
这是 NVIDIA 研究人员如何改进和加速扩散模型采样的系列文章的一部分,扩散模型是一种新的、强大的生成模型。 Part 1 介绍了扩散模型作为深层生成模型的一个强大类,并研究了它们在解决生成性学习三重困境中的权衡。
虽然扩散模型同时满足 生成性学习三位一体 的第一和第二个要求,即高样本质量和多样性,但它们缺乏传统 GAN 的采样速度。在这篇文章中,我们回顾了 NVIDIA 最近开发的三种技术,它们克服了扩散模型中缓慢采样的挑战。
潜空间扩散模型
扩散模型的采样速度较慢的主要原因之一是,从简单的高斯噪声分布到具有挑战性的多模态数据分布的映射非常复杂。最近, NVIDIA 推出了 基于潜在分数的生成模型 ( LSGM ),这是一种新的框架,可以在潜在空间而不是直接在数据空间中训练扩散模型。
在 LSGM 中,我们利用变分自动编码器( VAE )框架将输入数据映射到一个潜在空间,并在那里应用扩散模型。然后,扩散模型的任务是对数据集潜在嵌入的分布进行建模,这在本质上比数据分布更简单。
新的数据合成是通过从简单的基分布中提取嵌入,然后迭代去噪,然后使用解码器将该嵌入转换为数据空间来实现的(图 1 )。
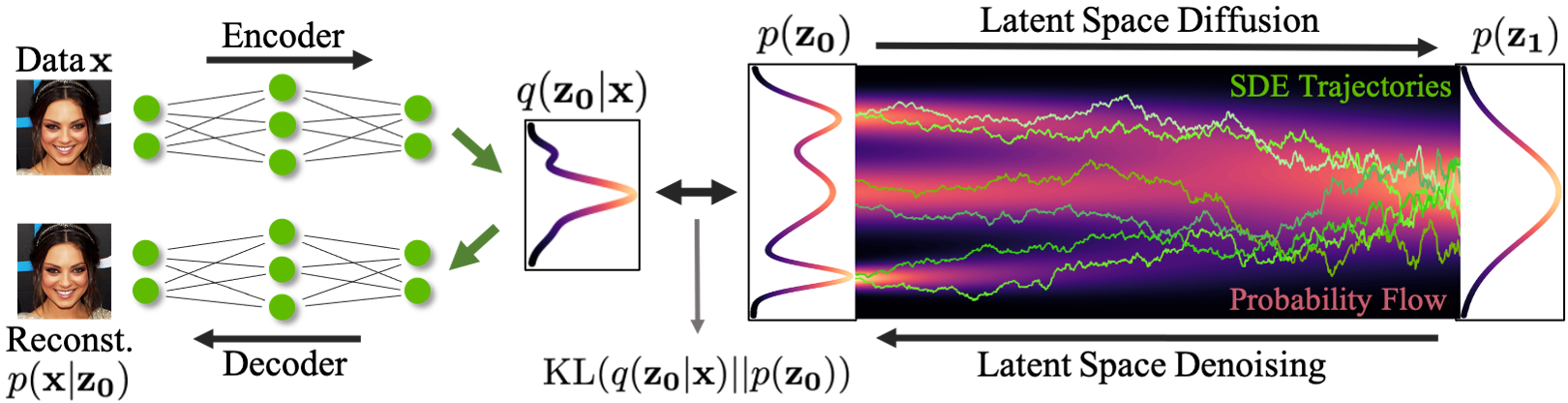
图 1 显示,在基于潜在分数的生成模型( LSGM )中:
- 数据
通过编码器
映射到潜在空间。
- 扩散过程应用于潜在空间
。
- 合成从碱基分布
开始。
- 它通过去噪
在潜在空间生成样本
。
- 使用解码器
将样本从潜在空间映射到数据空间。
LSGM 有几个关键优势:合成速度、表现力,以及定制的编码器和解码器。
合成速度
通过先用高斯先验对 VAE 进行预训练,可以使数据分布的潜在编码接近高斯先验分布,这也是扩散模型的基本分布。扩散模型只需对剩余的不匹配进行建模,从而形成一个简单得多的模型,从中采样变得更容易、更快。
可以相应地调整潜在空间。例如,我们可以使用分层潜变量,并仅在其中的一个子集上或以较小的分辨率应用扩散模型,从而进一步提高合成速度。
表现力
训练一个规则的扩散模型可以看作是直接在数据上训练一个神经网络。然而,之前的研究发现,用潜在变量增强神经微分方程以及其他类型的生成模型通常可以提高它们的表达能力。
我们期望通过将扩散模型与潜在变量框架相结合,获得类似的表现力收益。
定制编码器和解码器
在潜在空间中使用扩散模型时,可以使用精心设计的编码器和解码器在潜在空间和数据空间之间映射,进一步提高合成质量。因此, LSGM 方法可以自然地应用于非连续数据。
原则上, LSGM 可以通过使用编码器和解码器网络,轻松地对文本、图形和类似的离散或分类数据类型等数据进行建模,这些网络将这些数据转换为连续的潜在表示并返回。
直接对数据进行操作的常规扩散模型无法轻松对此类数据类型进行建模。标准扩散框架仅适用于连续数据,这些数据可以逐渐扰动并以有意义的方式生成。
后果
在实验上, LSGM 在 CIFAR-10 和 CelebA-HQ-256 这两个广泛使用的图像生成基准数据集上实现了最先进的 Fr é chet Inception 距离( FID ),这是量化视觉图像质量的标准度量。在这些数据集上,它优于先前的生成模型,包括 GANs 。
在 CelebA-HQ-256 上, LSGM 的合成速度比以前的扩散模型快两个数量级。在对 CelebA-HQ-256 数据建模时, LSGM 只需要 23 次神经网络调用,而之前在数据空间上训练的扩散模型通常依赖数百次或数千次网络调用。
临界阻尼朗之万扩散
扩散模型中的一个关键因素是固定前向扩散过程,以逐渐扰动数据。与数据本身一起,它唯一地决定了去噪模型学习的难度。因此,我们能否设计一种特别容易去噪的前向扩散,从而实现更快、更高质量的合成?
