CUDA 11 . 2 的特点是在 GPU 加速应用程序中为设备代码提供强大的链路时间优化( LTO )功能。 Device LTO 将设备代码优化的性能优势(只有在 nvcc 整个程序编译模式下才可能)带到了 CUDA 5 . 0 中引入的 nvcc 单独编译模式。
单独编译模式允许 CUDA 设备内核代码跨多个源文件,而在整个程序编译模式下,程序中的所有 CUDA 设备内核代码都必须位于单个源文件中。独立编译模式将源代码模块化引入设备内核代码,因此是提高开发人员生产率的重要步骤。独立的编译模式使开发人员能够更好地设计和组织设备内核代码,并使 GPU 加速许多现有的应用程序,而无需进行大量的代码重构工作,即可将所有设备内核代码移动到单个源文件中。它还提高了大型并行应用程序开发的开发人员的生产效率,只需要重新编译带有增量更改的设备源文件。
CUDA 编译器优化的范围通常限于正在编译的每个源文件。在单独的编译模式下,编译时优化的范围可能会受到限制,因为编译器无法看到源文件之外引用的任何设备代码,因为编译器无法利用跨越文件边界的优化机会。
相比之下,在整个程序编译模式下,程序中存在的所有设备内核代码都位于同一源文件中,消除了任何外部依赖关系,并允许编译器执行在单独编译模式下不可能执行的优化。因此,在整个程序编译模式下编译的程序通常比在单独编译模式下编译的程序性能更好。
使用 CUDA 11 . 0 中预览的设备链接时间优化( LTO ),可以获得单独编译的源代码模块化以及设备代码整个程序编译的运行时性能。虽然编译器在优化单独编译的 CUDA 源文件时可能无法进行全局优化的代码转换,但链接器更适合这样做。
与编译器相比,链接器具有正在构建的可执行文件的整个程序视图,包括来自多个源文件和库的源代码和符号。可执行文件的整个程序视图使链接器能够选择最适合单独编译的程序的性能优化。此设备链接时间优化由链接器执行,是 CUDA 11 . 2 中 nvlink 实用程序的一个功能。具有多个源文件和库的应用程序现在可以通过 GPU 进行加速,而不会影响单独编译模式下的性能。
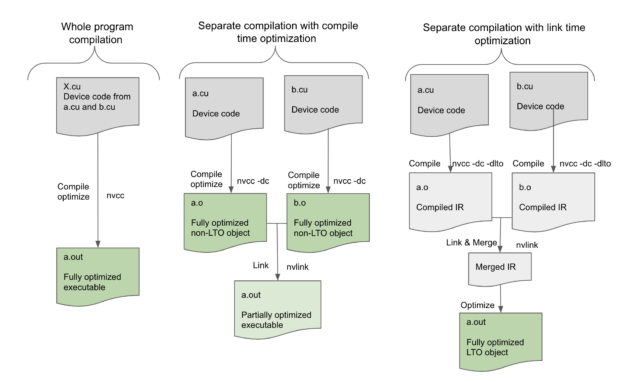
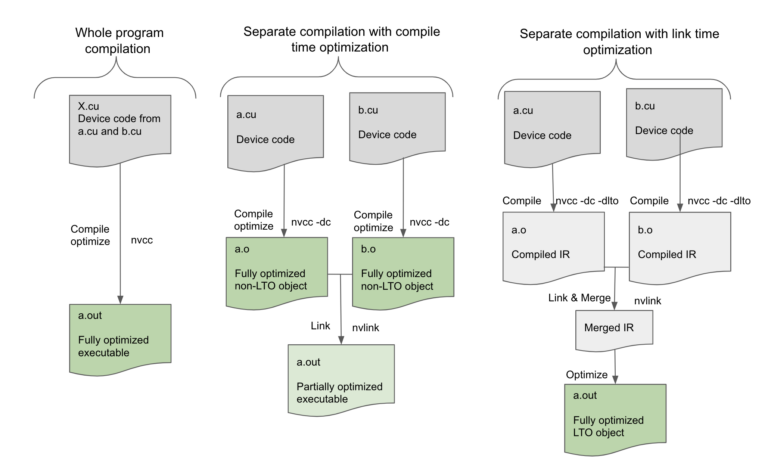
图 1 ,在 nvcc 全程序编译模式下,要在单个源文件 X . cu 中编译的设备程序,没有任何未解析的外部设备函数或变量引用,可以在编译时由编译器完全优化。然而,在单独的编译模式下,编译器只能优化正在编译的单个源文件中的设备代码,而最终的可执行文件没有尽可能优化,因为编译器无法执行跨源文件的更多优化。设备链接时间优化通过将优化推迟到链接步骤来弥补这一差距。
在设备 LTO 模式下,我们为每个翻译单元存储代码的高级中间形式,然后在链接时合并所有这些中间形式以创建所有设备代码的高级表示。这使链接器能够执行高级优化,例如跨文件边界内联,这不仅消除了调用约定的开销,还进一步支持对内联代码块本身进行其他优化。链接器还可以利用已完成的偏移量。例如,共享内存分配是最终确定的,并且数据偏移量仅在链路时间已知,因此设备链路时间优化现在可以使诸如设备代码的恒定传播或折叠之类的低级优化成为可能。即使函数没有内联,链接器仍然可以看到调用的两面,以优化调用约定。因此,可以通过设备链路时间优化来提高为单独编译的程序生成的代码的质量,并且其性能与以整个程序模式编译的程序一样。
