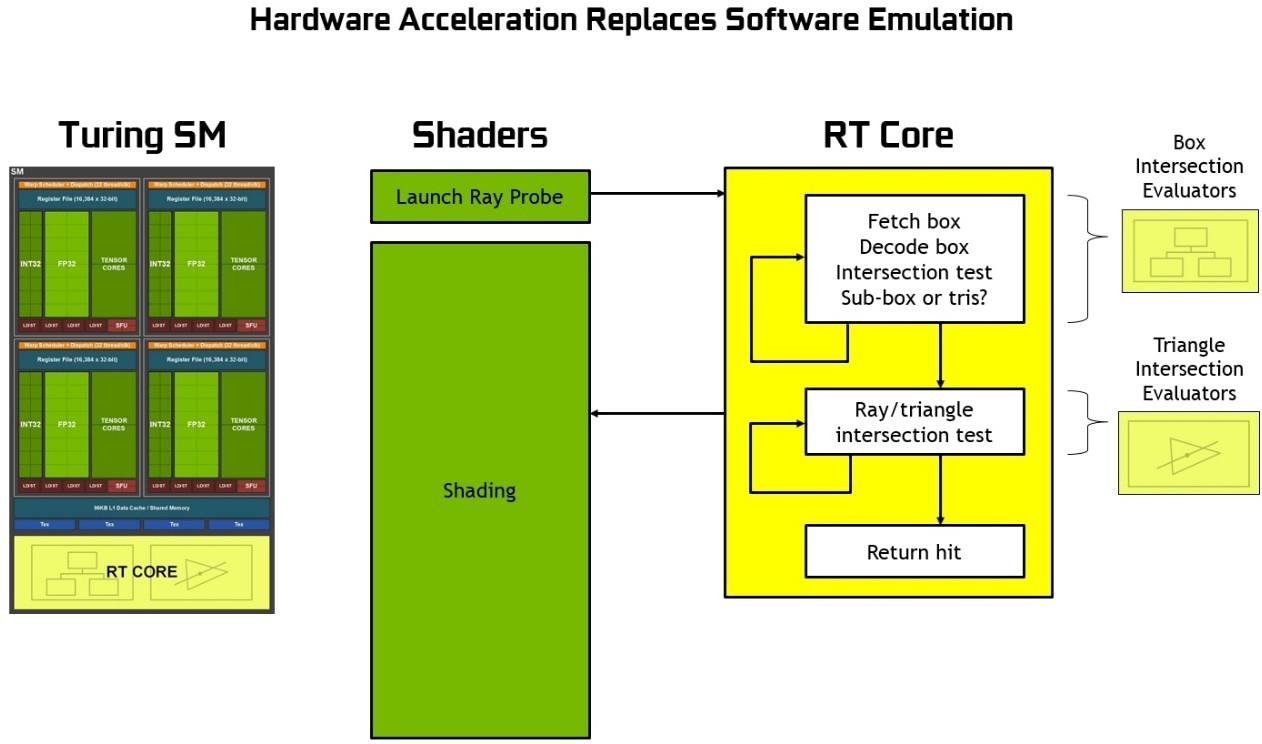
图灵 RT 核
图灵基于硬件的光线跟踪加速的核心是每个 SM 中包含的新 RT 核心。 RT 核心加速边界层( BVH )遍历和光线/三角形相交测试(光线投射)功能。 RT 核心代表在 SM 中运行的线程执行可见性测试。
RT 核与先进的去噪滤波、由 NVIDIA 研究所开发的高效 BVH 加速结构以及与 RTX 兼容的 api 一起工作,以在单个图灵 GPU 上实现实时光线跟踪。 RT 核心自动遍历 BVH ,通过加速遍历和光线/三角形相交测试,他们卸载了 SM ,允许它处理其他顶点、像素和计算着色工作。诸如 BVH 构建和重新安装等功能由驱动程序处理,光线生成和着色由应用程序通过新型着色器进行管理。
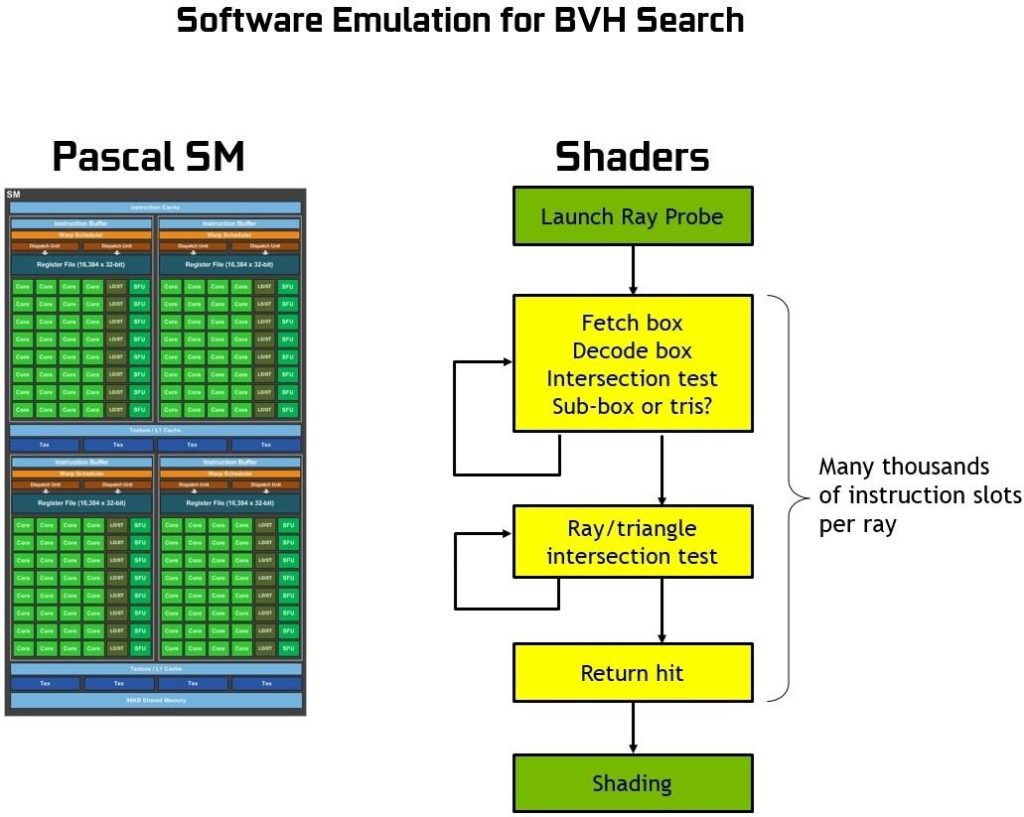
为了更好地理解 RT 核心的功能,以及它们究竟加速了什么,我们首先应该解释在没有专用硬件光线跟踪引擎的情况下如何在 GPUs 或 CPU 上执行光线跟踪。本质上, BVH 遍历的过程需要通过着色操作来执行,并且每光线投射需要数千个指令槽来测试 BVH 中的包围盒相交,直到最后碰到一个三角形,并且相交点的颜色对最终像素颜色有贡献(或者如果没有碰到三角形,则背景颜色可用于着色像素)。
没有硬件加速的光线跟踪需要每个光线数千个软件指令槽来连续测试 BVH 结构中较小的边界框,直到可能碰到三角形为止。这是一个计算密集的过程,如果没有基于硬件的光线跟踪加速,就不可能在 GPUs 上进行实时操作(请参见 图 17 )。