扩散模型中使用的扩散过程在统计学和物理学等领域得到了很好的研究,它们在各种抽样应用中都很重要。受这些领域的启发,我们最近提出了 临界阻尼朗之万扩散 ( CLD )。
在 CLD 中,必须扰动的数据与可被视为 velocities 的辅助变量耦合,这与物理学中的速度相似,因为它们基本上描述了数据向扩散模型的基本分布移动的速度。
就像一个落在山顶上的球,在相对直接的路径上迅速滚动到山谷中,积累一定的速度,这种受物理启发的技术有助于数据快速平稳地扩散。描述 CLD 的正向扩散 SDE 如下所示:

这里,


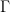


CLD 可以解释为两个不同术语的组合。首先是一个 Ornstein-Uhlenback 过程,这是一种特殊的噪声注入过程,作用于速度变量
其次,在哈密顿动力学中,数据和速度相互耦合,因此注入速度的噪声也会影响数据
图 2 显示了一个简单的一维玩具问题的数据和速度如何在 CLD 中扩散:
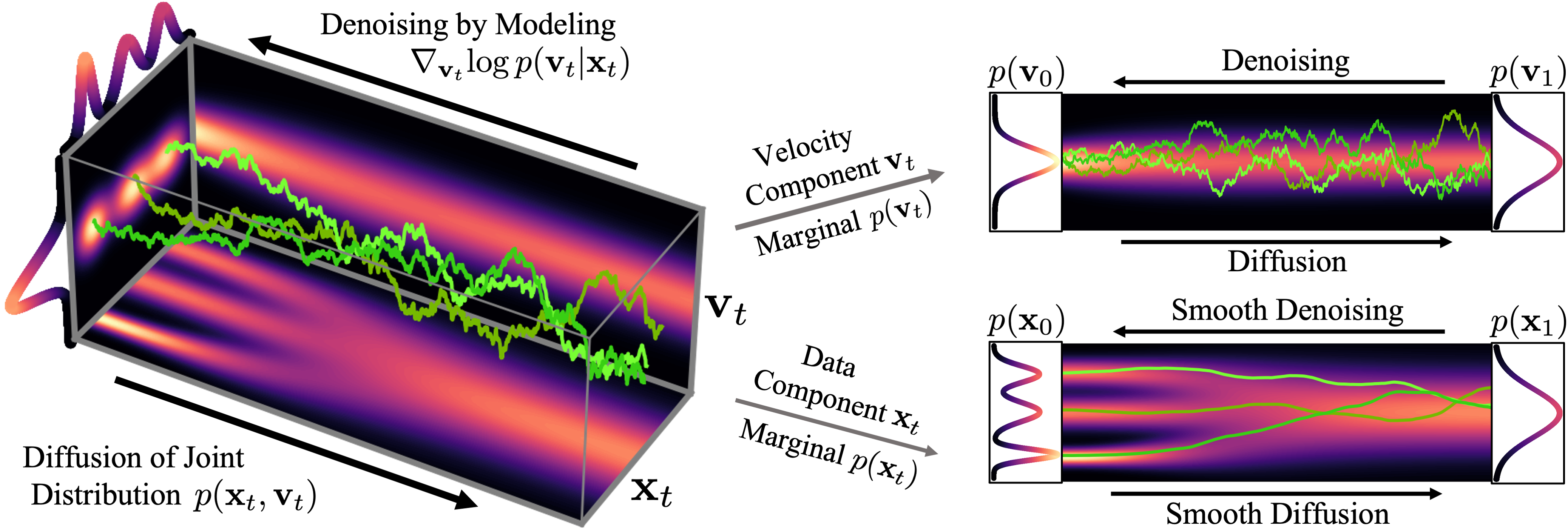
在扩散开始时,我们从简单的高斯分布中提取一个随机速度,然后在联合数据速度空间中进行完全扩散。当观察数据的演变(图中右下角)时,模型的扩散方式比之前的扩散方式要平滑得多。
