NVIDIA Nsight 图形 的一个不太出名但很酷的功能是着色器探查器。这使您能够在着色器中找到热点,帮助您指导优化工作。它可以让你深入了解为什么有时候表现不是你喜欢的。
在本文中,我们使用 NVIDIA Nsight 图形 跟踪分析工具来识别潜在的限制器,然后使用着色器探查器进行更深入的挖掘,以发现并修复问题。
第一步:从 GPU 跟踪分析工具开始
我们总是建议从 Nsight Graphics GPU 跟踪工具开始,而不是直接进入着色器探查器。这样,您就可以了解任何给定 DX12 或 VK 工作负载的性能限制是什么。例如,如果真正的问题是 GPU 利用率低,因为有很多微小的调度,它们之间都有屏障,那么尝试微调着色器是没有意义的。
首先,设置与要分析的应用程序的连接。选择 Connect 并填写启动游戏所需的参数(图 1 )。
选择GPU Trace 作为活动,将 Metric Set 配置为 高级模式度量 。 使用 高级模式度量 需要一个稳定且一致的框架,因为分析会在多个框架上进行多次传递。如果应用程序不满足这些要求,可以使用 Nsight Graphics 内置的 C ++捕获工具捕获应用程序的一个帧,并创建一个新的 EXE ,重复播放同一帧。
