 在过去的几年里, NVIDIA 以各种方式利用 GPU 容器来测试、开发和大规模运行生产中的 AI 工作负载。为 NVIDIA GPUs 优化的容器和 DGX 和 OEM NGC Ready 服务器等系统可作为 NGC 的一部分提供。
在过去的几年里, NVIDIA 以各种方式利用 GPU 容器来测试、开发和大规模运行生产中的 AI 工作负载。为 NVIDIA GPUs 优化的容器和 DGX 和 OEM NGC Ready 服务器等系统可作为 NGC 的一部分提供。
但是用 GPUs 可靠地提供服务器并扩展人工智能应用程序可能会很棘手。 Kubernetes 凭借其丰富的应用程序可扩展性和高性能特性迅速构建在其平台上。
Kubernetes 通过设备插件 框架 提供对特殊硬件资源的访问,如 NVIDIA GPUs 、 NICs 、 Infiniband 适配器和其他设备。但是,使用这些硬件资源配置和管理节点需要配置多个软件组件,例如驱动程序、容器运行时或其他库,这些组件很难并且容易出错。
Kubernetes 中的 运营商框架 采用操作业务逻辑,并允许使用标准的 Kubernetes API 和 kubectl 创建用于在 Kubernetes 内部署应用程序的自动化框架。这里介绍的 NVIDIA GPU 操作程序基于操作员框架,并自动管理所有 NVIDIA 软件在 Kubernetes 中提供 GPUs 所需的组件。 NVIDIA 、 redhat 和社区中的其他人合作创建了 GPU 操作符。 GPU 运营商是 NVIDIA EGX 软件定义平台的一个重要组成部分,该平台旨在使大规模混合云和边缘操作成为可能和高效。
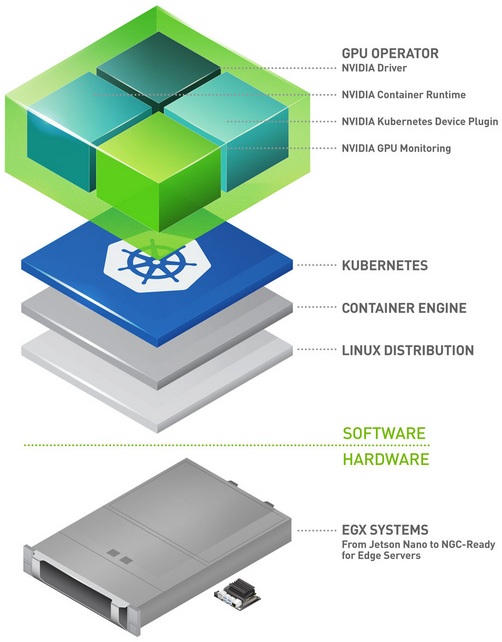
NVIDIA GPU 操作员
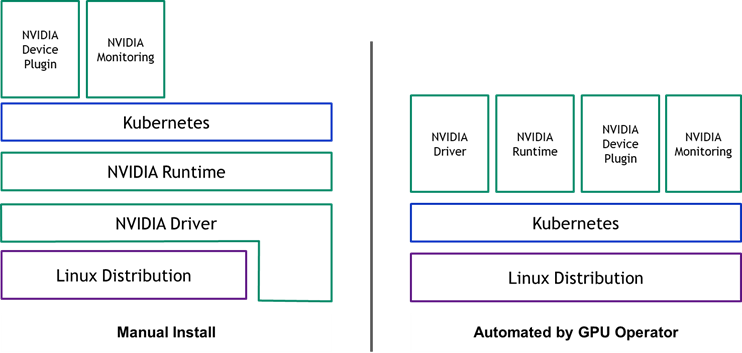
要在 Kubernetes 集群中配置 GPU 个工作节点,需要以下 NVIDIA 软件组件 – 驱动程序、容器运行时、设备插件和监控。如图 1 所示,这些组件需要在集群可用的 GPU 资源之前手动配置,并且在集群运行期间也需要进行管理。 GPU 运营商通过将所有组件打包并使用标准 Kubernetes api 自动化和管理这些组件(包括版本控制和升级),简化了组件的初始部署和管理。 GPU 操作符是完全开源的,可以在我们的 GitHub 库 上使用。
操作员状态机
GPU 运算符基于 Kubernetes 中的 运营商框架 。操作符被构建为一个新的自定义资源定义( CRD ) API ,并带有相应的控制器。该操作符在自己的命名空间(称为“ GPU -operator ”)中运行,底层的 NVIDIA 组件在单独的命名空间中编排(称为“ GPU -operator resources ”)。与 Kubernetes 中的任何标准操作符一样,控制器监视名称空间的更改,并使用协调循环(通过 reconcile ()函数)来实现一个简单的状态机来启动每个 NVIDIA 组件。状态机在每个状态下都包含一个验证步骤,如果失败,协调循环将退出并返回错误。如图 2 所示。
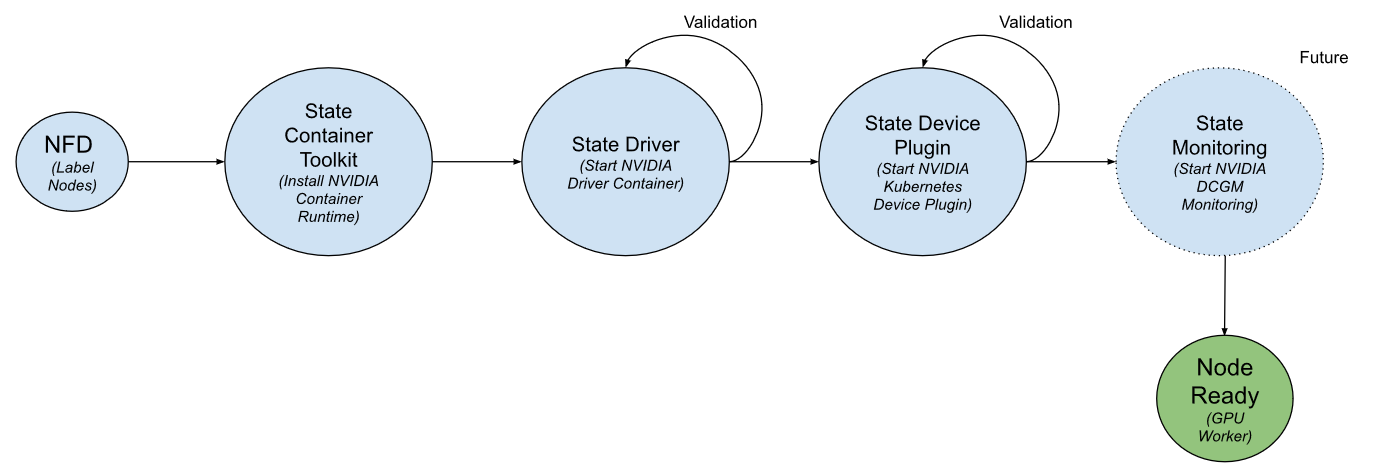
