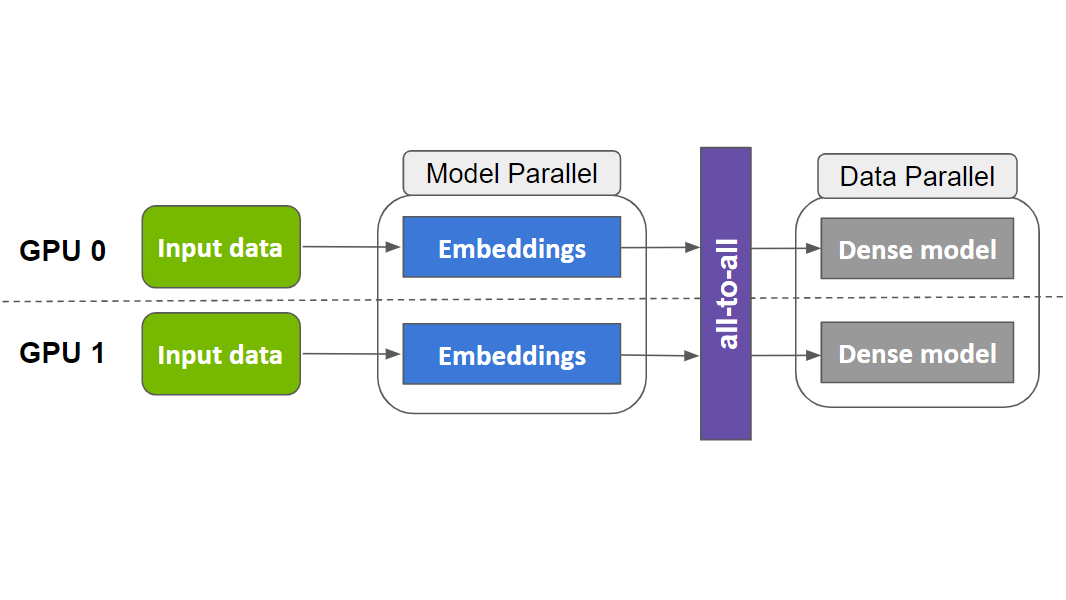
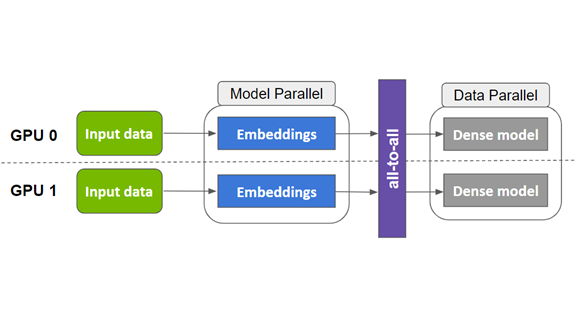
Embedding在深度学习推荐模型中起着关键作用。它们被用于将输入数据中的离散特征映射到向量,以便下游的神经网络进行处理。Embedding 通常构成深度学习推荐模型中的大部分参数,大小可以达到 TB 级。在训练期间,很难将它们放入单个 GPU 的内存中。因此,现代推荐系统可能需要模型并行和数据并行的分布式训练方法组合,以最佳利用GPU计算资源来实现最好的训练性能。
NVIDIA Merlin Distributed-Embeddings ,可以方便TensorFlow 2 用户用短短几行代码轻松完成大规模的推荐模型训练。
背景
在数据并行分布式训练中,整个模型被复制到每个 GPU 上。在训练过程中,一批输入数据在多个 GPU 中分割,每张卡独立处理其自己的数据分片,从而允许计算扩展到更大批量的数据。在反向传播期间,计算的梯度通过reduction算子(例如, horovod.tensorflow.allreduce ) 来同步更新多个GPU间的参数。
另一方面,模型并行分布式训练中,模型参数被分割到多个GPU上。这种方法更适合分布存储大型embedding。训练中,每个GPU 通过alltoall通信算子(例如, ) 访问不在本机中的参数。
在之前的相关文章中, 用TensorFlow 2 在DGX A100上训练100B +参数的推荐系统 , Tomasz 讨论了如何将1130 亿参数的DLRM 模型中的embedding分布到多个 NVIDIA GPU 进行训练,并相比纯CPU 的方案实现 672 倍的性能提升。这一重大突破可以将训练时间从几天缩短到几分钟!这是通过模型并行 embedding层和数据并行MLP层来实现的。和CPU方案相比,这种混合并行的方法能够有效利用GPU 的高内存带宽加速内存受限的embedding查找,并同时利用多个 GPU 的算力加速 MLP 层。作为参考, NVIDIA A100-80GB GPU 具有超过 2 TB / s 的带宽和 80 GB HBM2 存储)。
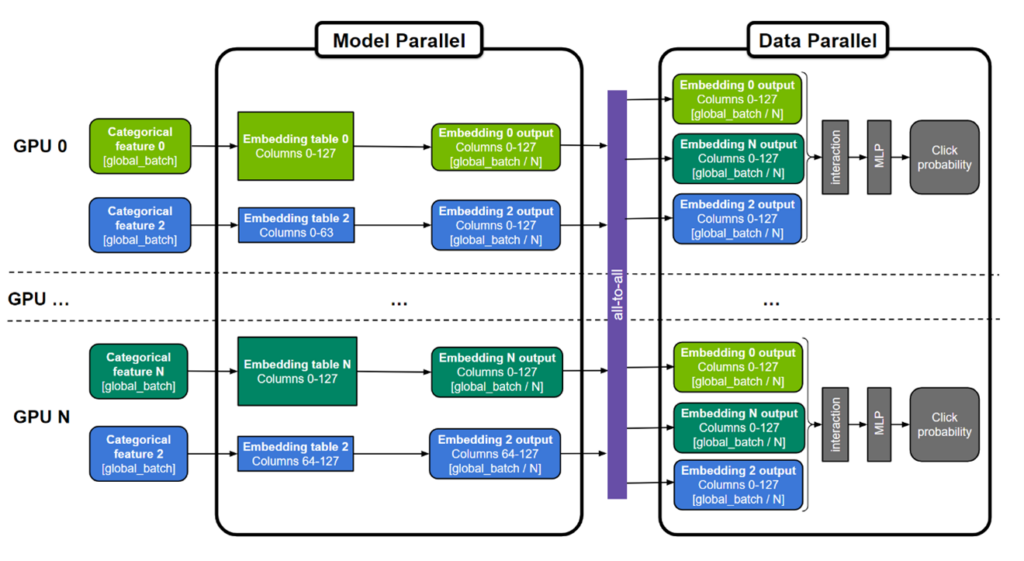
图 1.用于训练大型推荐系统的通用“混合并行”方法
embedding表可以按表为分割单位(图中表 0 和 N ),按”列“分割(图中表 2),或者按”行”分割。MLP 层跨所有 GPU 复制,而数字特征则可以直接输入 MLP 层。
然而,实现这种复杂的混合并行训练方法并不简单,需要领域内专家设计数百行底层代码来开发和优化。为了使其更普适, NVIDIA Merlin Distributed-Embeddings 提供了一些易于使用的TensorFlow 2的封装,让所有人都只需三行 Python 代码即可轻松实现模型并行。它提供了一些涵盖并拓展原生TensorFlow功能的高性能embedding查找算子。在此基础上,它提供了一个可规模化的模型并行封装函数,帮助用户自动将embedding分布于多个GPU上。下面将展示它如何实现混合并行。
分布式模型并行