直观地说,这也应该使去噪和反转生成过程更容易。我们只在扩散参数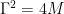
我们还可以可视化图像在正向扩散和生成期间如何在高维联合数据速度空间中演化:
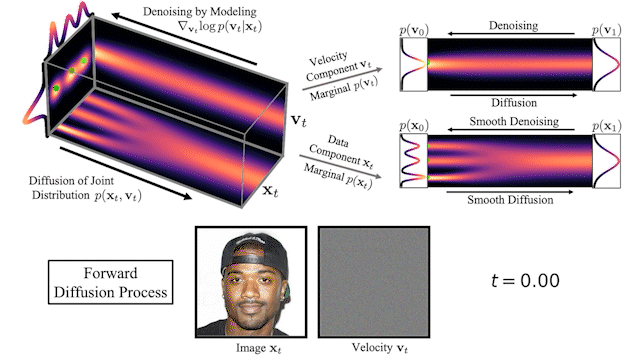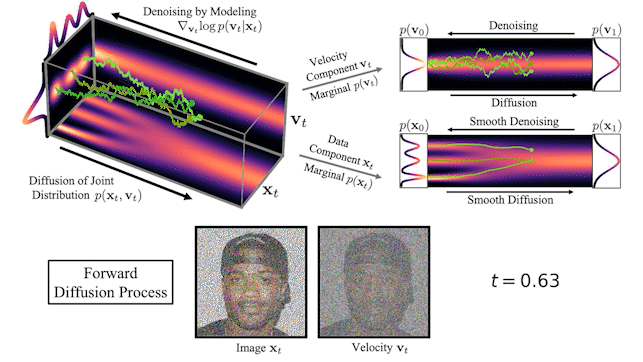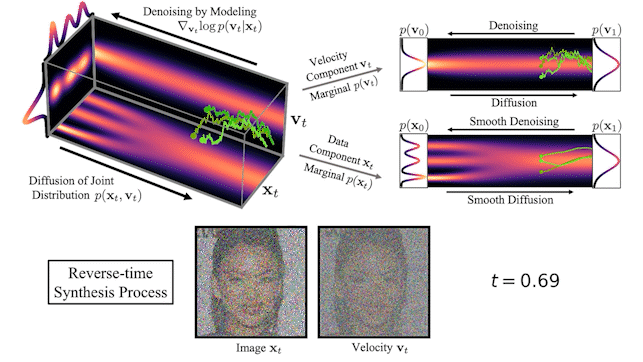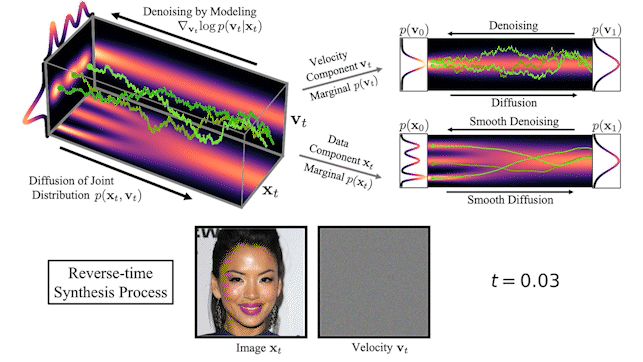
在图 3 的顶部,我们可视化了一维数据分布和速度如何在联合数据速度空间中扩散,以及生成如何以相反的方向进行。我们对三种不同的扩散轨迹进行了采样,并在右侧显示了到数据和速度空间的投影。在底部,我们将相应的扩散和合成过程可视化,以生成图像。我们看到速度在中间时间对数据进行“编码”
在培训生成性扩散模型时使用 CLD 有两个关键优势:
- 更简单的评分函数和培训目标
- 使用定制 SDE 解算器加速采样
更简单的评分函数和培训目标
在常规扩散模型中,神经网络的任务是学习扩散数据分布的得分函数

然而,由于速度总是遵循比数据本身更平滑的分布,这是一个更容易学习的问题。基于 CLD 的扩散模型中使用的神经网络可以更简单,同时仍能实现较高的生成性能。与此相关,我们还可以针对基于 CLD 的扩散模型制定改进的、更稳定的训练目标。
