在高频交易的世界里,成千上万的市场参与者每天都在互动。据该报报道,事实上,高频交易占美国股票交易量的一半以上高频交易同步金融市场价格。
做市商是卖方的主要参与者,为市场提供流动性。投机者站在买方一边,进行实验和研究,希望从中获利。最终用户是向零售经纪人咨询建议和交易的散户投资者。总体而言,金融公司有兴趣评估金融机器学习( ML )算法,以发现哪些算法最有利可图。
研究人员最近发表了许多版本的这种类型的算法。我们试图利用高频数据和随机森林( RF )模型的可解释性,并选择了本文中提出的 RF 方法研究短期价格预测的限价订单簿特征:一种机器学习方法.
我们的研究发现,使用 GPU 的硬件加速减少了金融 ML 研究人员获得预测结果所需的时间。由于大部分运行时间都可以用于分类器训练,因此人们当然对更有效的训练方法感兴趣。
本文介绍了我们的研究,包括生成的数据集,使用限价订单簿( LOB )数据进行价格预测,以及 ML 训练的推荐步骤。我们解释了所研究的 GPU 配置如何显著加快 ML 训练时间,从而实现更高效和更广泛的模型开发
数据集
本研究使用显示实时股价的时间序列数据集来更好地理解 LOB 结构和方向预测。市场数据公司提供Intrinio,本研究的数据集包含纽约证券交易所和纳斯达克股票代码的实际市场价格样本,以 1 秒为基础,来自道琼斯 30 指数股票。
1 秒的报价被用作 ABIDES (基于代理的交互式离散事件模拟)的输入,以生成看起来像市场 LOB 的 LOB 数据。每条记录上的时间戳都在第二个标记处;例如: 2019 年 1 月 2 日的 2019-01-02T14 : 09 : 18Z ,即 2019 年的第一个交易日
输入到 ABIDES 的 CSV 文件由这一列作为第一列,后面是 30 列 DOW 30 的美元价格(到两位数)。本文将 AAPL 股票行情作为一个测试案例。
使用 ABIDES 生成合成数据
ABIDES 是一种模拟金融市场运作的方法。在最近的论文中进行了解释,ABIDES: Towards High-Fidelity Multi-Agent Market Simulation,由佐治亚理工学院、佐治亚大学和摩根大通银行的研究人员撰写