NVIDIA Merlin Distributed-Embeddings 提供了 distributed_embeddings.dist_model_parallel 模块。它有助于在多个 GPU 之间分布embedding而无需任何复杂的代码来处理跨GPU间的通信(如 all2all )。下面的代码示例显示了此 API 的用法:
import dist_model_parallel as dmp
class MyEmbeddingModel(tf.keras.Model):
def __init__(self, table_sizes):
…
self.embedding_layers = [tf.keras.layers.Embedding(input_dim, output_dim) for input_dim, output_dim in table_sizes]
# 1. Add this line to wrap list of embedding layers used in the model
self.embedding_layers = dmp.DistributedEmbedding(self.embedding_layers)
def call(self, inputs):
# embedding_outputs = [e(i) for e, i in zip(self.embedding_layers, inputs)]
embedding_outputs = self.embedding_layers(inputs)
…
要使用 Horovod 以数据并行方式运行MLP层,请将 Horovod的 Distributed GradientTape 和 broadcast 方法替换成 NVIDIA Merlin Distributed-Embeddings 里同等的API。以下示例直接取自 Horovod 文档,并进行了相对应修改。
@tf.function
def training_step(inputs, labels, first_batch):
with tf.GradientTape() as tape:
probs = model(inputs)
loss_value = loss(labels, probs)
# 2. Change Horovod Gradient Tape to dmp tape
# tape = hvd.DistributedGradientTape(tape)
tape = dmp.DistributedGradientTape(tape)
grads = tape.gradient(loss_value, model.trainable_variables)
opt.apply_gradients(zip(grads, model.trainable_variables))
if first_batch:
# 3. Change Horovod broadcast_variables to dmp’s
# hvd.broadcast_variables(model.variables, root_rank=0)
dmp.broadcast_variables(model.variables, root_rank=0)
return loss_value
通过这些微小的改变,您就可以使用混合并行训练了!