GPU 运算符应该在配备了 GPUs 的节点上运行。为了确定哪些节点具有 GPUs ,操作符依赖于 Kubernetes 中的 节点功能发现 ( NFD )。 NFD worker 检测节点上的各种硬件功能–例如, PCIe 设备标识、内核版本、内存和其他属性。然后它使用节点标签向 Kubernetes 发布这些特性。然后, GPU 操作员使用这些节点标签(通过检查 PCIe 设备 id )来确定是否应在节点上配置 NVIDIA 软件组件。在这个初始版本中, GPU 操作员当前部署了 NVIDIA 容器运行时 、 NVIDIA 集装箱驱动程序 和 NVIDIA 调速器设备插件 。未来,运营商还将管理其他组件,如 基于 DCGM 监控。
让我们简单地看一下不同的状态。
状态容器工具包
此状态将部署一个守护进程,该守护进程通过 容器 在主机系统上安装 NVIDIA 容器运行时。守护进程使用 NFD 标签中的 PCIe 设备 id ,仅在具有 GPU 资源的节点上安装运行时。 PCIe 设备 id 0x10DE 是 NVIDIA 的供应商 id 。
nodeSelector: feature.node.kubernetes.io/pci-10de.present: "true"
状态驱动程序
此状态将部署一个带有容器化的 NVIDIA 驱动程序的守护进程。您可以阅读有关驱动程序容器 在这里 的更多信息。在启动时,驱动程序容器可以构建最终的 NVIDIA 内核模块,并将它们加载到主机上的 Linux 内核中,以准备运行 CUDA 应用程序并在后台运行。驱动程序容器包括应用程序所需的驱动程序的用户模式组件。同样,守护进程使用 NFD 标签来选择要在其上部署驱动程序容器的节点。
状态驱动程序验证
如上所述,操作员状态机包括验证步骤,以确保组件已成功启动。操作员调度一个简单的 CUDA 工作负载(在本例中是一个 vectorAdd 示例)。如果应用程序运行时没有任何错误,则容器状态为“成功”。
状态设备插件
此状态为 NVIDIA Kubernetes 设备插件部署守护进程。它将节点上的 GPUs 列表注册到 kubelet 中,这样就可以将 GPUs 分配给 CUDA 个工作负载。
状态设备插件验证
在这种状态下,验证容器请求 Kubernetes 分配 GPU ,并运行一个简单的 CUDA 工作负载(如上所述),以检查设备插件是否注册了资源列表以及工作负载是否成功运行(即容器状态为“ Success ”)。
为了简化 GPU 操作员本身的部署, NVIDIA 提供了一个舵图。用户可以使用驱动程序自定义的插件版本(值. yaml )在舵图上。然后,操作员使用模板值在节点上提供所需的软件版本。这为用户提供了一个参数化级别。
运行 GPU 运算符
让我们快速了解一下如何部署 GPU 操作符并运行 CUDA 工作负载。在这一点上,我们假设您有一个 Kubernetes 集群在运行(即主控制平面可用,工作节点已经加入集群)。为了让这篇博文更简单,我们将使用一个运行 ubuntu18 . 04 . 3lts 的 NVIDIA Tesla T4GPU 的单节点 Kubernetes 集群。
GPU 操作符本身并没有解决 Kubernetes 集群的设置问题,目前有很多解决方案 可获得的 可以用于此目的。 NVIDIA 正在与不同的合作伙伴合作,将 GPU 运营商整合到他们管理 GPUs 的解决方案中。
让我们验证一下我们的 Kubernetes 集群(以及带有 Tiller 的 Helm 设置)是否可以运行。请注意,虽然节点有一个 GPU ,但节点上没有部署 NVIDIA 软件组件–我们将使用 GPU 操作符来配置组件。