ABIDES 模拟了许多通过交易所代理买卖资产的个人交易代理。模拟中的每一笔交易和其他事件都会被记录下来,并与执行交易的代理人联系在一起。这使市场研究人员能够详细分析不同的代理人策略和事件如何影响模拟市场。重要的是,给定交换的 LOB 可以在模拟之后重建
ABIDES 模拟中的一些代理基于时间序列来评估资产,该时间序列表示代理在某个频率下观察到的资产的真实价值,并添加一些噪声。这个时间序列被称为基本价值股票的价格。为了在宏观尺度上模拟一个更现实的市场,我们使用真实的历史数据作为基本值。
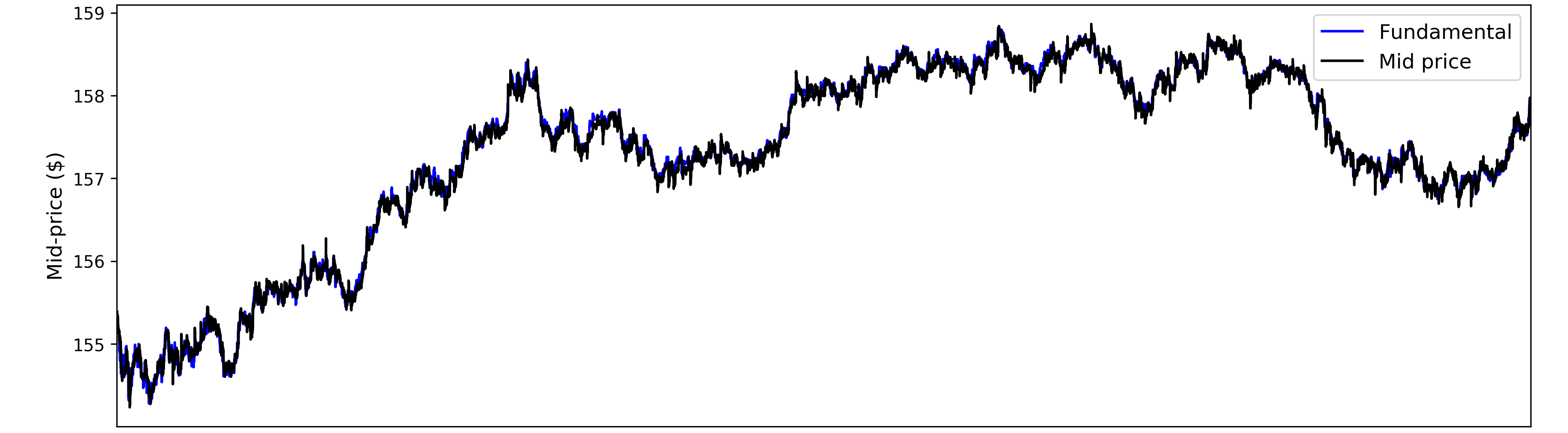
为了创建合理的 LOB 数据来训练我们的 RF 模型,我们使用 Intrinio 提供的 1 秒报价作为 ABIDES 模拟的历史基本值。图 1 将输出 LOB 数据的中间价与用作 AAPL 历史基本面的 1 秒报价进行了比较。
LOB 作为短期价格变动的预测指标
在贸易交易的投标方,买方希望尽可能少地支付购买给定证券的费用。在要求方,卖方希望以尽可能高的价格出售证券。限价单是在买卖双方设定这些限制的一种方式。
给定证券的 LOB 是一个订单大小列表, x 轴为证券价格, y 轴为该价格下买卖双方的总交易量。例如,买家愿意以每股 580 美元的价格购买 100 股谷歌证券,因此出售者必须有足够的股份来完成这 100 股。请参见图 2 以获取 LOB 示例。
LOB 分为出价部分(图 2 中红线左侧)和要价部分(图 2 红线右侧),前者的价格低于中间市场,后者的价格较高。
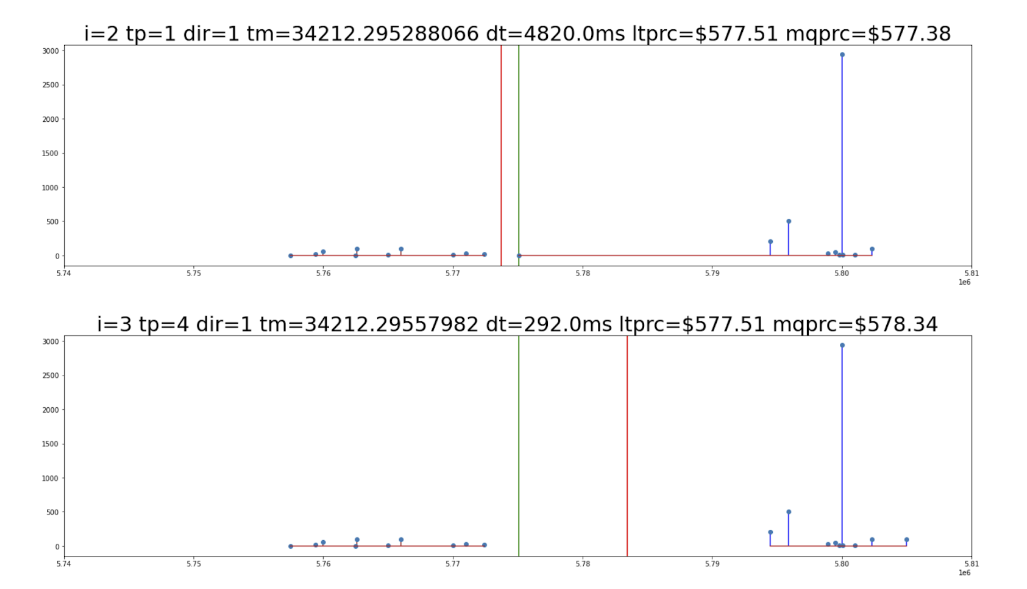
简单地说,买方希望在市场上支付更低的价格,而卖方希望获得更高的价格。时间点在小数点后有九位数,这反映了现代证券交易所的纳秒精度
两个框架中的第一个框架(位于图 2 顶部)的一个显著特征是,从高点(高于标记为 5 . 80 的点)可以看出,以 580 美元的价格出售的需求量很大。观察这是如何主导 LOB 的,预示着中间报价向右移动,美元价值更高。
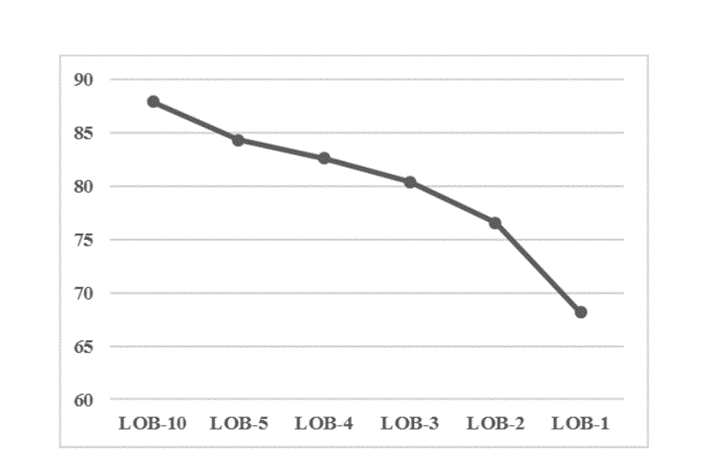
图 3 显示,当向分类器提供更多的 LOB 深度时,预测价格走势即时方向的准确性会提高。这是直观的,因为分类器在训练过程中有更多关于市场两侧的可用信息(出价水平和要价水平)。
图片来源:费萨尔·库雷希
使用 RAPIDS 加速随机森林训练
