NVIDIA TensorRT 的主要功能是加速深度学习推理,通过处理网络定义并将其转换为优化的引擎执行计划来实现。 TensorRT 发动机浏览器 ( TREx )是一个 Python 库和一组 Jupyter 笔记本,用于探索 TensorRT 引擎计划及其相关推理评测数据。
TREx 提供了对生成引擎的可视性,通过汇总统计数据、图表实用程序和引擎图可视化为您提供了新的见解。 TREx 对于高级网络性能优化和调试非常有用,例如比较网络两个版本的性能。对于深入的性能分析,建议使用 NVIDIA Nsight Systems 进行性能分析。
在这篇文章中,我总结了 TREx 的工作流程,并重点介绍了用于检查数据和 TensorRT 引擎的 API 特性。要查看 TREx 的实际情况,我将通过< insert action here >完成如何实现< value here >的过程。
TREx 的工作原理
TREx 的主要抽象是trex.EnginePlan,它封装了与引擎相关的所有信息。一个EnginePlan由几个输入 JSON 文件构成,每个文件描述引擎的不同方面,例如其数据依赖关系图和分析数据。EnginePlan中的信息可以通过 Pandas 数据框访问,这是一种熟悉、强大且方便的数据结构。
在使用 TREx 之前,必须构建并分析引擎。 TREx 提供了一个简单的实用程序脚本 process_engine.py 来实现这一点。该脚本作为参考提供,您可以选择任何方式收集此信息。
此脚本使用 trtexec 从 ONNX 模型构建引擎并分析引擎。它还创建了几个 JSON 文件,用于捕获引擎构建和分析会话的各个方面:
平面图 JSON 文件
计划图 JSON 文件以 JSON 格式描述引擎数据流图。
TensorRT 引擎计划是 TensorRT 引擎的序列化格式。它包含有关最终推理图的信息,可以反序列化以执行推理运行时。
TensorRT 8.2 引入了 IEngineInspector API ,它提供了检查引擎的层、层的配置及其数据依赖性的能力。IEngineInspector使用简单的 JSON 格式模式提供此信息。此 JSON 文件是 TREx trex.EnginePlan对象的主要输入,是必需的。
分析 JSON 文件
分析 JSON 文件为每个引擎层提供分析信息。
trtexec 命令行应用程序实现了 IProfiler 接口和 生成 JSON 文件,其中包含每个层的分析记录。如果您只想调查引擎的结构,而不需要相关的分析信息,则此文件是可选的。
计时记录 JSON 文件
JSON 文件包含每个分析迭代的计时记录。
