在计算机视觉和模式识别会议( CVPR )上, NVIDIA 研究人员发表了 35 多篇论文。这包括对 移动窗口 UNEt TRansformers ( Swin-UNETR )的研究,这是第一个基于变压器的预训练框架,专为 3D 医学图像分析中的自我监督任务而设计。这项研究是创建用于数据注释的预训练、大规模和自监督三维模型的第一步。
作为一种基于 transformer 的计算机视觉方法, Swin UNETR 采用了 MONAI ,这是一种开源的 PyTorch 框架,用于深入学习医疗成像,包括放射学和病理学。使用这种预训练方案, Swin UNETR 为各种医学图像分割任务设定了新的最先进的基准,并一致证明了其有效性,即使只有少量的标记数据。
Swin UNETR 模型培训
Swin UNETR 模型在 NVIDIA DGX-1 集群 使用八个 GPU 和 AdamW 优化算法。对 5050 张来自健康和不健康受试者不同身体部位的公开 CT 图像进行预训练,以保持数据集的平衡。
对于 3D Swin transformer 编码器的自我监督预训练,研究人员使用了各种借口任务。随机裁剪的标记使用不同的变换(如旋转和剪切)进行增强。这些标记用于掩蔽体修复、旋转和对比学习,用于编码器学习训练数据的上下文表示,而不会增加数据注释的负担。