使用定制 SDE 解算器加速采样
要集成 CLD 的反向时间合成 SDE ,可以导出定制的 SDE 解算器,以便对 CLD 中产生的更平滑的正向扩散进行更有效的去噪。这会加速合成。
在实验上,对于广泛使用的 CIFAR-10 图像建模基准,对于类似的神经网络结构和采样计算预算, CLD 在合成质量上优于以前的扩散模型。此外, CLD 为生成性 SDE 量身定制的 SDE 解算器在生成速度方面明显优于 Euler – Maruyama 等解算器,后者是一种解决扩散模型中 SDE 的常用方法。有关更多信息,请参阅 基于分数的临界阻尼朗之万扩散生成模型 。

我们已经证明,只要仔细设计固定正向扩散过程,就可以改进扩散模型。
扩散算子去噪
到目前为止,我们已经讨论了如何通过将训练数据移动到平滑的潜在空间(如 LSGM )来加速扩散模型的采样,或者通过使用辅助速度变量来增加数据,以及设计改进的前向扩散过程(如基于 CLD 的扩散模型)。
然而,加速扩散模型采样的最直观的方法之一是直接减少反向过程中的去噪步骤。在这一部分中,我们回到离散时间扩散模型,在数据空间中进行训练,并分析在减少去噪步骤的数量和执行大步骤时,去噪过程的行为。