选择启动 GPU Trace 启动应用程序。当你到达你想要捕捉的画面时,选择生成 GPU Trace 捕获或者按 F11 。
捕获完成后,停止应用程序并打开跟踪。选择 Trace Analysis 。在的 Analysis 面板中GPU Trace(图 2 ),双击或将鼠标悬停在要分析的范围的标记上,在本例中,DispatchRays[0]:
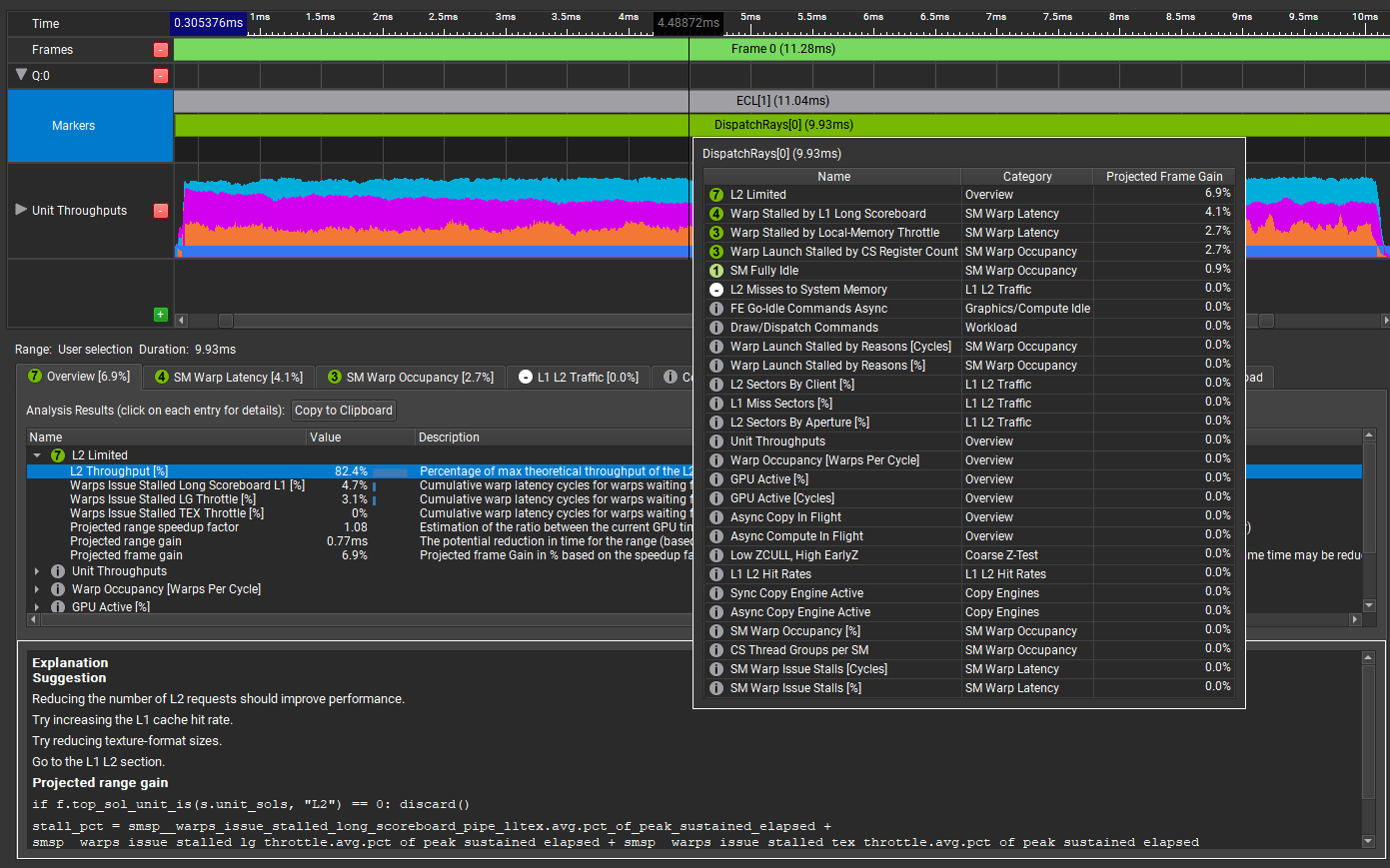
工具提示显示了该工具在此 GPU 工作负载中检测到的所有性能增益机会的简洁视图,按其预计的 GPU 帧时间增益排序。工作负载有以下限制:
- L2 Limited : L2 受限可能表明存在问题。有了工作量方面的知识,这不一定是你所期望的。
- L1 长记分板暂停的翘曲: 这是翘曲停止的常见原因,通常是由于纹理提取。如果在启动纹理查找和使用查找的结果之间没有足够的工作,则会暂停扭曲,直到满足纹理查找。
- 扭曲被本地内存限制暂停 :本地内存是“线程本地”。它是每个线程的本地内存,而不是线程组中所有线程之间共享的组共享内存。着色器不需要任何本地内存,所以这很有趣。本地内存节流意味着什么?这里还有很多东西要学。
