在生产规模上部署推理模型
很多人喜欢构建机器学习模型。挑战包括确定要预测的变量、寻找最佳模型体系结构的实验,以及对正确的训练数据进行采样。但是,如果您无法访问该模型,它又有什么好处呢?
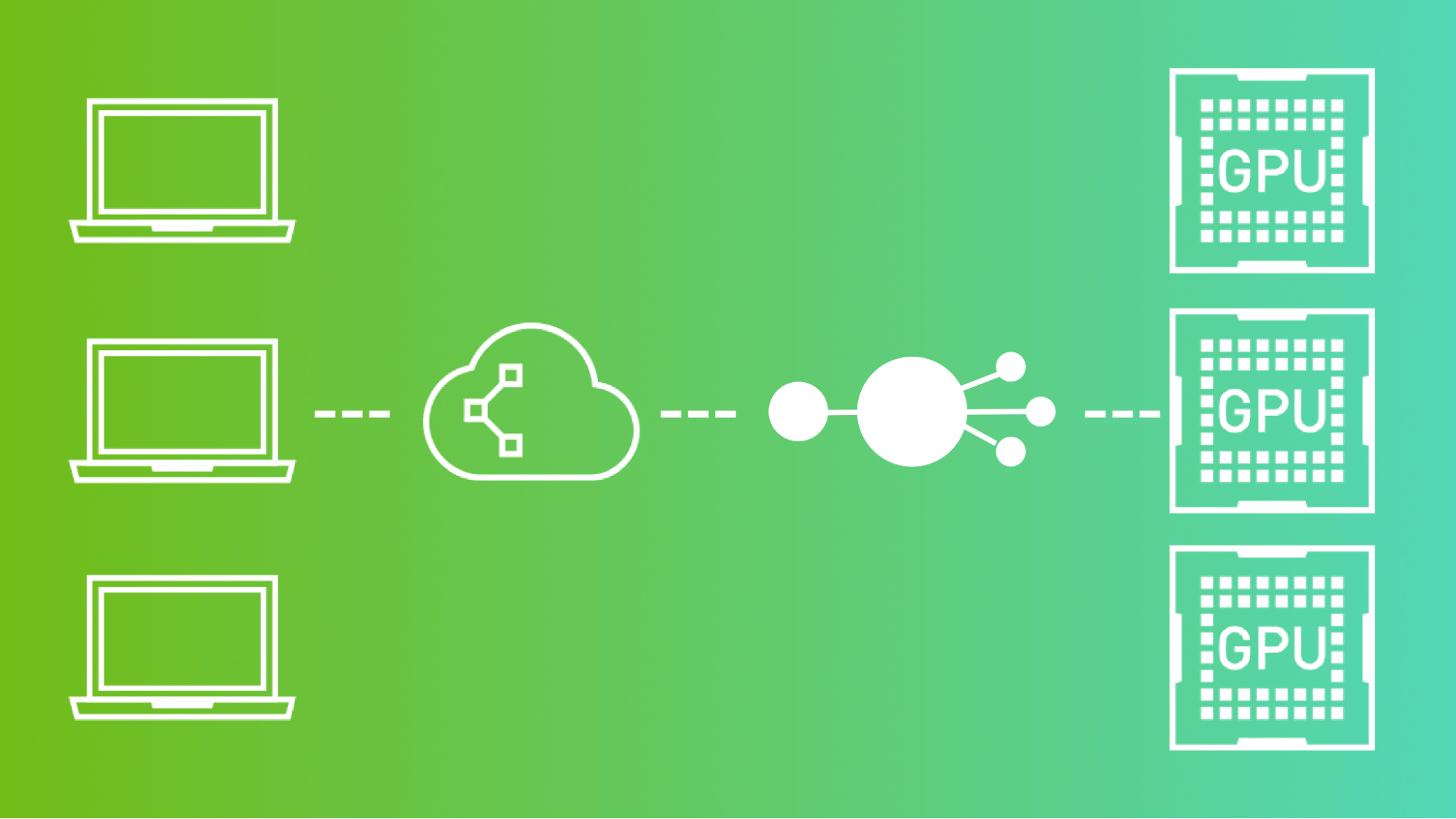
进入 NVIDIA Triton 推理服务器 . NVIDIA Triton 帮助数据科学家和系统管理员将用于训练模型的机器转变为用于模型预测的 web 服务器。虽然不需要 GPU ,但 NVIDIA Triton 推理服务器可以利用多个安装的 GPU 快速处理大批量请求。
为了获得实时服务器的实践, NVIDIA 深度学习培训中心(DLI) 提供了一个名为大规模推理部署模型的 4 学时在线自主培训课程。
MLOps 概述
NVIDIA Triton 是在考虑到 机器学习操作 或 MLOps 的情况下创建的。 MLOps 是从开发人员操作( DevOps )演变而来的一个相对较新的领域,其重点是在生产环境中扩展和维护机器学习模型。 NVIDIA Triton 配备了模型版本控制等功能,以方便回滚。它还与 Prometheus 兼容,以跟踪和管理服务器指标,如延迟和请求计数。
课程信息
本课程介绍 MLOps ,并结合现场 NVIDIA Triton 推理服务器的实践。
学习目标包括:
- 将各种框架中的神经网络部署到实时 NVIDIA Triton 服务器上。
- 使用普罗米修斯测量 GPU 使用率和其他指标。
- 发送异步请求以最大化吞吐量。
完成后,开发人员将能够在 NVIDIA Triton 服务器上部署自己的模型。
有关更多实践培训,请访问 NVIDIA 深度学习培训中心(DLI) 。