在最近的 study 中,我们观察到扩散模型通常假设反向合成过程中学习到的去噪分布
当反向生成过程使用较大的步长(去噪步骤较少)时,我们需要一个非高斯、多峰分布来建模去噪分布
直观地说,在图像合成中,多峰分布产生于多个看似合理且干净的图像可能对应于同一个噪声图像的事实。由于这种多模性,简单地减少去噪步骤的数量,同时在去噪分布中保持高斯假设,会损害发电质量。
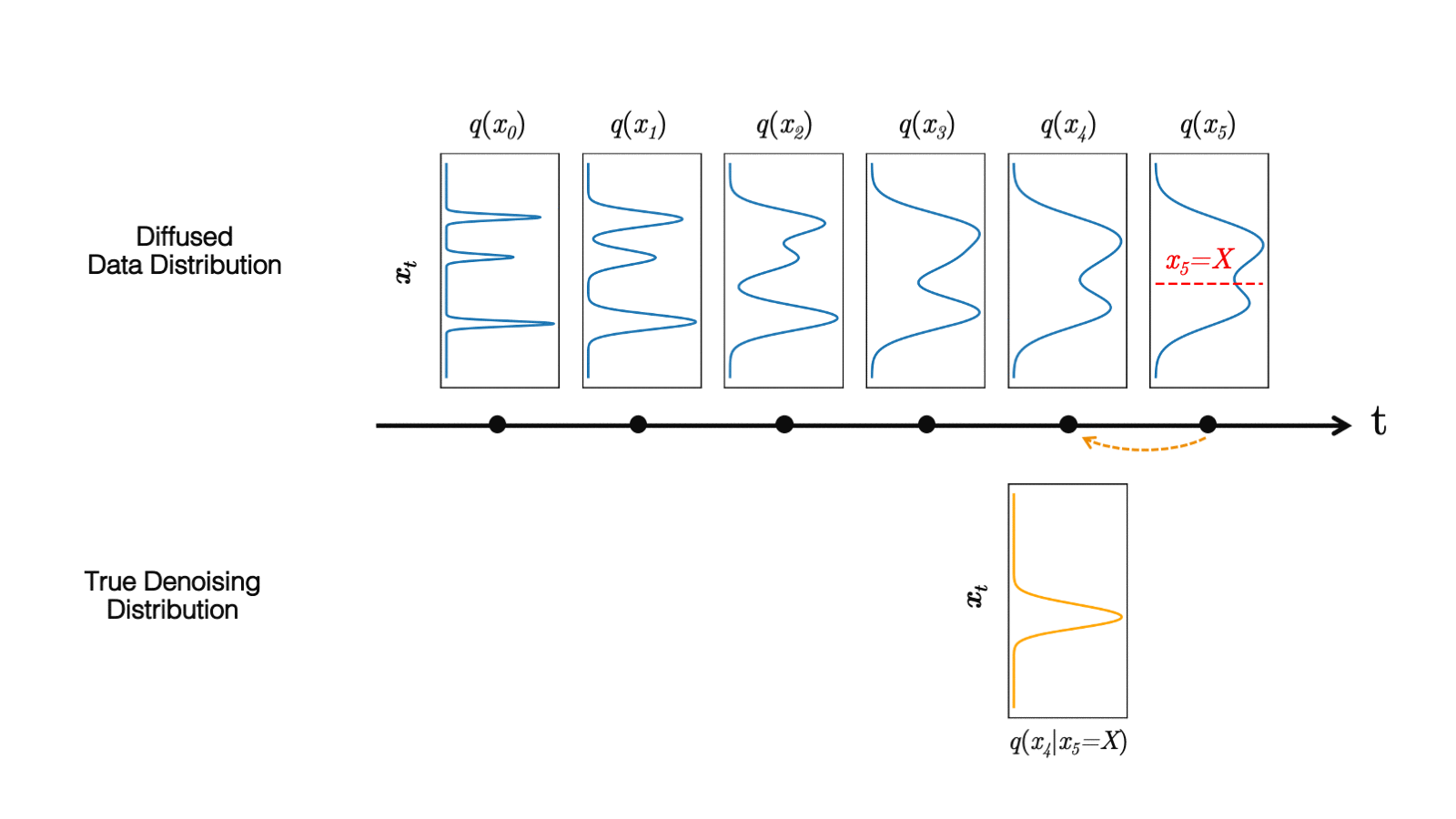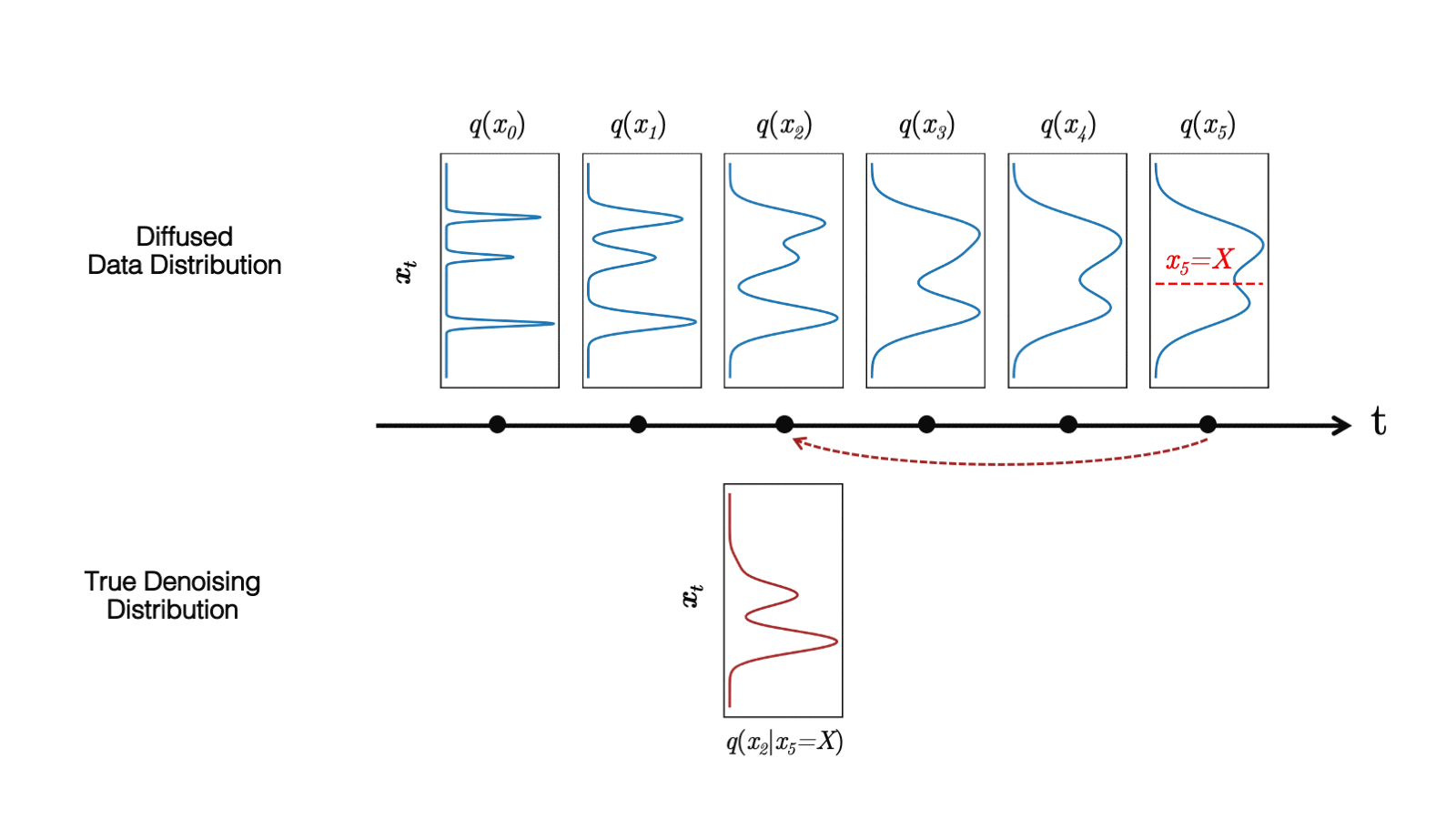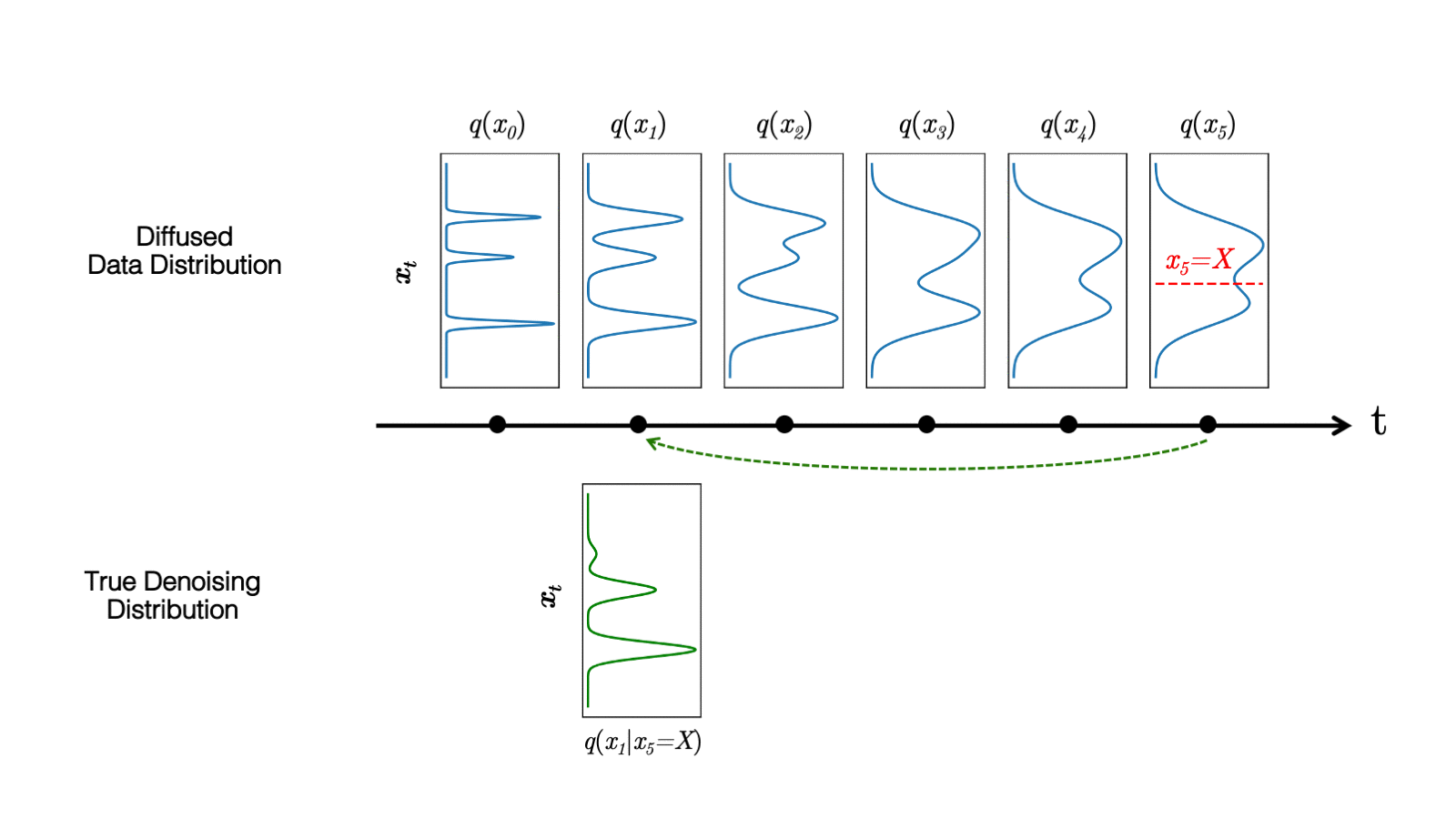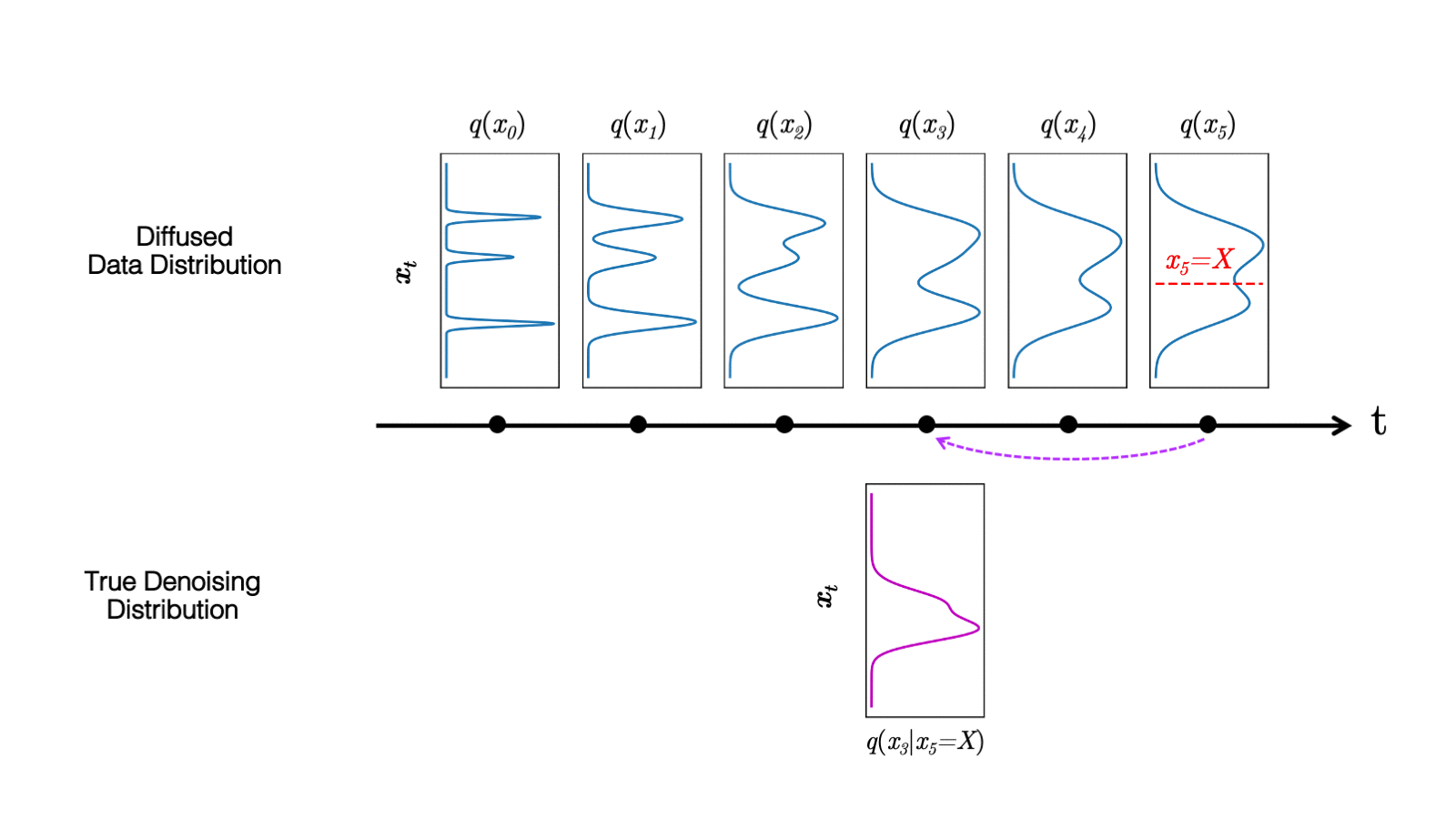
在图 5 中,小步距(以黄色显示)的真实去噪分布接近高斯分布。然而,随着步长的增加,它变得更加复杂和多模态。
受上述观察结果的启发,我们建议使用表达性多峰分布参数化去噪分布,以实现大步长去噪。特别是,我们引入了一种新的生成模型 去噪扩散 GAN ,在该模型中,使用条件 GAN 对去噪分布进行建模(图 6 )。