选择 SM 翘曲延迟 和 扭曲被本地内存限制暂停 。
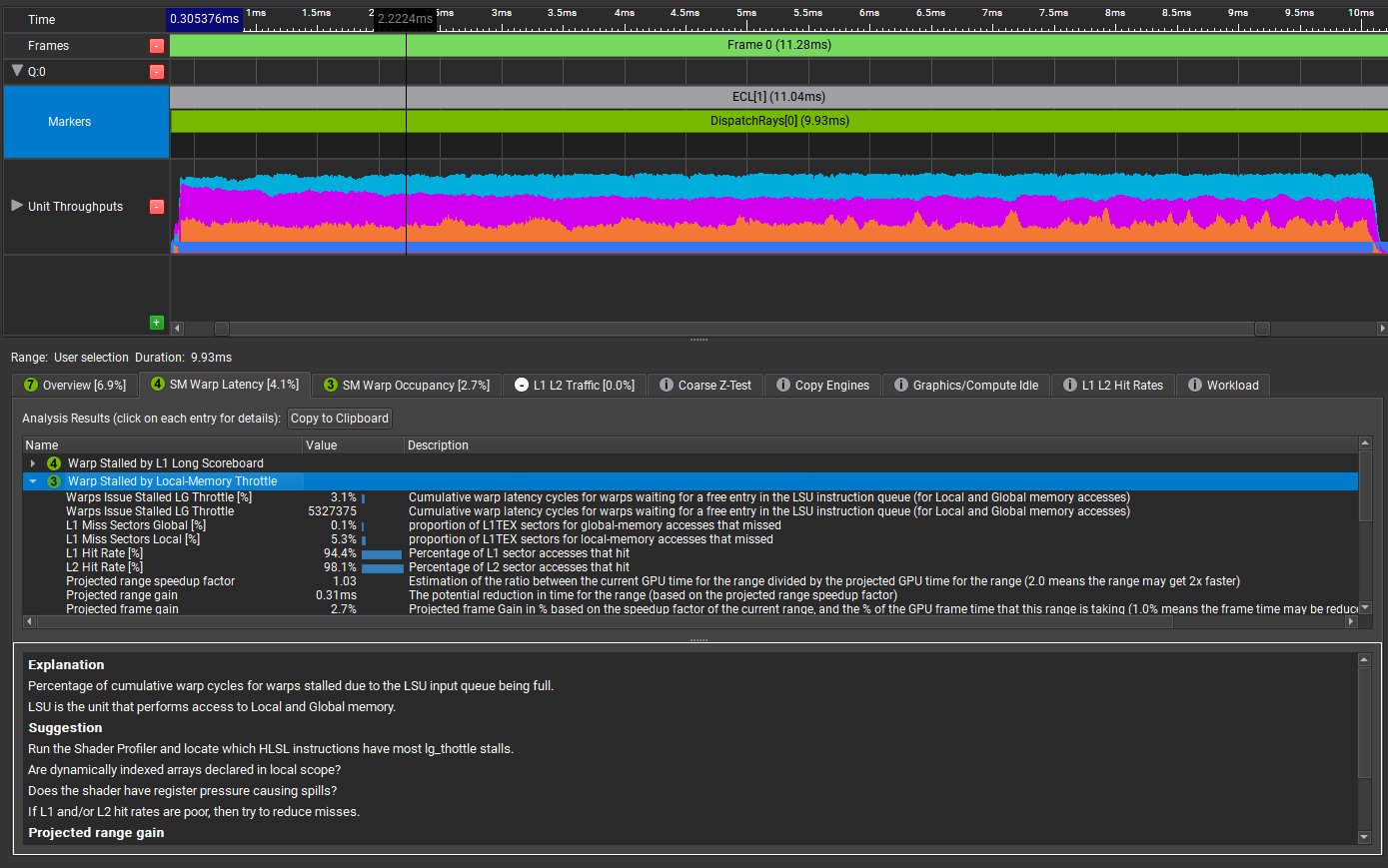
解释窗口对问题进行了更有意义的描述,并提供了一些有用的建议。它建议启动着色器探查器,以定位具有lg_throttle暂停的特定 HLSL 指令。
第 2 步:切换到着色器探查器
在使用着色器探查器之前,务必确保 Nsight Graphics 可以访问着色器的符号。实现这一点的最简单方法是确保着色器为 使用/ Zi 选项编译 ,并将符号嵌入着色器二进制文件中。
有时,最好配置编译,使符号进入外部 PDB 文件。在这种情况下,请确保在 Tools 、 Options 下指定正确的路径。
当 Nsight Graphics 可以看到着色器符号时,它可以将着色器中的位置映射回源代码,这使您更容易判断发生了什么。如果 Nsight Graphics 无法访问符号,则只能看到着色器反汇编(例如, DXIL )。
着色器探查器是帧探查器的一部分。再次连接到应用程序,但这次选择 Activity 下的 Frame Profiler 。当您选择 发射架剖面仪 时,应用程序应该在这个 HUD (图 4 )的顶部启动。