要对引擎进行轮廓分析,trtexec多次执行引擎以平滑测量噪声。每个引擎执行的计时信息可以作为单独的记录记录在计时 JSON 文件中,平均测量值报告为引擎延迟。此文件是可选的,通常在评估分析会话的质量时非常有用。
如果您看到发动机正时信息变化过大,可能需要确保您只使用 GPU ,并且计算和内存时钟已锁定。
元数据 JSON 文件
元数据 JSON 文件描述了引擎的生成器配置以及用于构建引擎的 GPU 的相关信息。此信息为引擎分析会话提供了更有意义的上下文,在比较两个或多个引擎时尤其有用。
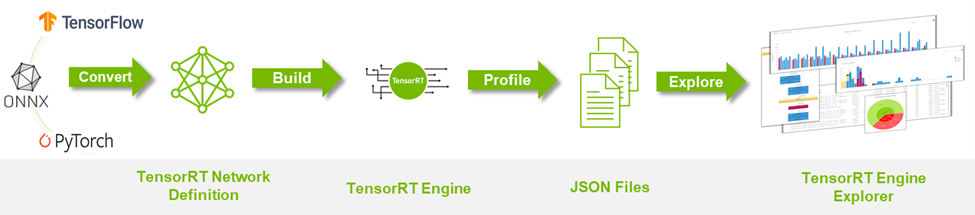
TREx 工作流
图 1 总结了 TREx 工作流:
- 首先,将您的深度学习模型转换为 TensorRT 网络。
- 构建和分析引擎,同时生成附带的 JSON 文件。
- 旋转 TREx 以浏览文件的内容。
TREx 功能和 API
收集所有分析数据后,可以创建一个EnginePlan实例:
plan = EnginePlan( "my-engine.graph.json", "my-engine.profile.json", "my-engine.profile.metadata.json")
对于trex.EnginePlan实例,您可以通过 pandas DataFrame 对象访问大部分信息。数据框中的每一行表示计划文件中的一个层,包括其名称、策略、输入、输出和描述该层的其他属性。
# Print layer names
plan = EnginePlan("my-engine.graph.json")
df = plan.df
print(df['Name'])
使用数据帧抽象引擎信息很方便,因为它既是许多 Python 开发人员都知道并喜欢的 API ,也是一种功能强大的 API ,具有数据切片、切割、导出、绘图和打印功能。
例如,列出引擎中三个最慢的层很简单:
# Print the 3 slowest layers
top3 = plan.df.nlargest(3, 'latency.pct_time')
for i in range(len(top3)): layer = top3.iloc[i] print("%s: %s" % (layer["Name"], layer["type"]))
features.16.conv.2.weight + QuantizeLinear_771 + Conv_775 + Add_777: Convolution
features.15.conv.2.weight + QuantizeLinear_722 + Conv_726 + Add_728: Convolution