为了了解单独编译的局限性以及设备 LTO 可能带来的性能提升,让我们看一个 MonteCarlo 基准测试中的示例
I 在下面的示例代码中, MC_Location:: get_domain 不是在另一个文件中定义的标准编译模式中内联的,而是
使用 CUDA 11 . 2 中的设备链路优化内联
__device__ void MCT_Reflect_Particle(MonteCarlo *monteCarlo,
MC_Particle &particle){
MC_Location location = particle.Get_Location();
const MC_Domain &domain = location.get_domain(monteCarlo);
...
...
/* uses domain */
}
函数 get \ u domain 是另一个类的一部分,因此在另一个文件中定义它是有意义的。但是在单独的编译模式下,编译器在调用 get \ u domain ()时将不知道它做什么,甚至不知道它存在于何处,因此编译器无法内联该函数,必须随参数一起发出调用并返回处理,同时也节省空间的事情,如回邮地址后,呼吁。这又使得它无法潜在地优化使用域值的后续语句。在设备 LTO 模式下, get \ u domain ()可以完全内联,编译器可以执行更多优化,从而消除调用约定的代码,并启用基于域值的优化。
简而言之,设备 LTO 将所有性能优化都引入到单独的编译模式中,而以前只有在整个程序编译模式中才可用。
使用设备 LTO
要使用设备 LTO ,请将选项 -dlto 添加到编译和链接命令中,如下所示。从这两个步骤中跳过 -dlto 选项会影响结果。
使用 -dlto 选项编译 CUDA 源文件:
nvcc -dc -dlto *.cu
使用 -dlto 选项链接 CUDA 对象文件:
nvcc -dlto *.o
在编译时使用 -dlto 选项指示编译器将正在编译的设备代码的高级中间表示( NVVM-IR )存储到 fatbinary 中。在链接时使用 -dlto 选项将指示链接器从所有链接对象检索 NVVM IR ,并将它们合并到一个 IR 中并执行优化在生成的 IR 上生成代码。设备 LTO 与任何支持的 SM 架构目标一起工作。
对现有库使用设备 LTO
设备 LTO 只有在编译和链接步骤都使用 -dlto 时才能生效。如果 -dlto 在编译时使用,而不是在链接时使用,则在链接时每个对象都被单独编译到 SASS ,然后作为正常链接,没有任何优化机会。如果 -dlto 在链接时使用,而不是在编译时使用,然后链接器找不到要执行 LTO 的中间表示,并跳过直接链接对象的优化步骤。
如果包含设备代码的所有对象都是用 -dlto 构建的,那么 Device LTO 工作得最好。但是,即使只有一些对象使用 -dlto ,它仍然可以使用,如图 2 所示。
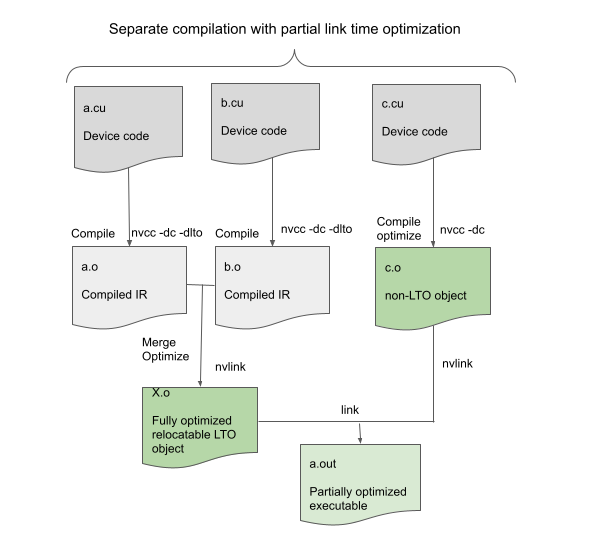