我们训练了一个随机森林模型,以 LOB 数据作为输入来预测短期价格走势。我们训练了一个分类器来预测给定的股价是向上、向下还是持平
具体来说,目标是预测未来 20 个中间价格( m下一个) 将小于或大于之前 20 个中间价格的平均值( m上一个) 以一定的幅度。我们将这一差额定义为 0 . 5 美分,这是我们数据集中任何两个 LOB 帧之间中间价格的最小非零差异。
标签为 2 表示价格上涨( m下一个–米上一个> 0 . 5 美分),标签为 1 表示中性价格变动,标签为 0 表示向下价格变动( m下一个–米上一个< -0 . 5 美分)
以下实验是在一个NVIDIA A100用于 RAPIDS cuDF 和 RAPIDS cuML 的 80 GB SXM ,以及用于 scikit learn 和 pandas 的两个 AMD EPYC 7742 64 核处理器。使用 RAPIDS cuDF 库和 pandas 计算中间价、平均值和标签
图 4 显示了运行时的比较。平均预处理时间是根据每种配置的 10 次运行和 10 次预热计算得出的。这是在 ML 训练运行之前的一个标记步骤,如图 5 所示。
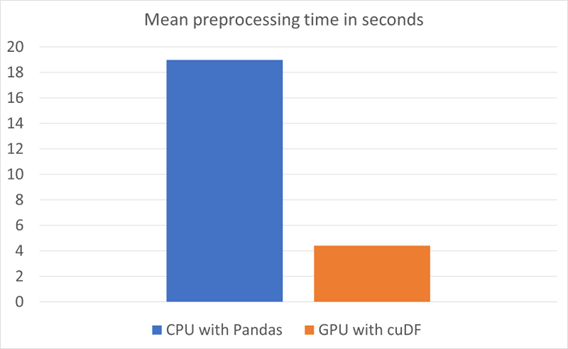
我们使用 scikit learn 和 RAPIDS cuML 训练了一个由 100 棵树组成的随机森林分类器,并比较了两者的训练时间。 RAPIDS cuML 是 scikit learn 的免费替代品,它使许多流行的 ML 算法能够在 GPU 上加速
图 5 显示了一个 NVIDIA A100 80 GB 与 RAPIDS cuML 以及两个 AMD EPYC 7742 64 核处理器与 scikit learn 上训练工作负载的运行时间的比较。 CPU 上的训练是多线程的,有 128 个线程,使用 scikit learnn_jobs参数
五次热身的平均时间是 50 分以上,而 scikit 的学习时间是五次热身平均 10 分以上。使用 GPU 进行训练的速度大约快 10 倍。这些结果与 2022 年 GPU 研究结果一致,详见Accelerating Machine Learning Training Time for Limit Order Book Prediction.