features.12.conv.2.weight + QuantizeLinear_576 + Conv_580 + Add_582: Convolution
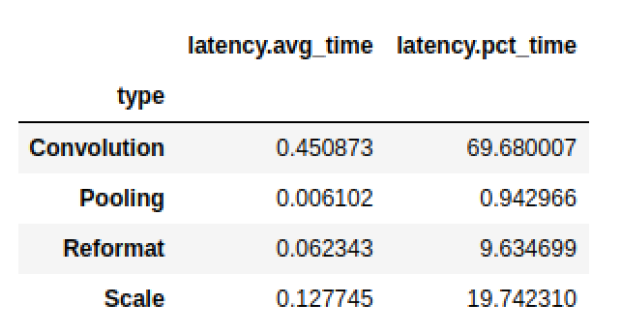
我们经常想把信息分组。例如,您可能想知道每种层类型消耗的总延迟:
# Print the latency of each layer type plan.df.groupby(["type"]).sum()[["latency.avg_time"]]
pandas 与其他库很好地结合,如用于查看和分析数据帧的方便库 dtale 和带有交互式绘图的图形库 Plotly 。这两个库都与示例 TREx 笔记本集成,但有许多用户友好的 备择方案 ,如 qgrid 、 matplotlib 和 Seaborn 。
还有一些方便的 API ,它们是 Pandas 、 Plotly 和 dtale 的薄包装:
- 打印数据(
plotting.py) - 可视化引擎图(
graphing.py) - 交互式笔记本(
interactive.py和notebook.py) - 报告(
report_card.py和compare_engines.py)
最后, linting API (lint.py)使用静态分析来标记性能危害,类似于软件 linter 。理想情况下,层过梁提供专家性能反馈,您可以根据这些反馈采取行动,以提高发动机的性能。例如,如果使用次优卷积输入形状或次优量化层放置。 linting 功能处于早期开发状态, NVIDIA 计划对其进行改进。
TREx 还附带了两个教程笔记本和两个工作流笔记本:一个用于分析单个引擎,另一个用于比较两个或多个引擎。
使用 TREx API ,您可以编写新的方法来探索、提取和显示 TensorRT 引擎,您可以与社区共享。
TREx 演练示例
现在您已经了解了 TREx 的操作方式,下面是一个显示 TREx 实际操作的示例。
在本例中,您创建了一个量化的优化 TensorRT 引擎 ResNet18 PyTorch ,对其进行分析,最后使用 TREx 检查发动机计划。]然后根据所学内容调整模型,以提高其性能。此示例的代码可在 TREx GitHub 存储库中找到。
首先,将 PyTorch ResNet 模型导出为 ONNX 格式。使用 NVIDIA PyTorch 量化工具包 用于在模型中添加量化层,但您不执行校准和微调,因为您关注的是性能,而不是准确性。
在实际用例中,您应该遵循完整的量化感知训练( QAT )方法。 QAT 工具包自动将假量化操作插入火炬模型。这些操作导出为 QuantizeLinear 和 DequantizeLinear ONNX 运算符:
import torch
import torchvision.models as models
# For QAT
from pytorch_quantization import quant_modules
quant_modules.initialize()
from pytorch_quantization import nn as quant_nn
quant_nn.TensorQuantizer.use_fb_fake_quant = True resnet = models.resnet18(pretrained=True).eval()
# Export to ONNX, with dynamic batch-size
with torch.no_grad(): input = torch.randn(1, 3, 224, 224) torch.onnx.export( resnet, input, "/tmp/resnet/resnet-qat.onnx", input_names=["input.1"], opset_version=13, dynamic_axes={"input.1": {0: "batch_size"}})=
接下来,使用 TREx 实用程序process_engine.py脚本执行以下操作:
- 从 ONNX 模型构建引擎。
- 创建引擎计划 JSON 文件。
- 分析引擎执行并将结果存储在分析 JSON 文件中。您还可以将计时结果记录在一个计时 JSON 文件中。
python3 <path-to-trex>/utils/process_engine.py /tmp/resnet/resnet-qat.onnx /tmp/resnet/qat int8 fp16 shapes=input.1:32x3x224x224
脚本process_engine.py使用trtexec来完成繁重的工作。您可以从process_engine.py命令行透明地将参数传递给trtexec,只需列出它们,而不需要--前缀。
在该示例中,参数int8、fp16和shapes=input.1:32x3x224x224被转发到trtexec,指示其优化 FP16 和 INT8 精度,并将输入批次大小设置为 32 。第一个脚本参数是输入 ONNX 文件(/tmp/resnet/resnet-qat.onnx),第二个参数(/tmp/resnet/qat)指向包含生成的 JSON 文件的目录。