导航至应用程序中要配置文件的部分,然后按 F11 键捕获一帧进行分析。从这里,在 Nsight Graphics 中选择 Profile Shaders 。这将运行一个简短的采样会话,然后向您展示一个摘要视图(图 5 )。
这是一个故障。
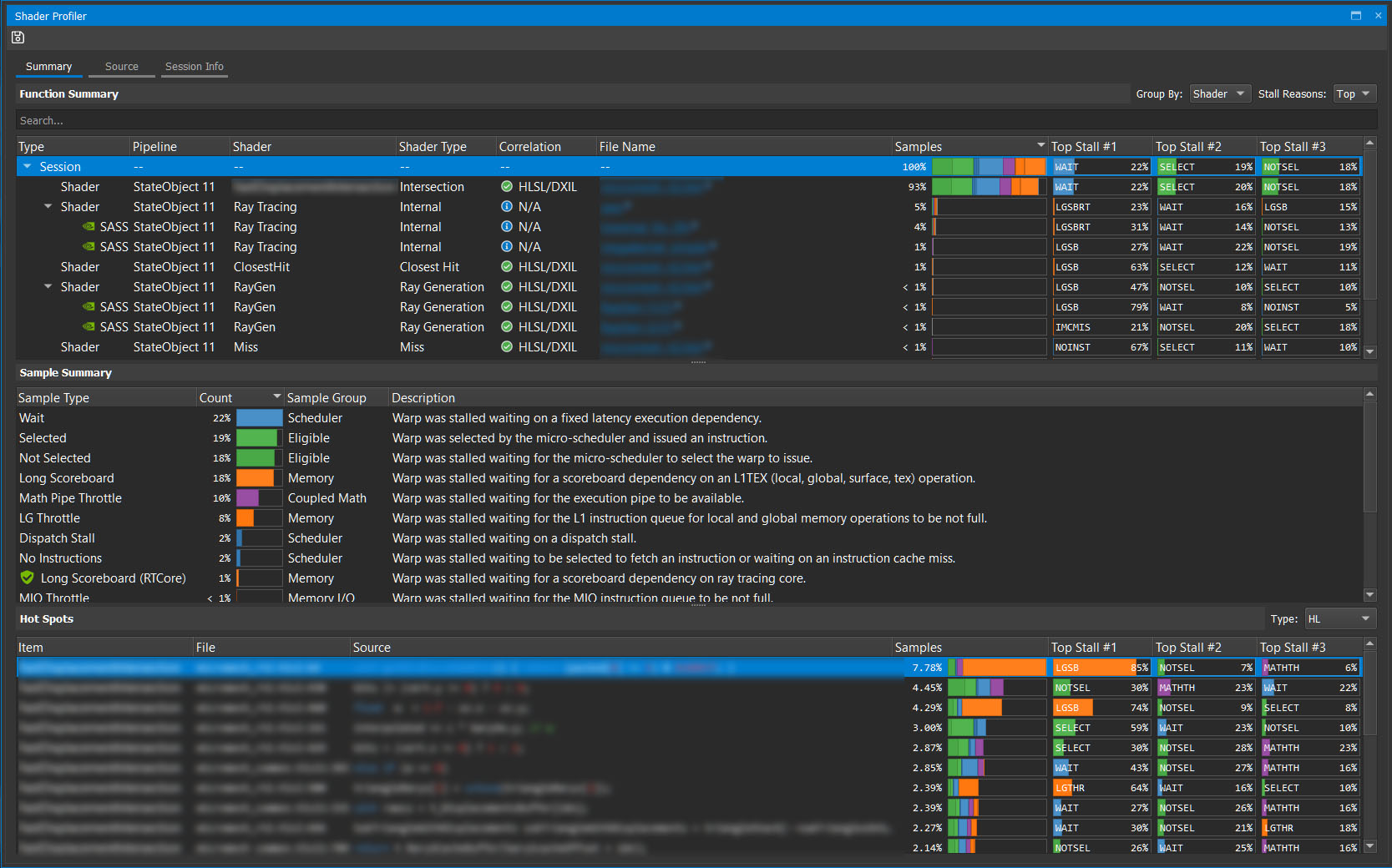
Function Summary 按在这些着色器中命中的采样数的顺序显示顶级着色器的列表。这是一个很好的着色器延迟代理,可以让您专注于可以从优化中获得最大好处的着色器。
在 Correlation 列中,有多个绿色记号,它们总是好的。在本例中,这意味着 Nsight Graphics 能够将样本与源代码关联起来。
要打开着色器视图,请选择第一个文件名。左边是源代码,右边是 DXIL 。在本文中,您不必关心 DXIL ,所以将视图更改为仅使用 HLSL
这很微妙,但在最右边的滚动条右边有一个重要的指令样本热图。回想起GPU Trace 分析建议你找lg_throttle摊位。上面说:
LSU 是执行对本地和全局内存访问的单元。
运行着色器探查器,找到哪个 HLSL 指令的 lg _ thottle 暂停最多。
是否在本地范围内声明动态索引数组?