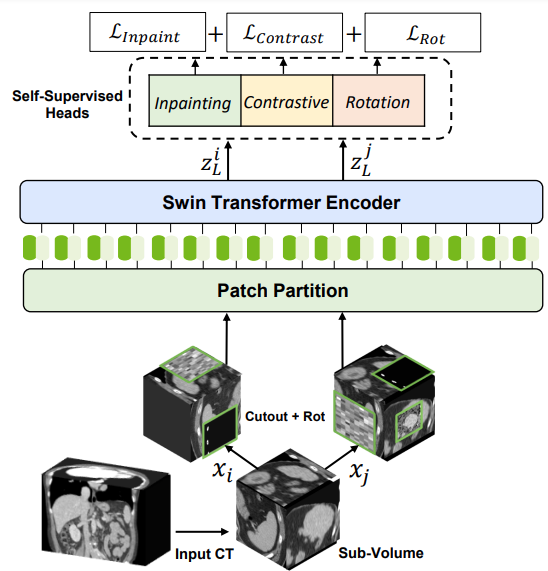
Swin UNETR 背后的技术
Swin Transformers 采用分层视觉 transformer ( ViT )进行非重叠窗口的局部自我注意计算。这打开了为大型公司创建医疗专用 ImageNet 的机会,消除了创建医疗 AI 模型需要大量高质量注释数据集的瓶颈。
与 CNN 体系结构相比, ViT 在从未标记数据(数据集越大,预训练主干越强)进行全局和局部表示的自监督学习方面表现出非凡的能力。用户可以在下游任务(例如,分割、分类和检测)中使用极少量的标记数据微调预训练模型。
这种体系结构在本地窗口中计算自我注意,与 ViT 相比表现出更好的性能。此外, Swin Transformers 的层次性使其非常适合需要多尺度建模的任务。
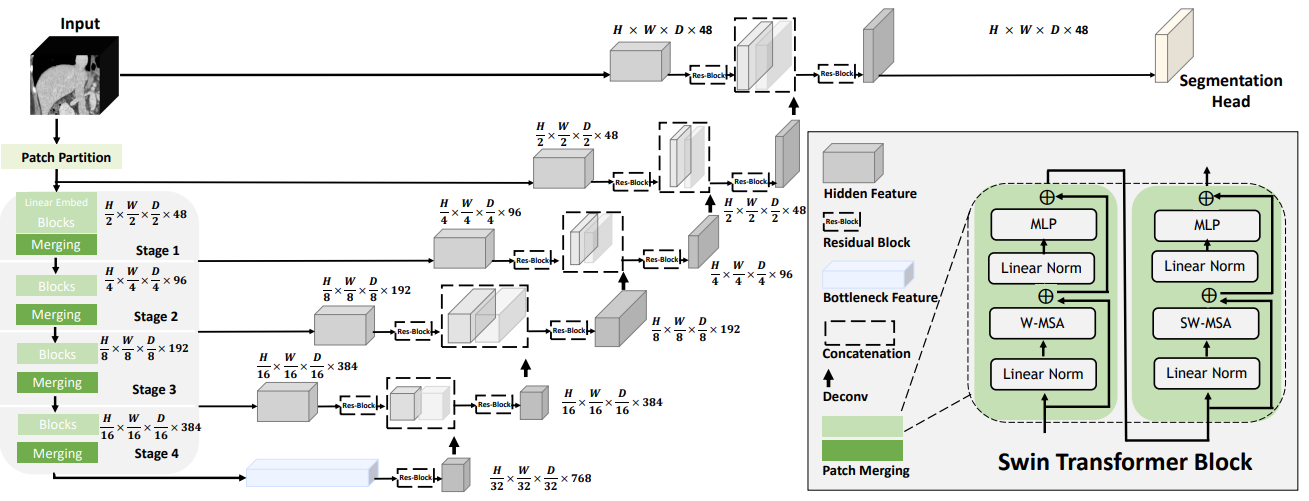
继领先的 UNETR 模型成功使用直接使用 3D 补丁嵌入的基于 ViT 的编码器之后, Swin UNETR 使用了具有金字塔结构的 3D Swin transformer 编码器。