$ sudo kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-6fcc7d5fd6-n2dnt 1/1 Running 0 6m45s kube-system calico-node-77hjv 1/1 Running 0 6m45s kube-system coredns-5c98db65d4-cg6st 1/1 Running 0 7m10s kube-system coredns-5c98db65d4-kfl6v 1/1 Running 0 7m10s kube-system etcd-ip-172-31-5-174 1/1 Running 0 6m5s kube-system kube-apiserver-ip-172-31-5-174 1/1 Running 0 6m11s kube-system kube-controller-manager-ip-172-31-5-174 1/1 Running 0 6m26s kube-system kube-proxy-mbnsg 1/1 Running 0 7m10s kube-system kube-scheduler-ip-172-31-5-174 1/1 Running 0 6m18s kube-system tiller-deploy-8557598fbc-hrrhd 1/1 Running 0 21s
一个单节点 Kubernetes 集群(主节点未被污染,因此可以运行工作负载)
$ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-172-31-5-174 Ready master 3m2s v1.15.3
我们可以看到节点有一个 NVIDIA GPU ,但没有安装驱动程序或其他软件工具。
$ lspci | grep -i nvidia 00:1e.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1) $ nvidia-smi nvidia-smi: command not found
作为先决条件,让我们确保在系统上设置了一些内核模块。这些模块的 NVIDIA 依赖于某些驱动程序。
$ sudo modprobe -a i2c_core ipmi_msghandler
现在,让我们继续部署 GPU 操作符。为此,我们将使用 NGC 提供的舵面图。首先,添加 Helm 回购:
$ helm repo add nvidia https://helm.ngc.nvidia.com/nvidia "nvidia" has been added to your repositories $ helm repo update Hang tight while we grab the latest from your chart repositories... ...Skip local chart repository ...Successfully got an update from the "nvidia" chart repository ...Successfully got an update from the "stable" chart repository Update Complete.