在这种情况下,在链接时,使用 -dlto 构建的对象链接在一起形成一个可重定位对象,然后与其他非 LTO 对象链接。这不会提供最佳性能,但仍然可以通过在 LTO 对象内进行优化来提高性能。此功能允许使用 -dlto ,即使外部库不是用 -dlto 构建的;这只是意味着库代码不能从设备 LTO 中获益。
每体系结构的细粒度设备链路优化支持
全局 -dlto 选项适用于编译单个目标体系结构。
使用 -gencode 为多个体系结构编译时,请确切指定要存储到 fat 二进制文件中的中间产物。例如,要在可执行文件中存储 Volta SASS 和 Ampere PTX ,您当前可以使用以下选项进行编译:
nvcc -gencode arch=compute_70,code=sm_70
-gencode arch=compute_80,code=compute_80
使用一个新的代码目标 lto_70 ,您可以获得细粒度的控制,以指示哪个目标体系结构应该存储 LTO 中介体,而不是 SASS 或 PTX 。例如,要存储 Volta LTO 和 Ampere PTX ,可以使用以下代码示例进行编译:
nvcc -gencode arch=compute_70,code=lto_70 -gencode arch=compute_80,code=compute_80
绩效结果
设备 LTO 会对性能产生什么样的影响?
gpu 对内存流量和寄存器压力非常敏感。因此,设备优化通常比相应的主机优化影响更大。正如预期的那样,我们观察到许多应用受益于设备 LTO 。通常,通过设备 LTO 的加速比取决于 CUDA 应用特性。
图 3 和图 4 显示了一个内部基准应用程序和另一个实际应用程序的运行时性能和构建时间的比较图,这两个应用程序都采用三种编译模式:
- 全程序编译
- 不带设备 LTO 的单独编译
- 使用设备 LTO 模式单独编译
我们测试的客户应用程序有一个占运行时 80% 以上的主计算内核,它调用了分布在不同翻译单元或源文件中的数百个独立设备函数。函数的手动内联是有效的,但如果您希望使用单独的编译来维护传统的开发工作流和库边界,则会很麻烦。在这些情况下,使用设备 LTO 来实现潜在的性能优势而不需要额外的开发工作是非常有吸引力的。
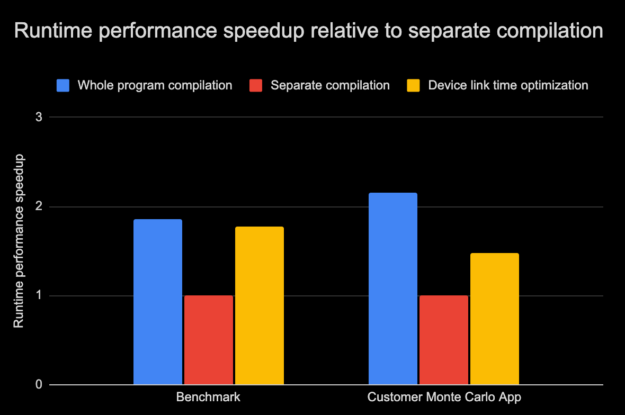
如图 3 所示,带有设备 LTO 的基准测试和客户应用程序的运行时性能接近于整个程序编译模式,克服了单独编译模式带来的限制。请记住,性能的提高在很大程度上取决于应用程序本身的构建方式。正如我们所观察到的,在某些情况下,收益微乎其微。使用另一个 CUDA 应用程序套件,设备 LTO 的运行时性能平均提高了 25% 左右。
在这篇文章的后面,我们将介绍更多关于设备 LTO 不是特别有用的场景。
除了 GPU 性能之外,设备 LTO 还有另一个方面,那就是构建时间。使用设备 LTO 的总构建时间在很大程度上取决于应用程序大小和其他系统因素。在图 4 中,内部基准构建时间的相对差异与前面三种不同编译模式的客户应用程序进行了比较。内部基准由大约 12000 行代码组成,而客户应用程序有上万行代码。
有些情况下,由于编译和优化这些程序所需的过程较少,因此整个程序模式的编译速度可能更快。此外,在全程序模式下,较小的程序有时可能编译得更快,因为它有较少的编译命令,因此对宿主编译器的调用也较少。但是在全程序模式下的大型程序会带来更高的优化成本和内存使用。在这种情况下,使用单独的编译模式进行编译会更快。对于图 4 中的内部基准可以观察到这一点,其中整个程序模式的编译时间快了 17% ,而对于客户应用程序,整个程序模式的编译速度慢了 25% 。
