
在 MLPerf HPC v1 . 0 中, NVIDIA 供电系统赢得了五项新的行业指标中的四项,这些指标主要关注 HPC 中的人工智能性能。作为一个全行业人工智能联盟, MLPerf HPC 评估了一套性能基准,涵盖了广泛使用的人工智能工作负载。
在这一轮中,与 MLPerf 0 . 7 的强大扩展性结果相比, NVIDIA 在 CosmoFlow 上的性能提高了 5 倍,在 DeepCAM 上的性能提高了 7 倍。这一强大的表现得益于成熟的 NVIDIA AI 平台和全套软件。
提供丰富多样的库、 SDK 、工具、编译器和探查器,很难知道在正确的情况下何时何地应用正确的资产。这篇文章详细介绍了各种场景的工具、技术和好处,并概述了 CosmoFlow 和 DeepCAM 基准测试所取得的成果。
我们已经为 MLPerf Training v1.0 和 MLPerf Inference v1.1 发布了类似的指南,推荐用于其他面向基准测试的案例。
调整计划
我们使用包括 NVIDIA DALI 在内的工具对代码进行了优化,以加速数据处理,以及 CUDA Graphs 减少了小批量延迟,从而有效地扩展到 1024 个或更多 GPU 。我们还应用了 NVIDIA SHARP ,通过将一些操作卸载到网络交换机来加速通信。
我们提交的文件中使用的软件可从 MLPerf repository 获得。我们定期向 NGC catalog 添加新工具和新版本,这是我们针对预训练 AI 模型、行业应用程序框架、 GPU 应用程序和其他软件资源的软件中心。
主要性能优化
在本节中,我们将深入讨论为 MLPerf HPC 1 . 0 实现的选定优化。
使用 NVIDIA DALI 库进行数据预处理
在每次迭代之前,从磁盘获取数据并进行预处理。我们从默认的数据加载器移到了 NVIDIA DALI library 。这为 GPU 提供了优化的数据加载和预处理功能。
DALI 库使用 CPU 和 GPU 的组合,而不是在 CPU 上执行数据加载和预处理并将结果移动到 GPU 。这将为即将到来的迭代带来更有效的数据预处理。优化后, CosmoFlow 和 DeepCAM 的速度都显著加快。 DeepCAM 实现了超过 50% 的端到端性能提升。
此外, DALI 还为即将到来的迭代提供异步数据加载,以消除关键路径的 I / O 开销。启用此模式后,我们看到 DeepCAM 额外增加了 70% 。
将通道应用于最后的 NHWC 布局
默认情况下, DeepCAM 基准使用 NCHW 布局作为激活张量。我们使用 PyTorch 的通道 last ( NHWC 布局)支持来避免额外的转置内核。 cuDNN 中的大多数卷积核都针对 NHWC 布局进行了优化。