然后用图表部署操作员
$ helm install --devel nvidia/gpu-operator -n test-operator --wait $ kubectl apply -f https://raw.githubusercontent.com/NVIDIA/gpu-operator/master/manifests/cr/sro_cr_sched_none.yaml specialresource.sro.openshift.io/gpu created
我们可以验证 GPU 操作符是否在它自己的命名空间中运行,并且正在监视另一个命名空间中的组件。
$ kubectl get pods -n gpu-operator NAME READY STATUS RESTARTS AGE special-resource-operator-7654cd5d88-w5jbf 1/1 Running 0 98s
几分钟后, GPU 操作员将部署所有 NVIDIA 软件组件。输出还显示了作为 GPU 操作符状态机一部分运行的验证容器。示例 CUDA 容器( vectorAdd )已作为状态机的一部分成功完成。
$ kubectl get pods -n gpu-operator-resources NAME READY STATUS RESTARTS AGE nvidia-container-toolkit-daemonset-wwzfn 1/1 Running 0 3m36s nvidia-device-plugin-daemonset-pwfq7 1/1 Running 0 101s nvidia-device-plugin-validation 0/1 Completed 0 92s nvidia-driver-daemonset-skpn7 1/1 Running 0 3m27s nvidia-driver-validation 0/1 Completed 0 3m $ kubectl -n gpu-operator-resources logs -f nvidia-device-plugin-validation [Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
我们还可以看到 NFD 用不同的属性标记了节点。已为 NVIDIA GPU 设置了具有 PCIe 设备 id 0x10DE 的节点标签。
$ kubectl -n node-feature-discovery logs -f nfd-worker-zsjsp 2019/10/21 00:46:25 cpu-cpuid.AVX512F = true 2019/10/21 00:46:25 cpu-hardware_multithreading = true 2019/10/21 00:46:25 cpu-cpuid.AVX = true 2019/10/21 00:46:25 cpu-cpuid.AVX512VL = true 2019/10/21 00:46:25 cpu-cpuid.AVX512CD = true 2019/10/21 00:46:25 cpu-cpuid.AVX2 = true 2019/10/21 00:46:25 cpu-cpuid.FMA3 = true 2019/10/21 00:46:25 cpu-cpuid.ADX = true 2019/10/21 00:46:25 cpu-cpuid.AVX512DQ = true 2019/10/21 00:46:25 cpu-cpuid.AESNI = true 2019/10/21 00:46:25 cpu-cpuid.AVX512BW = true 2019/10/21 00:46:25 cpu-cpuid.MPX = true 2019/10/21 00:46:25 kernel-config.NO_HZ = true 2019/10/21 00:46:25 kernel-config.NO_HZ_IDLE = true 2019/10/21 00:46:25 kernel-version.full = 4.15.0-1051-aws 2019/10/21 00:46:25 kernel-version.major = 4 2019/10/21 00:46:25 kernel-version.minor = 15 2019/10/21 00:46:25 kernel-version.revision = 0 2019/10/21 00:46:25 pci-10de.present = true 2019/10/21 00:46:25 pci-1d0f.present = true 2019/10/21 00:46:25 storage-nonrotationaldisk = true 2019/10/21 00:46:25 system-os_release.ID = ubuntu 2019/10/21 00:46:25 system-os_release.VERSION_ID = 18.04 2019/10/21 00:46:25 system-os_release.VERSION_ID.major = 18 2019/10/21 00:46:25 system-os_release.VERSION_ID.minor = 04
让我们启动一个 TensorFlow 笔记本。 GitHub repo 上有一个示例清单,让我们使用它
$ kubectl apply -f https://nvidia.github.io/gpu-operator/notebook-example.yml
一旦 pod 被创建,我们就可以使用令牌在浏览器窗口中查看笔记本。
$ kubectl logs -f tf-notebook [C 02:52:44.849 NotebookApp] Copy/paste this URL into your browser when you connect for the first time, to login with a token: http://localhost:8888/?token=b7881f90dfb6c8c5892cff7e8232684f201c846c48da81c9
我们可以使用端口转发或使用节点端口 30001 到达容器。使用上面日志中的 URL 在浏览器中打开 Jupyter 笔记本。
$ kubectl port-forward tf-notebook 8888:8888

现在您可以看到 Jupyter 主页并继续您的工作流 – 所有这些都在 Kubernetes 中运行,并通过 GPUs 加速!
结论
如果您有任何问题或意见,请在下面的评论部分留下。对于有关安装和使用的技术问题,我们建议在 GitHub 上提交一个问题。