我们还提供了以下完整示例: 使用 Criteo 1TB 点击日志数据训练 DLRM 模型 以及 扩展到 22.8 TiB的合成数据 模型。
性能
为了展示 NVIDIA Merlin Distributed-Embeddings 的性能,我们在 Criteo 1TB 数据集DLRM 模型和最高达到 3 TiB embedding的合成模型上进行了模型训练的基准测试。
Criteo 数据集上的 DLRM 模型基准测试
测试表明,我们使用更简单的 API 取得了近似于专家代码的性能。NVIDIA深度学习DLRM TensorFlow 2示例代码现已更新为使用 NVIDIA Merlin Distributed-Embeddings 进行分布式混合并行训练,更多信息请参阅我们之前的文章, 用TensorFlow 2 在DGX A100上训练100B +参数的推荐系统. README中的 基准测试 部分提供了对性能结果的更多详述。
我们对1130 亿个参数( 421 个 GiB 大小)的 DLRM 模型在 Criteo TB 点击日志 数据集上用三种不同的硬件设置进行了训练:
- 仅 CPU 的解决方案。
- 单 GPU 解决方案,其中 CPU 内存用于存储最大的embedding表。
- 使用 NVIDIA DGX A100-80GB 的 8 GPU 的混合并行解决方案。此方案利用了 NVIDIA Merlin Distributed-Embeddings 里提供的模型并行api和embedding API 。
|
Hardware |
Description |
Training Throughput (samples/second) |
Speedup over CPU |
|
2 x AMD EPYC 7742 |
Both MLP layers and embeddings on CPU |
17.7k |
1x |
|
1 x A100-80GB; 2 x AMD EPYC 7742 |
Large embeddings on CPU, everything else on GPU |
768k |
43x |
|
DGX A100 (8xA100-80GB) |
Hybrid parallel with NVIDIA Merlin Distributed-Embeddings, whole model on GPU |
12.1M |
683x |
表 1.各种设置的训练吞吐量和加速
我们观察到, DGX-A100 上的 NVIDIA Merlin Distributed-Embeddings 方案比仅使用 CPU 的解决方案提供了惊人的 683 倍的加速!我们还注意到与单GPU 方案相比,混合并行的性能也有显著提升。这是因为在 GPU 显存中存储所有embedding避免了通过 CPU-GPU 接口查找embedding的开销。
合成模型基准测试
为了进一步演示方案的可规模化,我们创建了不同大小的合成数据以及对应的 DLRM 模型(表 2 )。有关模型生成方法和训练脚本的更多信息,请参见 GitHub NVIDIA-Merlin/distributed-embeddings 代码库。
|
Model |
Total number of embedding tables |
Total embedding size (GiB) |
|
Tiny |
55 |
4.2 |
|
Small |
107 |
26.3 |
|
Medium |
311 |
206.2 |
|
Large |
612 |
773.8 |
|
Jumbo |
1,022 |
3,109.5 |
表 2.合成模型尺寸
每个合成模型使用一个或多个 DGX-A100-80GB 节点进行训练,全局数据batch大小为 65536 ,并使用 Adagrad 优化器。从表 3 中可以看出, NVIDIA Merlin Distributed-Embeddings 可以在数百个 GPU 上轻松训练 TB 级模型。
|
Model |
Training step time (ms) |
||||
|
1 GPU |
8 GPU |
16 GPU |
32 GPU |
128 GPU |
|
|
Tiny |
17.6 |
3.6 |
3.2 |
|
|
|
Small |
57.8 |
14.0 |
11.6 |
7.4 |
|
|
Medium |
|
64.4 |
44.9 |
31.1 |
17.2 |
|
Large |
|
|
|
65.0 |
33.4 |
|
Jumbo |
|
|
|
|
102.3 |
表 3.各种硬件配置下合成模型的训练步长时间( ms )
另一方面,与传统的数据并行相比,即使对于可以容纳在单个 GPU 中的模型,多GPU分布式模型并行仍然提供了显著加速。表 4 显示了上述Tiny模型在DGX A100-80GB 上的性能对比。
|
Solution |
Training step time (ms) |
|||
|
1 GPU |
2 GPU |
4 GPU |
8 GPU |
|
|
NVIDIA Merlin Distributed Embeddings Model Parallel |
17.7 |
11.6 |
6.4 |
4.2 |
|
Native TensorFlow Data Parallel |
19.9 |
20.2 |
21.2 |
22.3 |
表 4. Tiny模型( 4.2GiB )的训练步长时间( ms )比较 NVIDIA Merlin Distributed-Embeddings 模型并行和原生 TensorFlow 数据并行
本实验使用了 65536 的全局批量和 Adagrad 优化器。
结论
在这篇文章中,我们介绍了 NVIDIA Merlin Distributed-Embeddings,仅需几行代码即可在 NVIDIA GPU 上实现基于 embedding的深度学习模型,并进行可规模化,高效率地模型并行训练。欢迎尝试以下 使用合成数据的可扩展训练示例 和 基于 Criteo 数据训练 DLRM 模型 示例.