因此,在框架中使用 NCHW 布局需要额外的转置内核,以便从 NCHW 转换到 NHWC ,从而实现高效的卷积运算。在框架中使用 NHWC 布局避免了这些冗余拷贝,并在 DeepCAM 模型上实现了约 10% 的性能提升。 NHWC support 在 PyTorch 框架中以 beta 模式提供。
CUDA 图
CUDA 图形允许启动由一系列内核组成的单个图形,而不是单独启动从 CPU 到 GPU 的每个内核。此功能最大限度地减少了 CPU 在每次迭代中的参与,通过最大限度地减少延迟(尤其是在强扩展场景中)显著提高了性能。
MXNet 先前添加了 CUDA 图形支持,而 CUDA Graphs support 最近也添加到了 PyTorch 。 PyTorch 中的 CUDA 图形支持使 DeepCAM 在强扩展场景中的端到端性能提高了约 15% ,这对延迟和抖动最为敏感。
使用 MPI 进行高效的数据暂存
在伸缩性较弱的情况下,分布式文件系统的性能无法满足 GPU 的需求。为了增加总存储带宽,我们将数据集放入 DeepCAM 的节点本地 NVME 内存中。
由于各个实例都很小,我们可以静态地分割数据,因此每个节点只需要准备完整数据集的一小部分。该解决方案如图 1 所示。这里,我们用 M 表示实例数,用 N 表示每个实例的秩数。
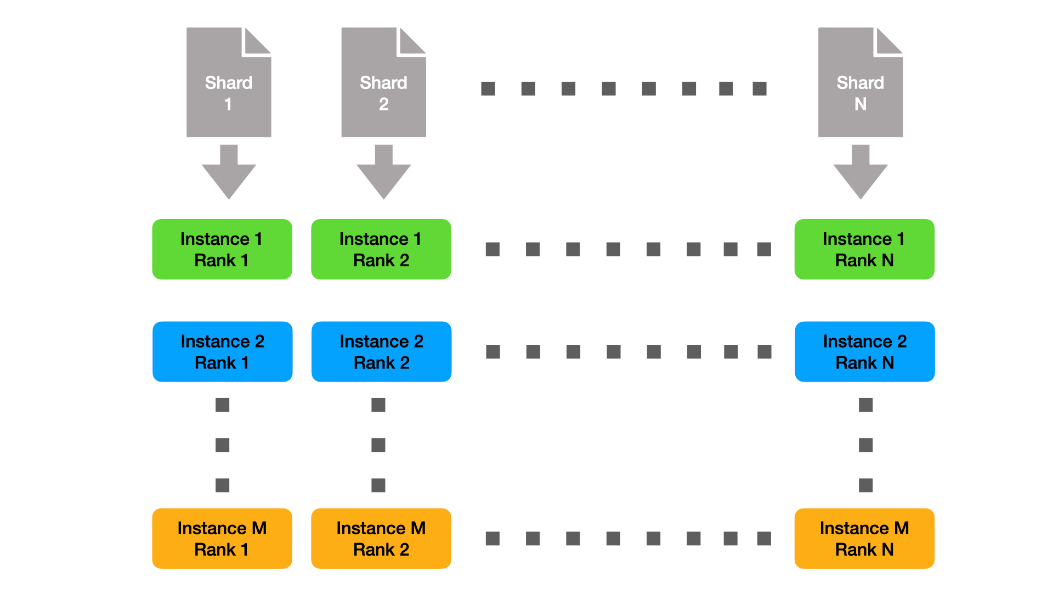
请注意,跨实例,具有相同列组 ID 的每个列组使用相同的数据碎片。这意味着在本机上,每个数据碎片被读取 M 次。为了减轻文件系统的压力,我们创建了与实例正交的数据子硬盘,如图 2 所示。
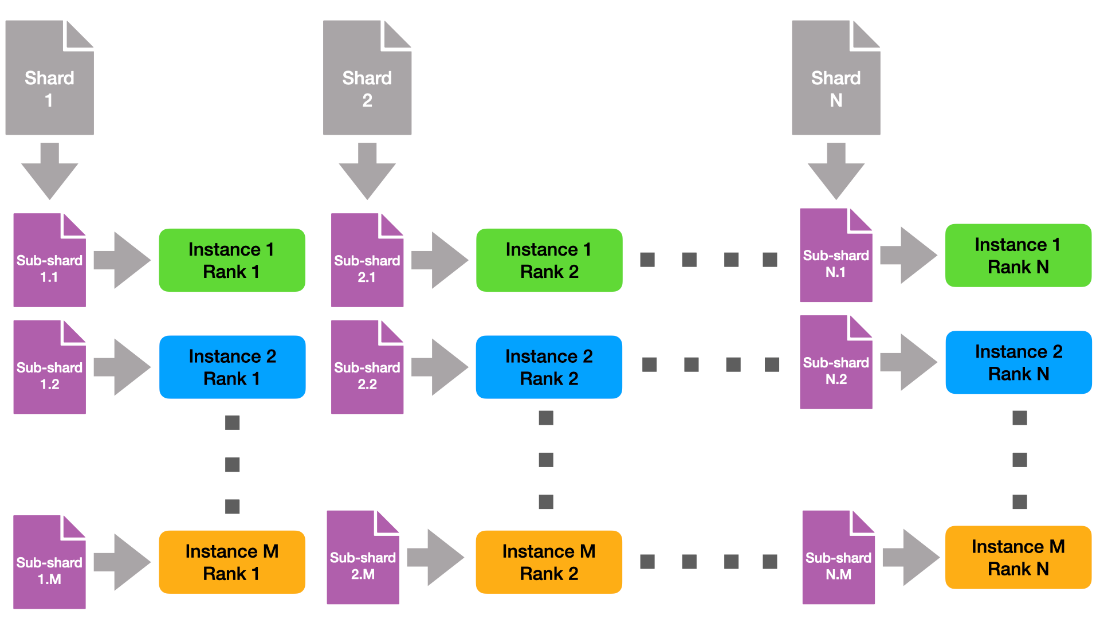
这样,每个文件从全局文件系统只读一次。最后,每个实例都需要接收所有数据。为此,我们创建了与实例内通讯器正交的新 MPI 通讯器,也就是说,我们将具有相同列组 id 的所有实例列组组合到相同的实例间通讯器中。然后,我们可以使用 MPI allgather 将各个子硬盘组合成原始碎片的 M 个副本。
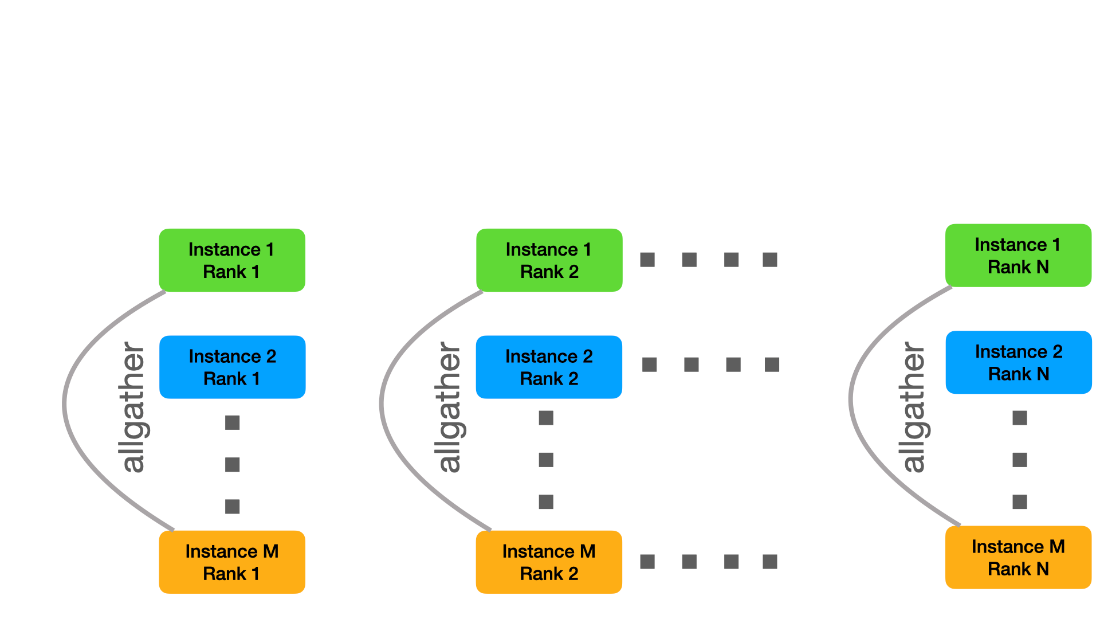
我们不按顺序执行这些步骤,而是使用批处理来创建一个管道,该管道与子硬盘的数据读取和分发重叠。为了提高读写性能,我们进一步实现了一个小型辅助工具,它使用 O _ DIRECT 来提高 I / O 带宽。
优化使 DeepCAM 基准测试的端到端加速比超过 2 倍。这在提交文件 repository 中提供。
损失函数的混合编程