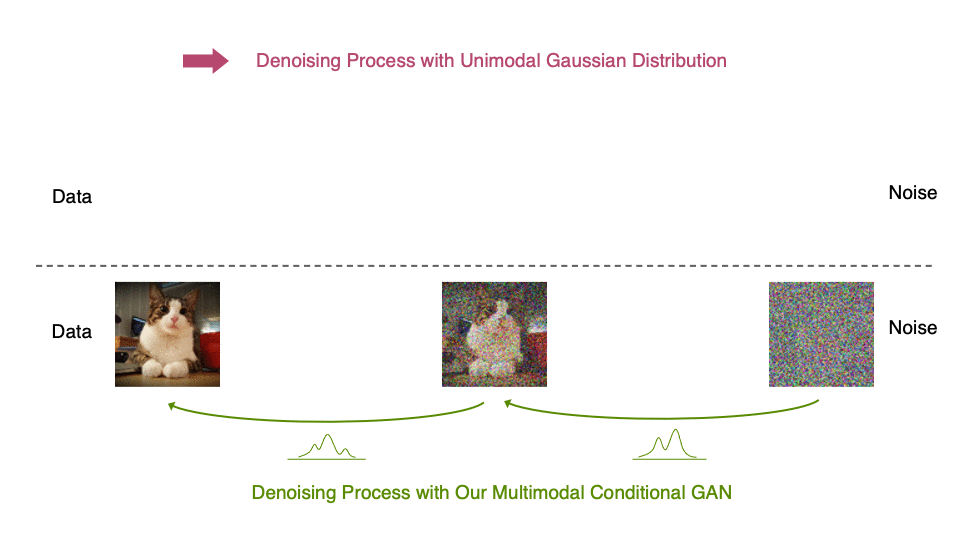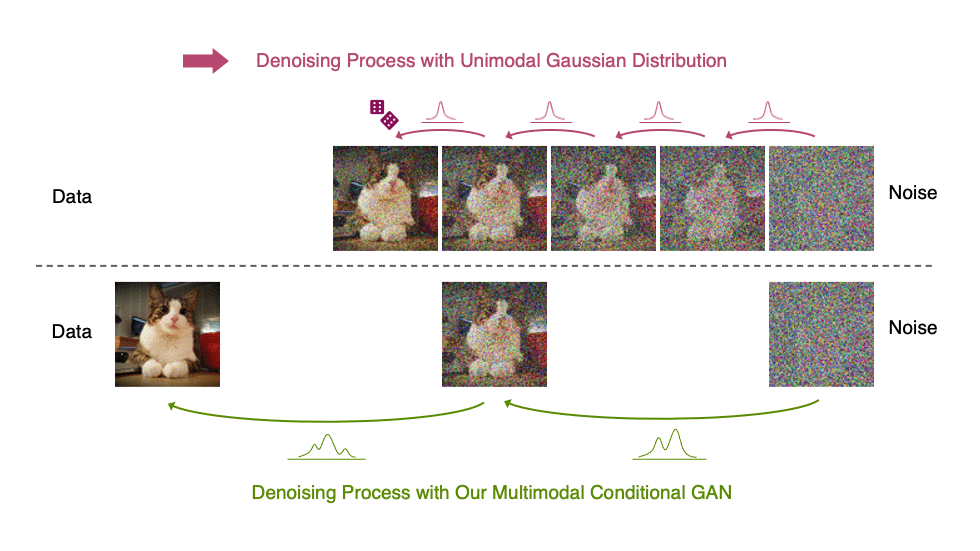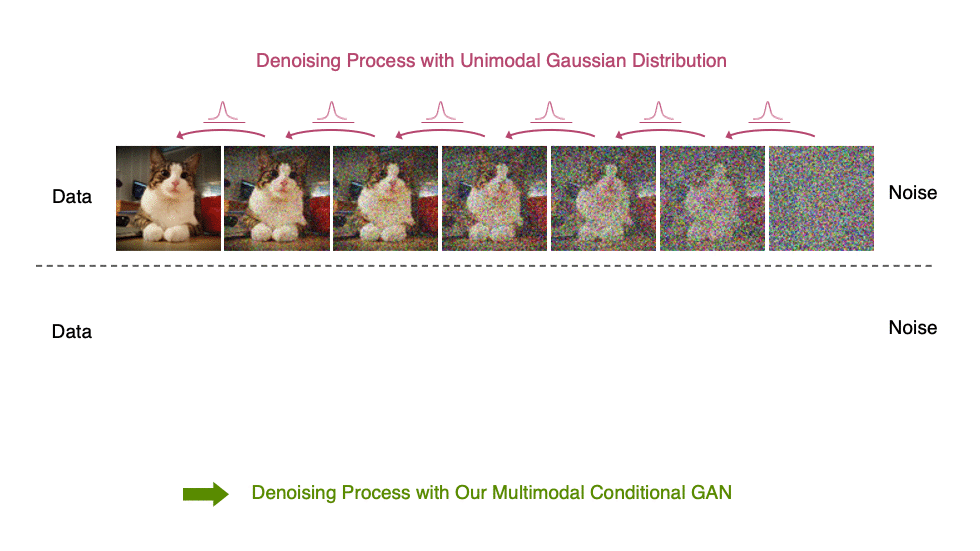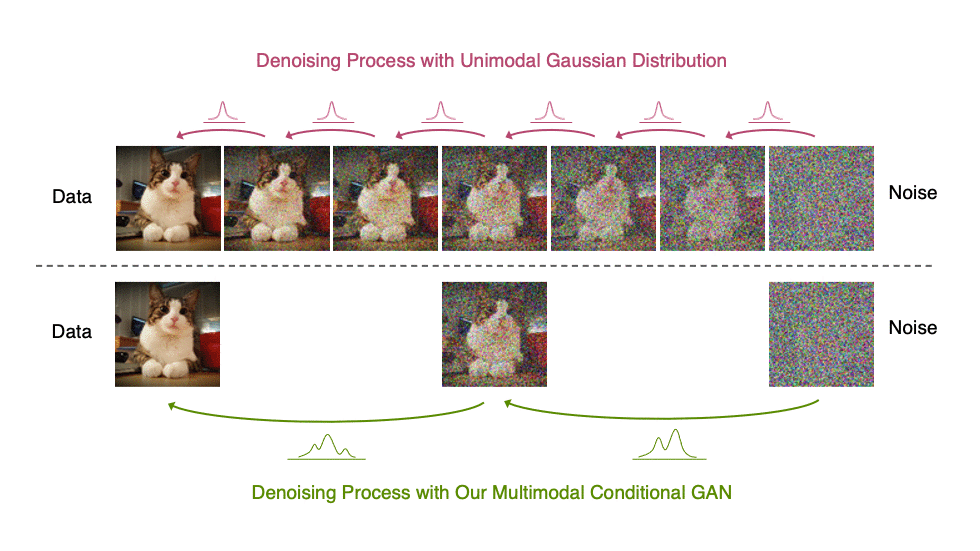
生成性去噪扩散模型通常假设去噪分布可以用高斯分布建模。这一假设仅适用于小的去噪步骤,实际上,这意味着合成过程中有数千个去噪步骤。
在我们的去噪扩散算法中,我们使用多模态和复杂条件算法来表示去噪模型,使我们能够在两个步骤中高效地生成数据。
使用对抗性训练设置对去噪扩散装置进行训练(图 7 )。给定一个训练图像

给定





在训练之后,我们通过从噪声中采样并使用我们的去噪扩散生成器在几个步骤中迭代去噪来生成新实例。

我们训练了一个条件 GAN 发生器,利用扩散过程中不同步骤的对抗性损失对输入
与传统干草相比的优势
与我们通过去噪迭代生成样本的模型相比,为什么不训练一个可以使用传统设置一次性生成样本的 GAN 呢?与传统的 GaN 相比,我们的模型有几个优点。
众所周知, GAN 会遭受训练不稳定和模式崩溃的影响。一些可能的原因包括难以从复杂分布中一次性直接生成样本,以及当鉴别器仅查看干净样本时存在过度拟合问题。
相比之下,由于