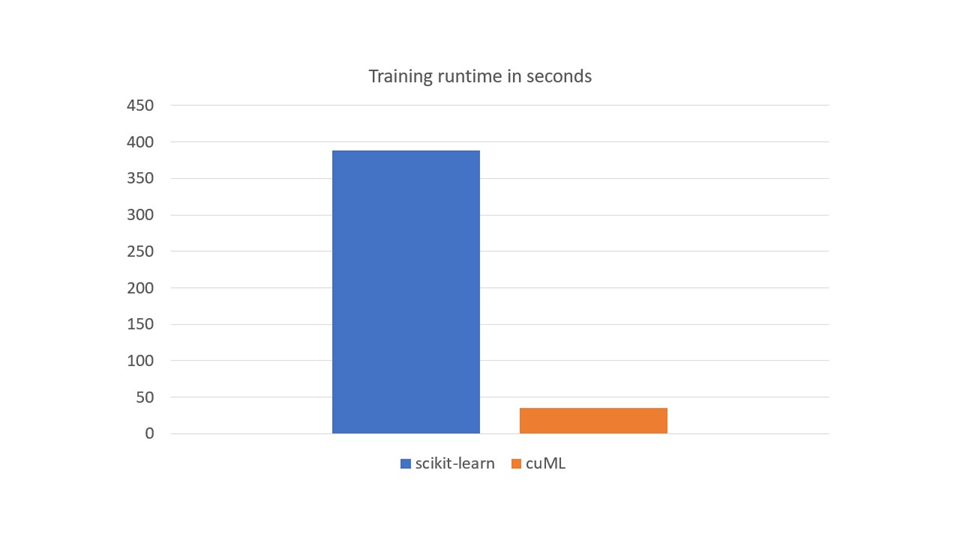
GPU 上的培训可为这一工作量提供 10 倍以上的加速。 ML 分类器开发的迭代性质使其时间密集,特别是考虑到金融市场中使用的大量时间序列数据。简而言之, GPU 是 ML 算法研究的游戏规则改变者。
金融数据集日益增长的计算需求
虽然前面的例子使用了一个股票行情器,但这些高频交易和限价订单的用例需要多个 AI 系统运行相当于多个的算法NVIDIA DGX SuperPODs通常,专门研究此类用例的组织需要多个资产类和跟踪器
因此,这种算法的分析和应用可以很容易地并行化,案例可以扩展到需要加速时间和大量计算的多个人工智能系统。例如,定量金融、机器学习(如 RAPIDS cuML )和深度学习应用(如 LOB 数据集之上的神经网络)。
为了在开发金融 ML 算法时加快培训速度,您可以使用 RAPIDS 库套件来利用 GPU 加速:
- RAPIDS cuDF 取代 pandas Python 库
- RAPIDS cuML 取代 scikit 学习 Python 库
下载并安装 RAPIDS开始为您的数据科学工作负载启用 GPU 。记得事先安装 NVIDIA 驱动程序和 CUDA 工具包。