着色器是否有导致溢出的注册压力?
如果一级和二级命中率很低,那么尽量减少未命中率。
在着色器探查器中,由于lg_throttle原因,显示为 LGTHR 的采样被暂停。
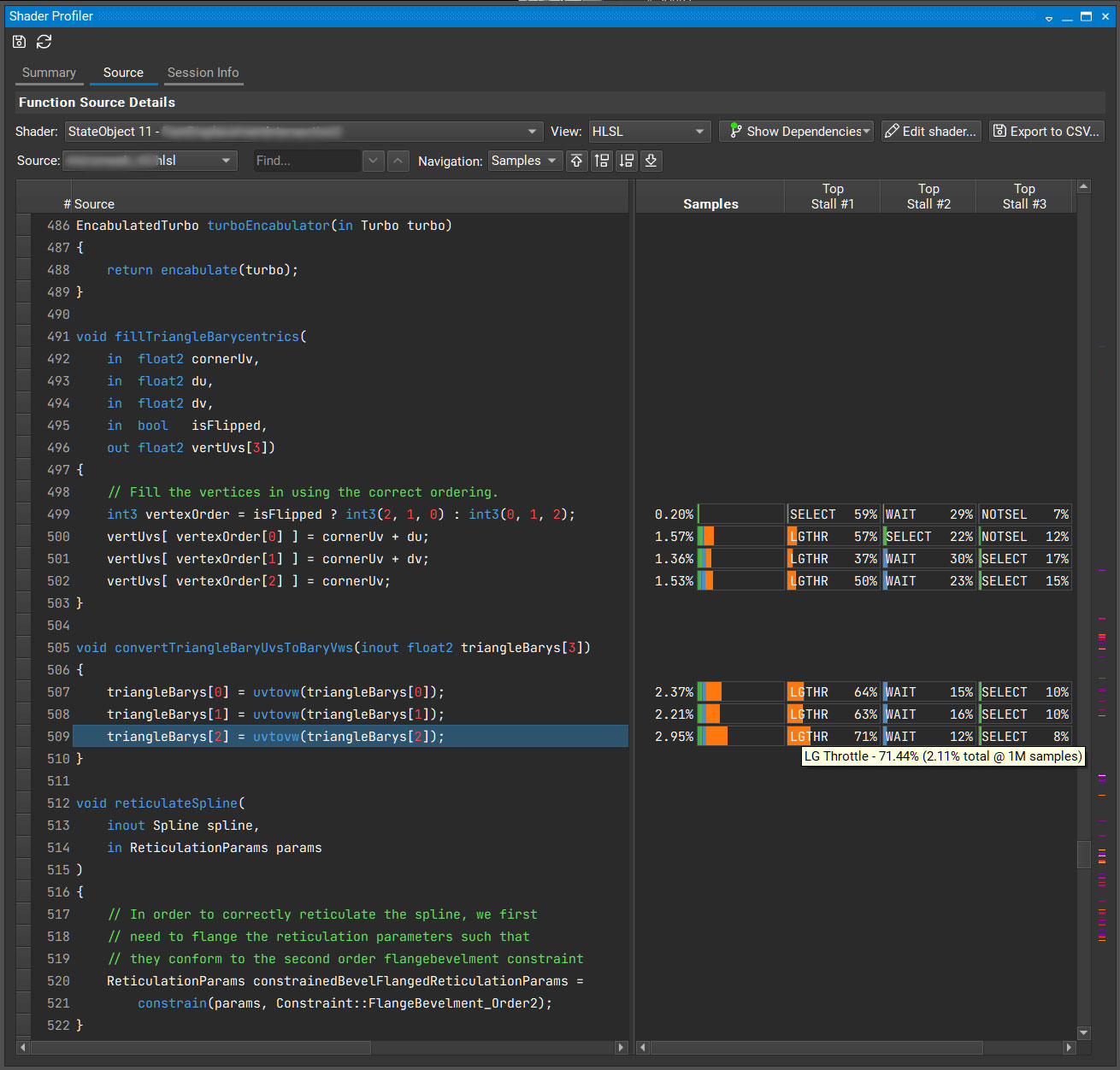
“是否在本地范围内声明了动态索引数组?”