我们观察到,我们的模型具有更好的训练稳定性和模式覆盖率。在图像生成中,我们观察到我们的模型实现了与扩散模型竞争的样本质量和模式覆盖率,同时只需要两个去噪步骤。 与常规扩散模型相比,它的采样速度提高了 2000 倍。我们还发现,我们的模型在样本多样性方面显著优于最先进的传统 GAN ,同时在样本保真度方面具有竞争力。
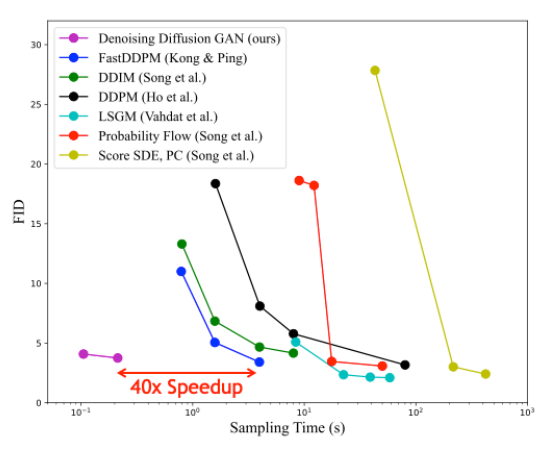
图 8 显示了与 CIFAR-10 图像建模基准的不同基于扩散的生成模型的采样时间相比,样本质量(通过 Fr é chet Inception 距离测量;越低越好)。与其他扩散模型相比,去噪扩散 GaN 在保持相似合成质量的同时实现了几个数量级的加速。
结论
扩散模型是一类很有前途的深层生成模型,因为它们结合了高质量的合成、强大的多样性和模式覆盖。这与常规 GAN 等方法形成对比,后者很受欢迎,但样本多样性有限。扩散模型的主要缺点是合成速度慢。
在本文中,我们介绍了 NVIDIA 最近开发的三种技术,它们成功地解决了这一挑战。有趣的是,他们每个人都从不同的角度处理问题,分析扩散模型的不同组成部分:
- 潜空间扩散模型 基本上简化了数据本身,首先将其嵌入平滑的潜在空间,在那里可以训练更有效的扩散模型。
- 临界阻尼朗之万扩散 是一种改进的前向扩散过程,特别适合于更简单、更快的去噪和生成。
- 扩散算子去噪 通过表达性多峰去噪分布,直接学习显著加速的反向去噪过程。