使用命令式编程可以灵活地定义和运行模型,这样定义一个机器学习模型就像写一个python程序。与此相对的是符号式编程,它会先定义计算过程,然后再执行。这种编程方法允许执行引擎进行各种优化,但丢失了命令式方法的灵活性。
MXNet 框架采用了合并这两种方法的混合式编程。命令式定义的计算可以被编译成符号式,并在可能时进行优化。CosmoFlow 将模型混合式编程进行了扩展,把损失函数也包含进来。
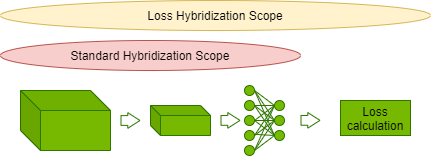
这允许将损耗计算中的元素操作与 CosmoFlow 模型的缩放激活输出进行融合,从而减少总体迭代延迟。优化使 CosmoFlow 的端到端性能提高了近 5% 。
节间均采用夏普处理,降低了集体成本
SHARP 允许将集合操作从 CPU 卸载到节间网络结构中的交换机。这有效地将 allreduce 操作的 InfiniBand 网络的节间带宽增加了一倍。这种优化可使 MLPerf HPC 基准测试的性能提高高达 5% ,特别是在强扩展场景中。
继续使用 MLPerf HPC
科学家们正在加速取得突破,部分原因是人工智能和高性能计算相结合,能够比传统方法更快、更准确地提供洞察力。
MLPerf HPC v1 . 0 反映了超级计算行业对客观、同行评审的方法的需求,以测量和比较与 HPC 相关用例的 AI 培训性能。在这一轮中, NVIDIA 计算平台通过损坏所有三个性能基准来证明清晰的领导,同时也证明了两个吞吐量测量的最高效率。
NVIDIA 还与世界各地的几个超级计算中心合作,向 NVIDIA GPU 提交了他们的意见。其中 Jülich Supercomputing Centre 是欧洲提交速度最快的。
阅读更多关于 2021 Gordon Bell finalists 的故事,以及关于 HPC 和 AI 如何使新型科学成为可能的讨论。
从 NVIDIA 了解有关 MLPerf benchmarks and results 的更多信息。
由 NVIDIA A100 提供动力的 Juwels 推进器的特色图片,图片由“ Forschungszentrum J ü lich / Sascha Kreklau ”提供
免责声明:
MLPerf ™ v1 . 0 HPC 关闭强和弱缩放 – 从 https://mlcommons.org/en/training-hpc-10 2021 年 11 月 16 日.
这个 MLPerf 。 名称和徽标是的商标 MLCommons 美国和其他国家的协会。版权所有。严禁未经授权使用。看见 www.mlcommons.org 更多 information.