动态索引数组由一个变量索引,其中索引的值在编译时是未知的。
当这种情况发生时,编译器通常会将数组放入本地内存,而不是放在寄存器中。内存比寄存器慢。
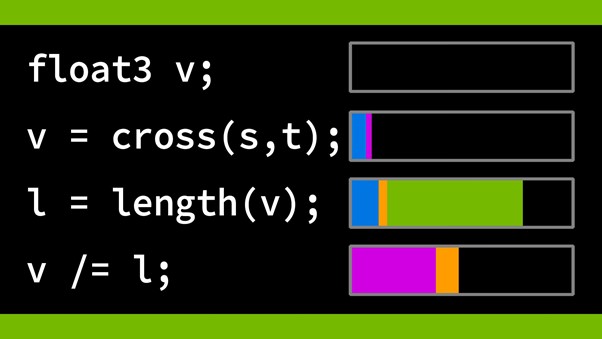
下面的代码示例显示了一个动态索引数组。
vertUvs[vertexOrder[0]] = cornerUv + du; vertUvs[vertexOrder[1]] = cornerUv + dv; vertUvs[vertexOrder[2]] = cornerUv;
怎么回事?看起来代码以不同的顺序填充数组,这取决于三角形是否翻转。
int3 vertexOrder = isFlipped ? int3(2, 1, 0) : int3(0, 1, 2);
动态索引该数组的行为会使编译器将该数组移动到内存中。它会影响这个代码位以及引用该数组的所有代码位。这就是为什么convertTriangleBaryUvsToBaryVws也很热门。
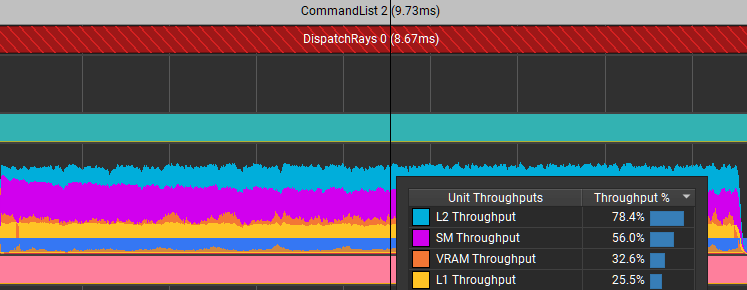
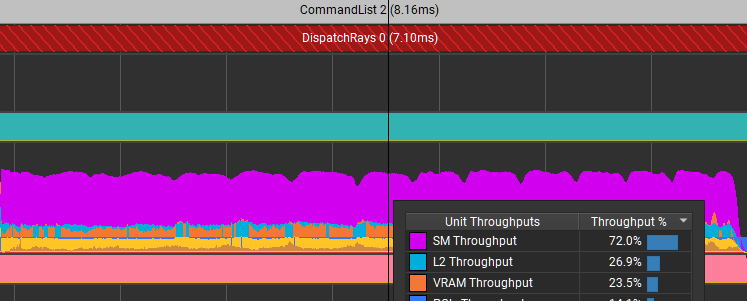
你能在没有动态索引的情况下做到这一点吗?是的,你可以。更改翻转方式的结果如图 7 所示。

那些特定的摊位被取消了。它将此调度的时间从 8.67 毫秒减少到 7.1 毫秒。它不仅提高了着色器代码的效率,而且由于内存流量减少,还大大减少了 L2 中的限制器。
总结
NVIDIA Nsight 图形 是分析渲染工作负载的强大工具。这是一个快速的演练,只涉及一些功能。我们强烈建议使用它。
免责声明
从驱动程序版本 467.07 开始,本文中的测试和结果都是正确的。驱动程序和编译器开发一直在继续。这意味着优化机会也会随着时间的推移而改变。