图灵中的 RT 核可以处理所有的 BVH 遍历和射线三角形相交测试,从而节省了 SM 在每条光线上花费数千个指令槽的开销,这可能是整个场景的大量指令。 RT 核心包括两个专门单元。第一个单元执行边界框测试,第二个单元执行光线三角形相交测试。 SM 只需启动一个光线探测器, RT 核心进行 BVH 遍历和光线三角形测试,并返回一个命中或未命中 SM 。 SM 在很大程度上被腾出去做其他的图形或计算工作。参见图 18 或使用 RT 核心的图灵射线追踪图。
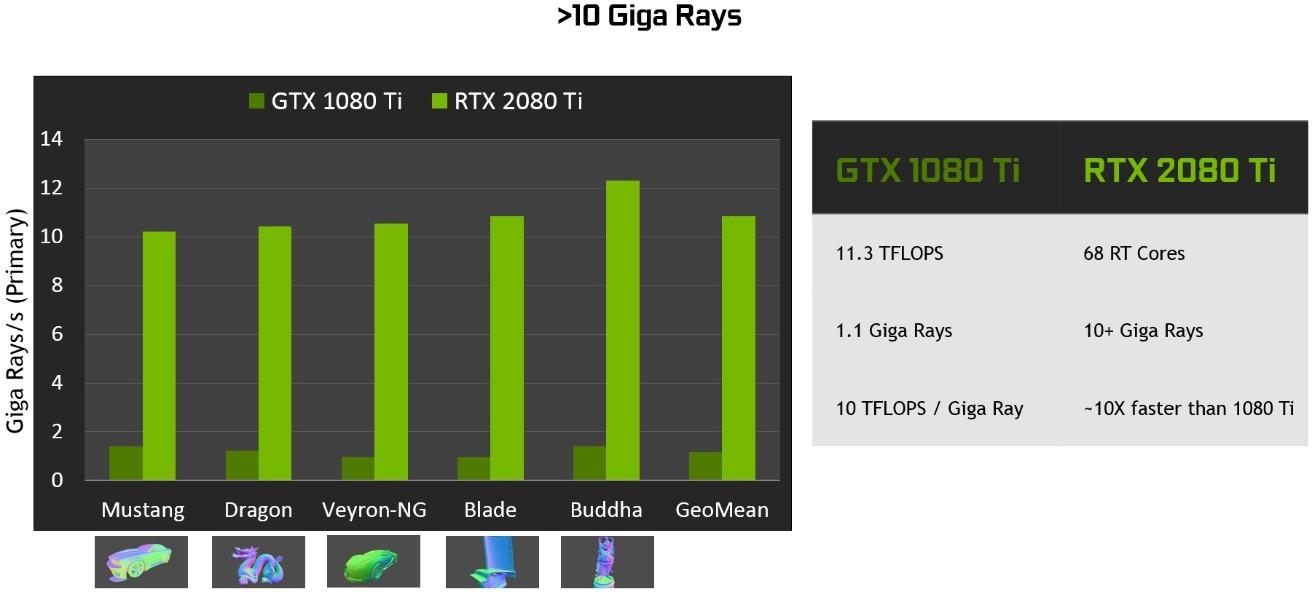
在 Pascal GPUs 中, RT 核的图灵射线跟踪性能明显快于光线跟踪。在不同的工作负载下,图灵可以比 Pascal 提供更多的千兆射线/秒,如 图 19 。 所示, Pascal 在软件中花费大约 1 . 1 千兆射线/秒,或 10 TFLOPS / gigaray 来进行光线跟踪,而图灵可以使用 RT 核来实现 10 + Giga 射线/秒,并且运行光线跟踪的速度是 Pascal 的 10 倍。
深度学习超级抽样( DLSS )
在现代游戏中,渲染帧不是直接显示的,而是经过一个后处理图像增强步骤,该步骤将来自多个渲染帧的输入合并在一起,试图在保留细节的同时去除诸如锯齿之类的视觉伪影。例如,时间反走样( TAA )是一种基于着色器的算法,它使用运动矢量将两个帧组合在一起,以确定在何处对前一帧进行采样,这是当今最常用的图像增强算法之一。然而,这种图像增强过程从根本上说是很难实现的。
NVIDIA 的研究人员认识到,这类问题——一个没有清晰算法解决方案的图像分析和优化问题——将是人工智能的完美应用。正如本文前面所讨论的,图像处理案例(例如 ImageNet )是深度学习最成功的应用之一。深度学习现在已经取得了超人的能力,可以通过观察图像中的原始像素来识别狗、猫、鸟等。在这种情况下,目标将是结合渲染图像,基于观察原始像素,以产生高质量的结果 – 一个不同的目标,但使用相似的能力。