在 Swin UNETR 的编码器中,由于计算简单的全局自我注意对于高分辨率特征地图是不可行的,因此在本地窗口中计算自我注意。为了增加局部窗口以外的感受野,使用窗口移位来计算不同窗口的区域相互作用。
Swin UNETR 的编码器通过跳过连接以五种不同的分辨率连接到剩余的类似 UNet 的解码器。它可以为密集的预测任务(如医学图像分割)捕获多尺度特征表示。
Swin UNETR 模型性能
在对 CT 中的 13 个腹部器官和 医学分段十项全能( MSD ) 数据集中的分割任务使用 超越颅穹窿( BTCV )分割挑战 进行微调后,该模型在公共排行榜上达到了最先进的精度。
BTCV
在 BTCV 中, SwinUnetr 的平均骰子数为 0.918 ,优于其他排名靠前的模型。
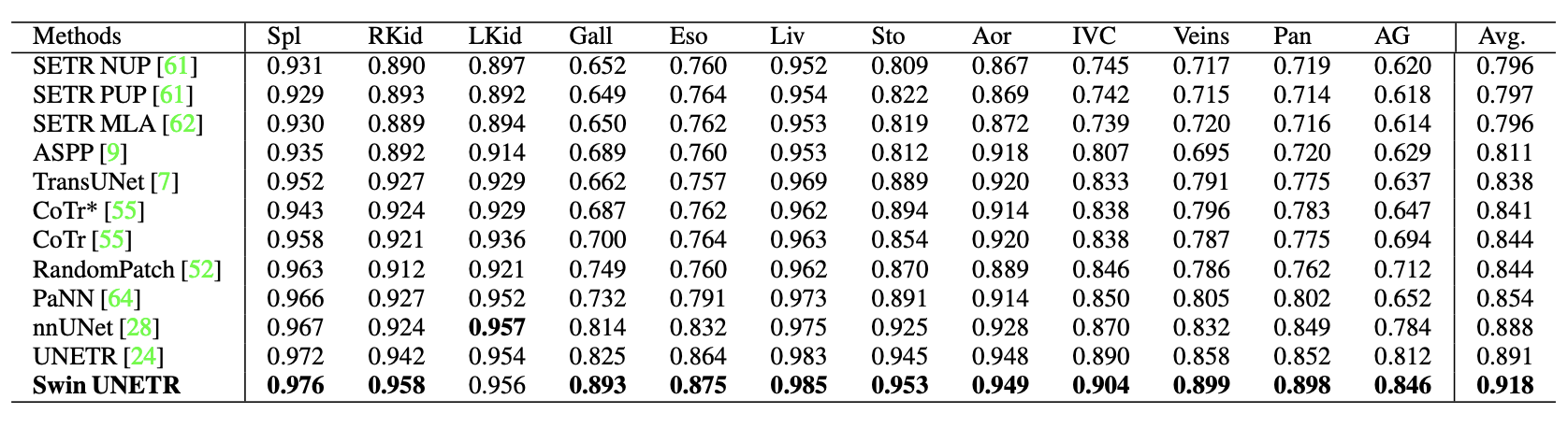
对于较小的器官,如脾静脉和门静脉( 3.6% )、胰腺( 1.6% )和肾上腺( 3.8% ),与之前的最先进方法相比,有了改进小器官数据标签分割对于放射科医生来说是一项极其困难的任务。下图显示了改进情况。
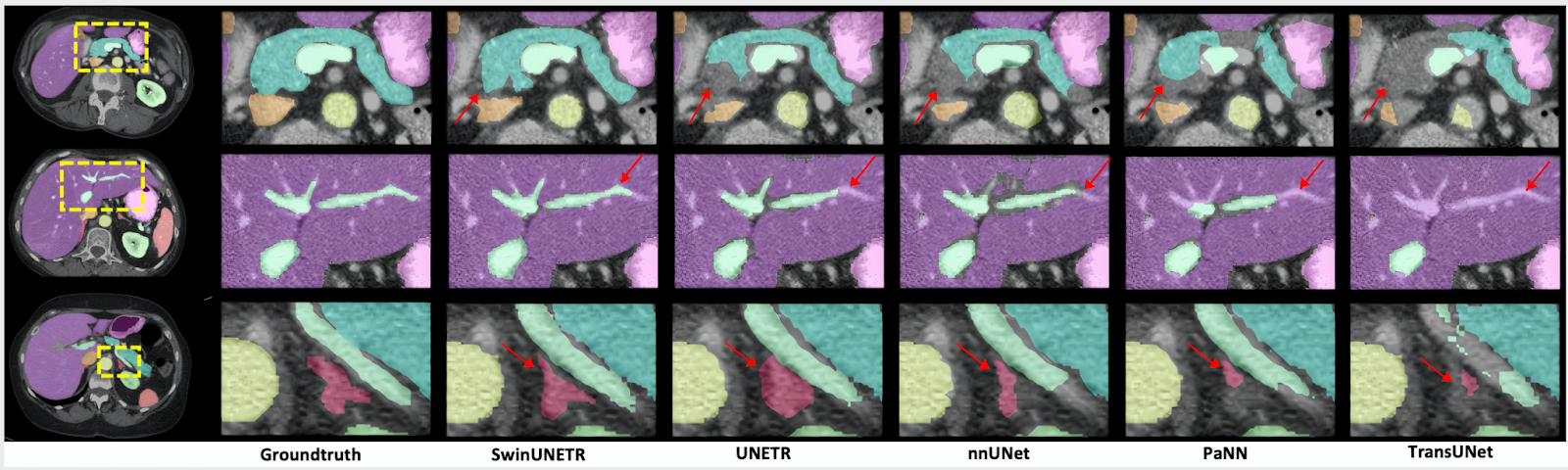
通讯簿标签