我们相信,扩散模型非常适合克服生成性学习的三重困境,尤其是在使用本文中强调的技术时。原则上,这些技术也可以结合使用。
事实上,扩散模型已经在深层生成性学习方面取得了重大进展。我们预计,它们可能会在图像和视频处理、 3D 内容生成和数字艺术以及语音和语言建模等领域得到实际应用。它们还将用于药物发现和材料设计等领域,以及其他各种重要应用。我们认为,基于扩散的方法有可能推动下一代领先的生成模型。
最后但并非最不重要的一点是,我们是 2022 年 6 月 19 日在美国路易斯安那州新奥尔良举行的 计算机视觉与模式识别 ( CVPR )会议期间举办的扩散模型、其基础和应用教程组织委员会的成员。如果您对这个主题感兴趣,我们邀请您观看我们的 基于去噪扩散的生成建模:基础与应用 教程。
要了解更多关于 NVIDIA 正在推进的研究,请参阅 NVIDIA Research 。
有关扩散模型的更多信息,请参阅以下参考资料:
- 基于分数的潜在空间生成建模 纸张
- 项目页面: /LSGM GitHub Repo
- 基于分数的临界阻尼朗之万扩散生成模型 纸张
- 项目页面: /CLD-SGM GitHub Repo
- 用去噪扩散算法解决生成性学习三难问题 纸张
- 项目页面: /denoising-diffusion-gan GitHub Repo