为解决这一难题而开发的深度神经网络( DNN )被称为深度学习超级采样( DLSS )。 DLSS 从一组给定的输入样本中产生比 TAA 更高质量的输出,我们利用这种能力来提高整体性能。
虽然 TAA 在最终目标分辨率下渲染,然后合并帧,减去细节, DLSS 允许以较低的输入采样数进行更快的渲染,然后推断出在目标分辨率下质量与 TAA 结果相似的结果,但着色工作只有一半。
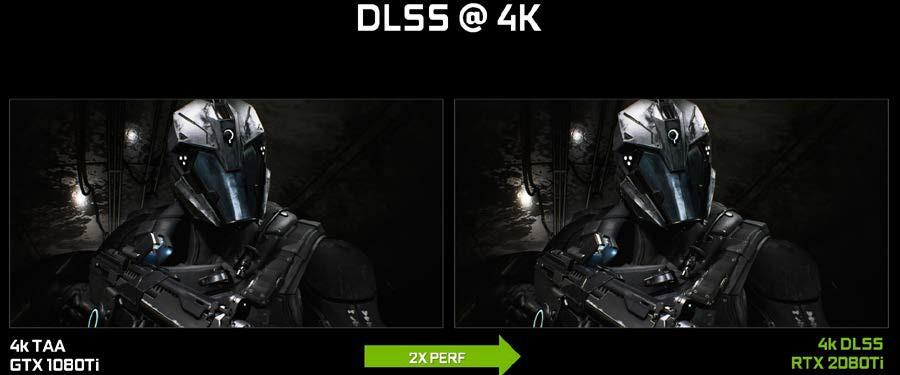
下面的 图 20 , 显示了 UE4 渗透器演示的结果示例。 DLSS 提供了与 TAA 类似的图像质量,并大大提高了性能。 RTX 2080 Ti 更快的原始渲染马力,加上 DLSS 和张量核心的性能提升,使 RTX 2080 Ti 的性能达到 GTX 1080 Ti 的两倍。
这一结果的关键是 DLSS 的培训过程,在培训过程中, DLSS 有机会学习如何根据大量超高质量的示例生成所需的输出。为了训练网络,我们收集了数以千计的“真实”参考图像,这些参考图像采用了完美图像质量的黄金标准方法 64x 超采样( 64xSS )。 64x 超采样意味着我们不必对每个像素进行一次着色处理,而是在像素内以 64 个不同的偏移量进行着色处理,然后结合输出,生成具有理想细节和抗锯齿质量的结果图像。我们还捕捉匹配的原始输入图像正常渲染。接下来,我们开始训练 DLSS 网络以匹配 64xSS 输出帧,方法是遍历每个输入,要求 DLSS 生成一个输出,测量其输出与 64xSS 目标之间的差异,并根据差异通过称为反向传播的过程调整网络中的权重。