在 MSD 中, Swin UNETR 在脑肿瘤、肺、胰腺和结肠方面取得了最先进的表现。心脏、肝脏、海马、前列腺、肝血管和脾脏的结果具有可比性。总的来说, Swin UNETR 在所有 10 项任务中的平均骰子率为 78.68% ,是最好的,并在 MSD 排行榜上排名第一。
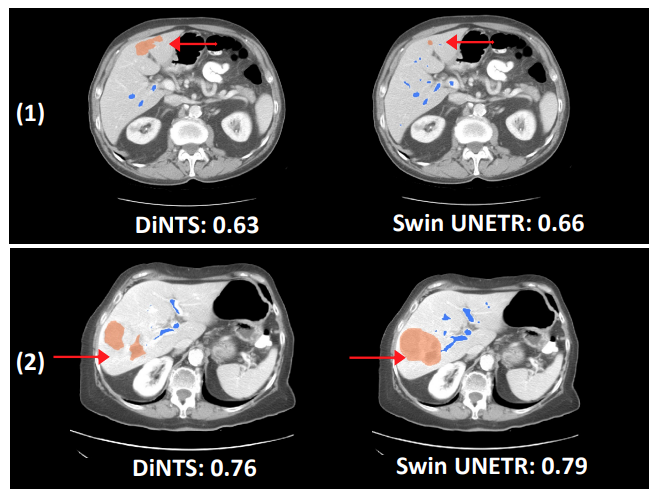
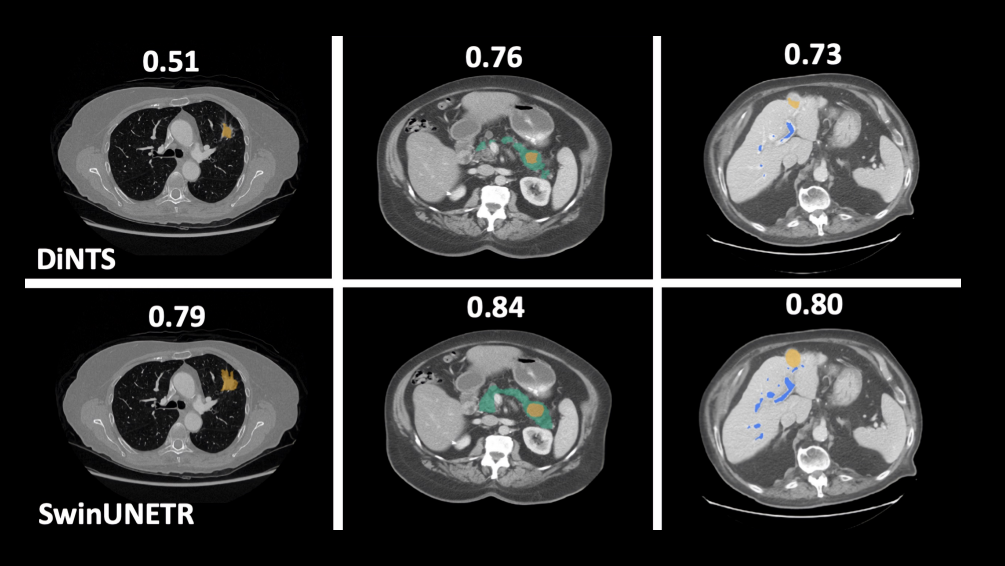
与DiNTS(一种用于医学图像分割的强大AutoML方法)相比,Swin UNETR使用更少的训练时间,显示出更好的分割性能。例如,肝血管分割任务的定性分割输出证明了Swin UNETR能够更好地建模长期空间依赖性。
结论
Swin UNETR 体系结构在使用变压器的医疗成像方面提供了急需的突破。鉴于医学成像需要快速构建准确的模型, Swin UNETR 体系结构使数据科学家能够对大量未标记数据进行预训练。这减少了放射科医生、病理学家和其他临床团队进行专家注释的成本和时间。这里我们展示了用于器官检测和自动体积测量的 SOTA 分割性能。
要了解更多信息:
- 请在 CVPR conference 上查看此项工作。
- 阅读研究 Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis.。
- 下载 GitHub 上的 SwinueTr 代码 。