11 月 8 日至 11 日加入 NVIDIA ,展示超过 500 个GTC课程,涵盖 AI 和深度学习的最新突破,以及许多其他 GPU 技术兴趣领域。
下面是一些顶级人工智能和深度学习课程的预览,包括培训、推理、框架和工具等主题,这些主题由 NVIDIA 的演讲者提供。
培训
深度学习揭开神秘面纱:人工智能已经发展并改进了数据分析和复杂计算的方法,解决了几年前我们还远远无法解决的问题。学习加速数据分析、高级用例和问题解决方法的基础知识,以及深入学习如何改变每个行业。我们将介绍人工智能的去神秘化、机器学习和深度学习;了解组织在采用这种新方法时面临的主要挑战;以及有助于取得突破性成果的最新工具和技术。
多 GPU s 的深度学习基础:现代深度学习挑战利用越来越大的数据集和更复杂的模型。因此,高效地训练模型需要大量的计算能力。在本课程中,您将学习如何将深度学习培训扩展到多个 GPU s 。使用多个 GPU 进行深度学习可以显著缩短训练大量数据所需的时间,使通过深度学习解决复杂问题成为可能。
推理
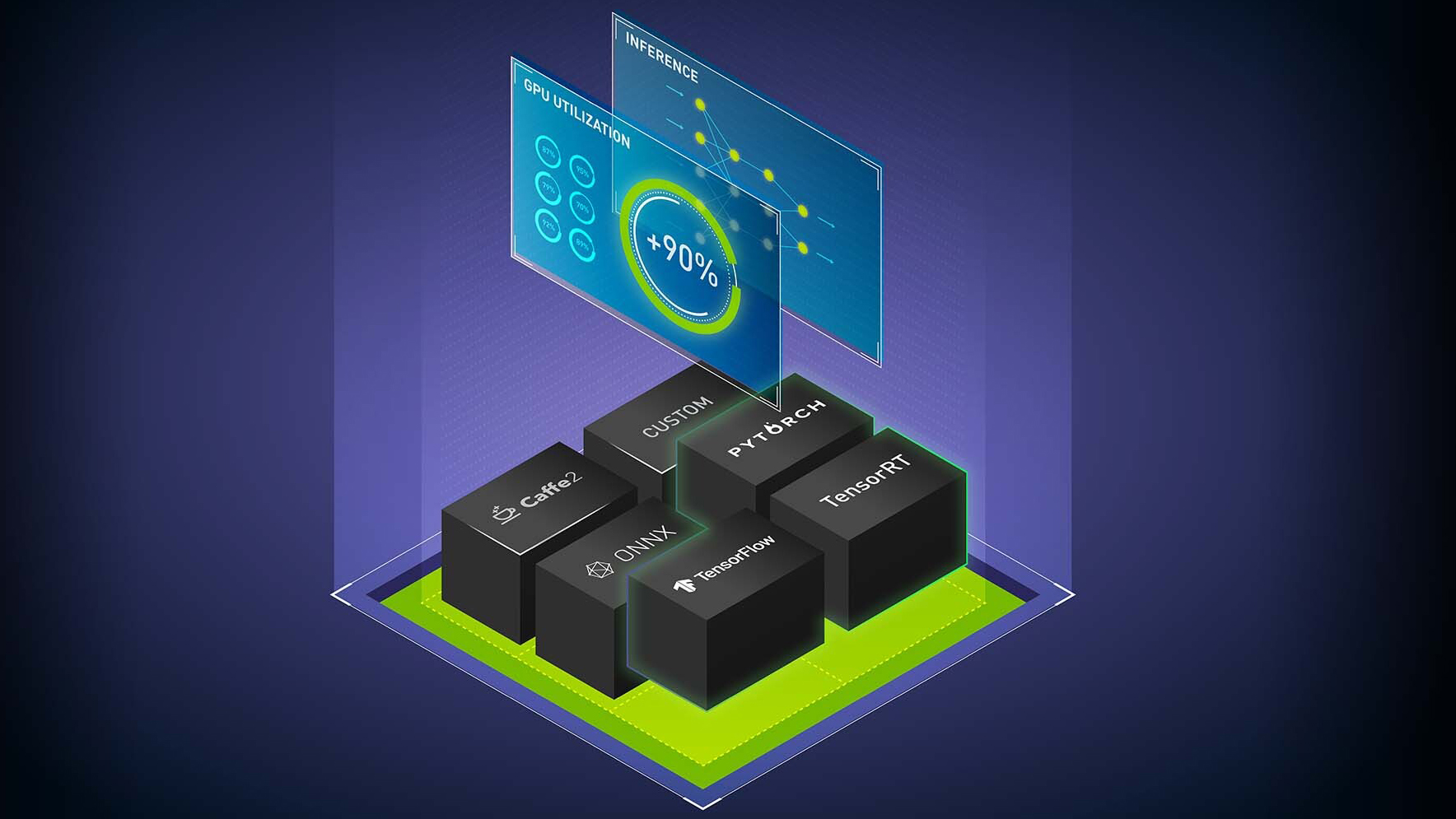
使用 NVIDIA Triton 推理服务器最大化 AI 推理服务性能: NVIDIA Triton 是一款开源推理服务软件,可简化人工智能模型在生产中的大规模部署。使用 NVIDIA Triton 在任何基于 Triton 或 CPU 的基础设施上,从任何框架( TensorFlow 、 TensorRT 、 PyTorch 、 OpenVINO 、 ONNX 运行时、 XGBoost 或 custom )部署深度学习和机器学习模型。我们将讨论一些新的后端、对嵌入式设备的支持、公共云上的新集成、模型集成和其他新功能。
使用 TensorRT 加速 PyTorch 推理:学习如何在不使用 Torch- TensorRT 离开框架的情况下加速 PyTorch 推理。 Torch- TensorRT 使 NVIDIA TensorRT GPU 优化的性能在 PyTorch 中可用于任何型号。您将了解 Torch- TensorRT 的关键功能、如何使用它们以及您可以预期的性能优势。我们将介绍如何从经过训练的模型过渡到针对特定硬件进行微调的推理部署,只需几行熟悉的代码。
使用 TensorRT 加速生产中的深度学习推理: TensorRT 是一款用于生产中使用的高性能深度学习推理的 SDK ,可最大限度地减少延迟和提高吞吐量。最新一代的 TensorRT 提供了一个新的编译器来加速为 NVIDIA GPU 优化的特定工作负载。深度学习编译器需要有一种健壮的方法来导入、优化和部署模型。我们将展示一个加速框架的工作流,包括 PyTorch 、 TensorFlow 和 ONNX 。
工具和框架
创建生产就绪 AI 模型的零代码方法: NVIDIA TAO 是一种用户界面驱动、基于工作流的模型自适应引导解决方案,允许用户在数小时而不是数月内生成高度准确的计算机视觉或对话人工智能模型。这样就不需要大量的训练和深入的人工智能专业知识。我们将演示 TAO 如何通过采用预先训练好的模型、使用数据对其进行微调,以及在不编写任何代码的情况下优化推理来授权用户。
使用 NGC 加速 AI 工作流:为了简化人工智能的开发, NVIDIA NGC 提供了开发工具和 SDK ,可以加速人工智能在医疗、智能城市和机器人等行业的培训、推理和部署。我们将介绍数据科学家和开发人员如何使用 NGC (通过容器、预训练模型和 SDK )跨本地、混合和边缘平台更快地构建和部署 AI 解决方案。我们将以演示结束,演示如何轻松开始构建计算机视觉解决方案,并为您留下一个 Jupyter 笔记本,以便您可以脱机重建自定义解决方案。