经过多次迭代后, DLSS 会自行学习生成接近 64xs 质量的结果,同时也会学习避免影响 TAA 等经典方法的模糊、混淆和透明性问题。
除了上述 DLSS 功能(标准 DLSS 模式)之外,我们还提供了第二种模式,称为 DLSS 2X 。在这种情况下, DLSS 输入将以最终目标分辨率呈现,然后由更大的 DLSS 网络组合,生成接近 64x 超级采样渲染级别的输出图像–这一结果将用任何传统方法都不可能实时实现。图 21 显示了 DLSS 2X 模式的运行,提供的图像质量非常接近参考 64x 超级采样图像。

最后,图 22 说明了多帧图像增强的一个具有挑战性的案例。在这种情况下,一个半透明的屏幕漂浮在移动不同的背景前面。 TAA 倾向于盲目跟踪运动对象的运动矢量,模糊了屏幕上的细节。 DLSS 能够识别出场景中的变化更为复杂,并以更智能的方式组合输入,从而避免模糊问题。

总结
图形刚刚被革新。新的 NVIDIA Turing GPU 架构是有史以来最先进、最高效的 GPU 架构。图灵实现了一种新的混合渲染模型,它结合了实时光线跟踪、栅格化、人工智能和模拟。图灵与下一代图形 API 相结合,为 PC 游戏和专业应用程序带来了巨大的性能提升和难以置信的逼真图形。
未来的博客文章将包括更多关于图灵高级着色器技术的细节。如果您想深入研究图灵架构,请下载完整的 NVIDIA 图灵体系结构白皮书 。您也可以在 RTX 开发者页面 上找到有关 RTX 技术的更多信息,或者阅读如何 RTX 和 directx12 射线跟踪工作 here 。