有限的优化范围和较小的翻译单元使单独编译模式下的编译速度更快。当增量更改被隔离到几个源文件时,单独的编译模式还减少了总体的增量构建时间。当启用设备链接时间优化时,编译器优化阶段将被取消,从而显著减少编译时间,从而进一步加快单独编译模式的编译速度。但是,同时,由于设备代码优化阶段推迟到链接器,并且由于链接器可以在单独编译模式下执行更多优化,因此单独编译的程序的链接时间可能随着设备链接时间优化而更高。在图 4 中,我们可以观察到设备 LTO 构建时间与基准相比只慢了 7% ,但是与客户应用程序相比,构建时间慢了近 50% 。
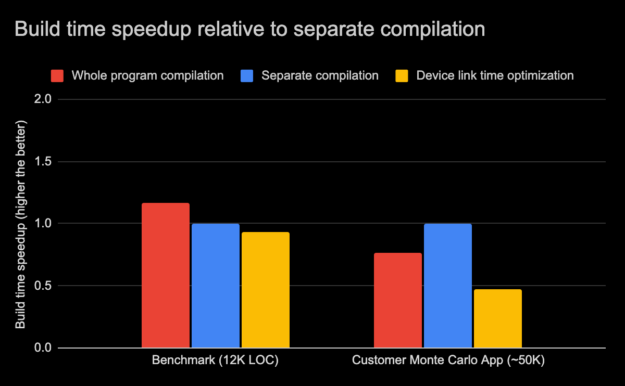
在 11 . 2 中,我们还引入了新的 nvcc -threads 选项,它在针对多个体系结构时支持并行编译。这有助于减少构建时间。一般来说,这些编译模式的总(编译和链接)构建时间可能会因一组不同的因素而有所不同。尽管如此,由于使用设备 LTO 可以显著缩短编译时间,我们希望启用设备链接时间优化的单独编译模式的总体构建在大多数典型场景中应该是可比的。
设备 LTO 的限制
设备 LTO 在跨文件对象内联设备功能时特别强大。但是,在某些应用程序中,设备代码可能都驻留在源文件中,在这种情况下,设备 LTO 没有太大的区别。
来自函数指针的间接调用(如回调)不会从 LTO 中获得太多好处,因为这些间接调用不能内联。
请注意,设备 LTO 执行激进的代码优化,因此它与使用 -G NVCC 命令行选项来启用设备代码的符号调试支持不兼容。
对于 CUDA 11 . 2 ,设备 LTO 只能脱机编译。设备 LTO 中间窗体尚不支持 JIT LTO 。
像 -maxrregcount 或 -use_fast_math 这样的文件作用域命令与设备 LTO 不兼容,因为 LTO 优化跨越了文件边界。如果所有的文件都是用相同的选项编译的,那么一切都很好,但是如果它们不同,那么设备 LTO 会在链接时抱怨。通过在链接时指定 -maxrregcount 或 -use_fast_math ,可以覆盖设备 LTO 的这些编译属性,然后该值将用于所有 LTO 对象。
尽管使用设备 LTO 将编译时优化所花的大部分时间转移到了链接时,但总体构建时间通常在 LTO 构建和非 LTO 构建之间是相当的,因为编译时间显著缩短。但是,它增加了链接时所需的内存量。我们认为,设备 LTO 的好处应该抵消最常见情况下的限制。
试用设备 LTO
如果您希望在不影响性能或设备源代码模块化的情况下,以单独的编译模式构建 GPU 加速的应用程序,那么设备 LTO 就适合您了!
使用以单独编译模式编译的设备 LTO 程序可以利用跨文件边界的代码优化的性能优势,从而有助于缩小相对于整个程序编译模式的性能差距。
为了评估和利用设备 LTO 对 CUDA 应用程序的好处, 立即下载 CUDA 11 . 2 工具包 并进行试用。另外,请告诉我们您的想法。我们一直在寻找改进 CUDA 应用程序开发和运行时性能调优体验的方法。