Transformer 是当今最具影响力的人工智能模型架构之一,正在塑造未来人工智能研发的方向。Transformer 最初被发明为自然语言处理( NLP )的工具,现在几乎被用于每一项人工智能任务,包括计算机视觉、自动语音识别、分子结构分类和金融数据处理。
在韩国, Kakao Brain 开发了一种基于 transformer 架构的高精度大型语言模型( LLM ) KoGPT 。它在一个大型韩国数据集上进行了训练,并使用 NVIDIA FasterTransformer 成功地对其进行了优化。
在这篇文章中,我们将介绍 NVIDIA 和 Kakao Brain 如何使用 FasterTransformer 优化 KoGPT 。
FasterTransformer 简介
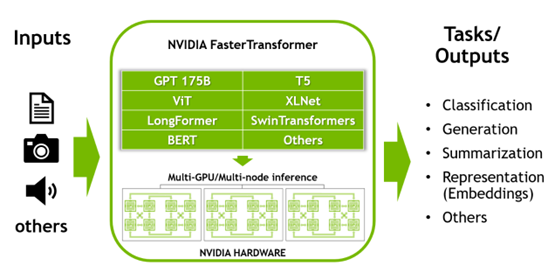
Transformer 层是目前深度学习领域应用最广泛的深度学习架构。它起源于 NLP ,目前正在将其应用范围从语言扩展到视觉、语音和生成人工智能。
NLP 中最流行的人工智能模型之一是 GPT 模型家族。 GPT 是由 OpenAI 开发的 LLM ,它从 transformer 模型架构中堆叠多层所谓的解码器块。例如, GPT-3 是一种具有数千亿个参数的 LLM ,可以像一本巨大的百科全书一样聚集大量信息。
然而,培训这些 LLM 带来了一些挑战:
- 这些 LLM 占用大量内存,可能超过单个 GPU 的容量。
- 由于需要大量的计算工作,训练和推理可能需要相当长的时间。因此,您必须优化堆栈的每一个级别:算法、软件和硬件。
这个NVIDIA NeMo framework和 FasterTransformer 使得能够对具有数千亿个参数的 LLM 进行更快的训练和推理。
FasterTransformer 中的优化
FasterTransformer 是一个库,它使用前面描述的模型并行化(张量并行和流水线并行)方法为大型 transformer 模型实现推理加速引擎。与以前可用的深度学习框架相比, FasterTransformer 的开发旨在最大限度地减少延迟并最大限度地提高吞吐量。
FasterTransformer 提供了 transformer 模型的优化解码器和编码器块。它是用 C ++/ CUDA 编写的,具有 TensorFlow 、 PyTorch 和Triton Backend框架。它附带了演示其主要功能的示例代码。
FasterTransformer 是开源的。它已经支持许多型号,如 GPT-3 、 GPT-J 、 GPT-NeoX 、 BERT 、 ViT 、 Swin transformer 、 Longformer 、 T5 、 XLNet 和 BLOOM 。不断增加对新机型的支持。它还支持即时学习技术。有关详细信息,请参阅latest support matrix.
如前所述, FasterTransformer 实现了比其他深度学习框架更快的推理管道,具有更低的延迟和更高的输出。以下是 FasterTransformer 中使用的一些优化技术:
- 层融合:该技术将多个层合并为一个层,通过减少数据传输和增加计算强度来加速推理计算。这种加速的例子是偏置加层归一化、偏置加激活、偏置加 softmax 以及注意力层的三个转置矩阵的融合。
- 多头注意力加速:多头注意力计算序列中标记之间的关系,需要大量的计算和内存拷贝。 FasterTransformer 使用融合内核维护数据缓存( K / V 缓存)以减少计算并最大限度地减少内存传输的大小。
- GEMM 内核自动调谐:矩阵乘法是基于 transformer 的模型中最常见和最繁重的运算。 FasterTransformer 使用 cuBLAS 和 CUTRASS 库提供的功能来执行此操作。矩阵乘法运算可以在硬件级别上具有不同的低级别实现。 FasterTransformer 对模型的参数(附着层、大小、附着头数量、隐藏层大小等)和输入数据进行实时基准测试。它选择最合适的功能和参数。
- 精度较低:FasterTransformer 支持较低精度的数据类型,如 FP16 、 BF16 和 INT8 。 Tensor Core 在最近的 NVIDIA GPU (在 NVIDIA -Volta 架构之后)上可以加速对这些数据类型的操作。特别是, NVIDIA Hopper GPU 可以运行专用硬件,如 transformer 引擎。
KoGPT 简介

Kakao Brain 的 KoGPT 从词汇和上下文角度理解韩语,并根据用户意图生成句子。使用 KoGPT ,用户可以执行与韩语相关的各种任务,例如确定给定句子的情感、预测摘要或结论、回答问题或生成下一个句子。它还可以处理各种领域的高级语言任务,如机器阅读、机器翻译、写作和情感分析。
KoGPT 与 FasterTransformer 的性能
Kakao Brain 希望运行 KoGPT ,这是一种使用 HuggingFace 实现的基于 GPT-3 的语言模型服务。训练时速度不是问题,因为表现更重要。但在发球方面,速度成了一个主要问题。推理速度越慢,必须为该服务专用的服务器就越多。它呈指数级增长,这导致了更高的运营成本。
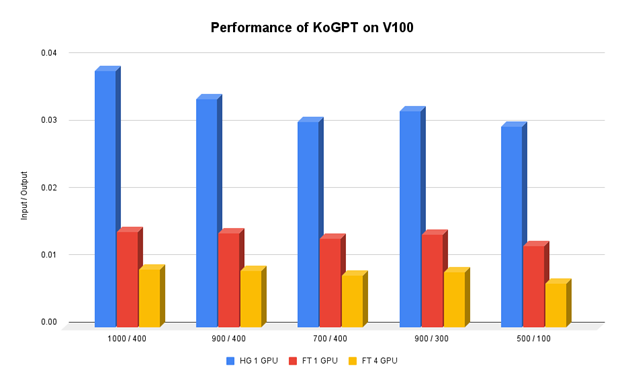
Kakao Brain 的团队试图找到并应用各种方法来优化 GPT-3 的推理速度,但未能取得太大改进。直到采用 NVIDIA FasterTransformer 后,该团队才发现推理速度有了显著提高。推理速度因输入和输出令牌的数量而异,但平均而言,该团队在一台 NVIDIA V100 GPU 上将推理速度提高了 400% 。
FasterTransformer 还支持张量和流水线并行。当使用四个 V100 GPU 时,该团队的推理速度比基线提高了 1100% 以上。
总结
NVIDIA FasterTransformer 使 KoGPT 很容易克服团队在推出服务之前必须面对的技术挑战。 Kakao Brain ML 优化团队通过在同一硬件上提供更多请求,将总拥有成本( TCO )提高了 15% 以上。
有关 Kakao Brain 的韩国 LLM 、 KoGPT 和韩国人工智能聊天机器人 KoChat GPT 的更多信息,请参阅Kakao网站