现在,您已经准备好检查优化的引擎计划,所以请转到 TREx 引擎报告卡笔记本 。在这篇文章中,我不会浏览整个笔记本,只有几个单元格对这个例子有用。
第一个单元格设置引擎文件并创建 trex 。来自各种 JSON 文件的 EnginePlan 实例:
engine_name = "/tmp/resnet/qat/resnet-qat.onnx.engine"
plan = EnginePlan( f"{engine_name}.graph.json", f"{engine_name}.profile.json", f"{engine_name}.profile.metadata.json")
下一个单元格创建引擎数据依赖关系图的可视化,这对于理解原始网络到引擎的转换非常有用。 TensorRT 将引擎作为拓扑排序的层列表执行,而不是作为可并行化的图形执行。
默认呈现格式为 SVG ,可搜索,在不同比例下保持清晰,并支持悬停文本以提供附加信息,而不占用大量空间。
graph = to_dot(plan, layer_type_formatter) svg_name = render_dot(graph, engine_name, 'svg')
该函数创建一个 SVG 文件并打印其名称。即使对于小型网络,笔记本内部的渲染也很麻烦,您可以在单独的浏览器窗口中打开 SVG 文件进行渲染。
TREx graphing API 是可配置的,允许使用各种颜色和格式,并且可用的格式设置程序包含信息。例如,使用默认的格式化程序,层根据其操作进行着色,并按名称、类型和分析的延迟进行标记。张量被描述为连接各层的边,并根据其精度进行着色,并用其形状和内存布局信息进行标记。
在生成的 ResNet QAT 引擎图(图 3 )中,您可以看到一些 FP32 张量(红色)。进一步研究,因为您希望使用 INT8 precision 执行尽可能多的层。使用 INT8 数据和计算精度可以提高吞吐量,降低延迟和功耗。

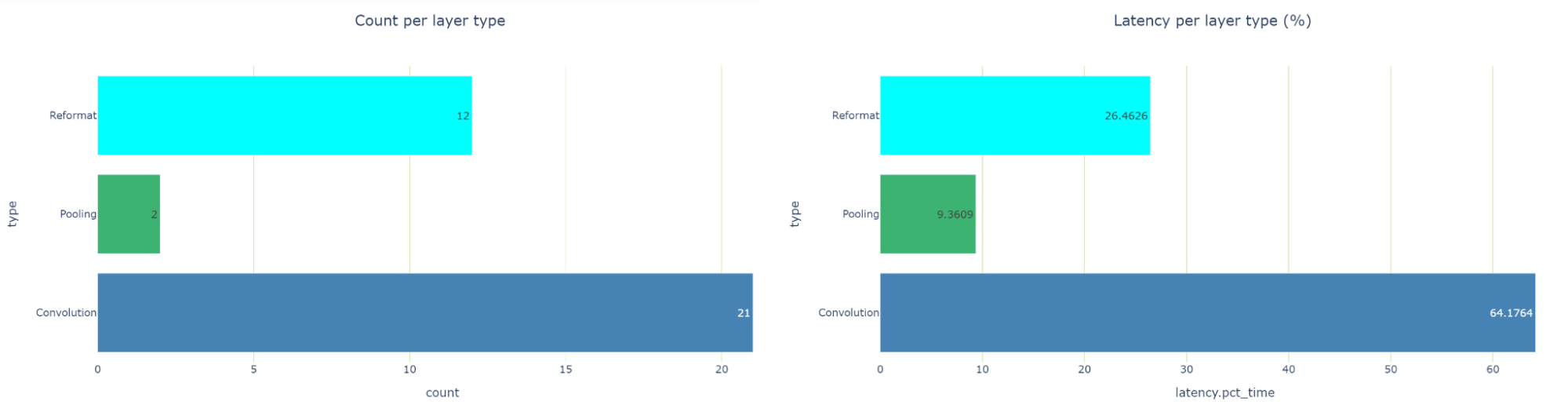
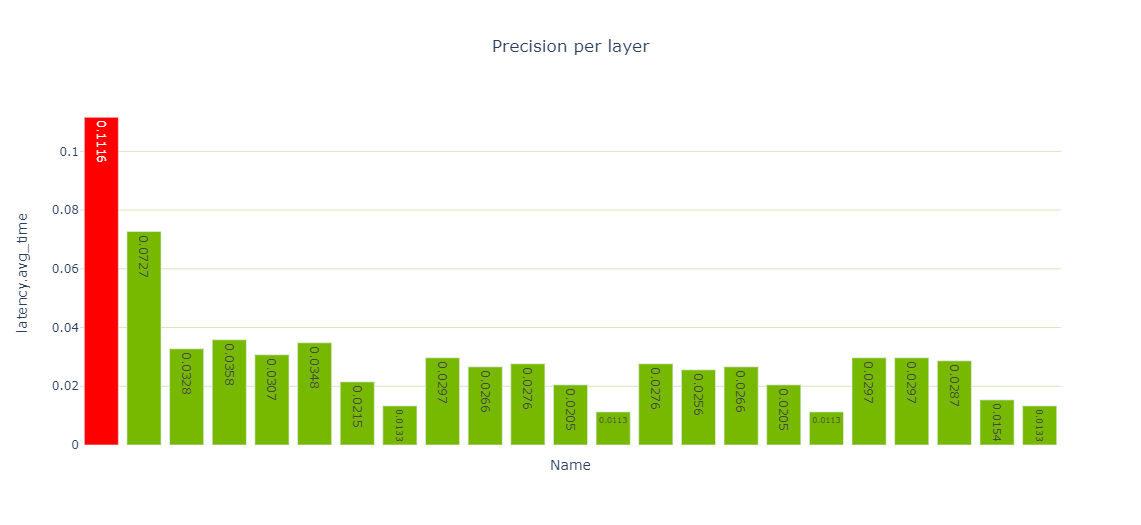
性能单元提供了各种性能数据视图,特别是每层精度视图(图 4 )显示了使用 FP32 和 FP16 计算的几个层。
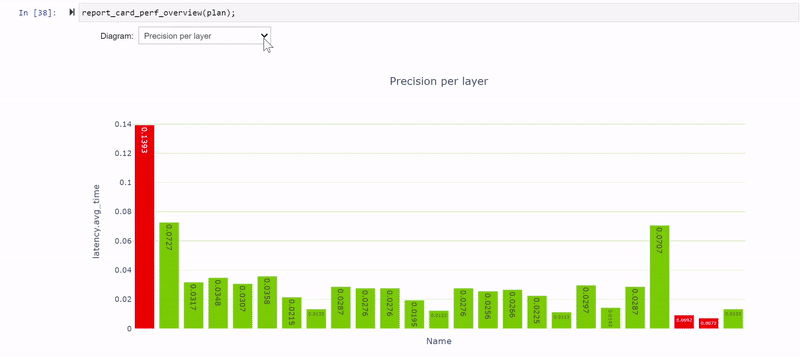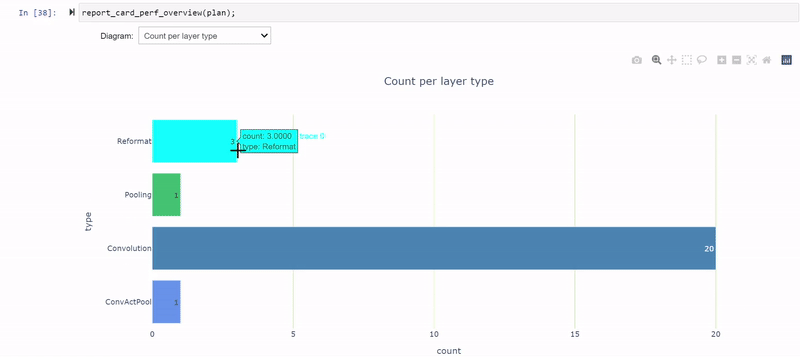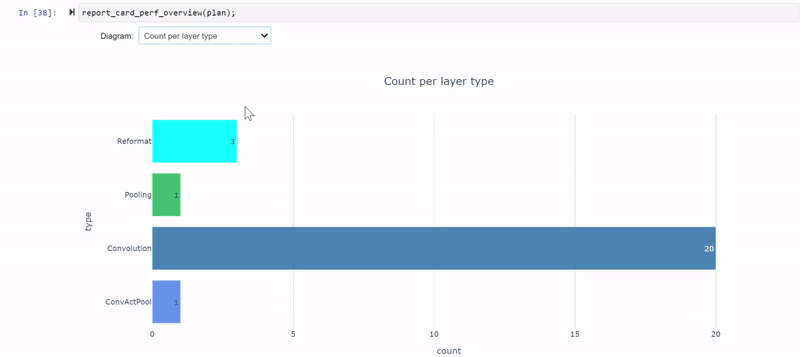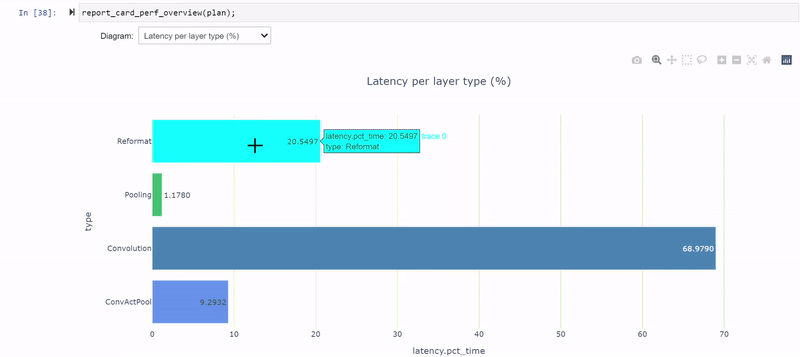
report_card_perf_overview(plan)
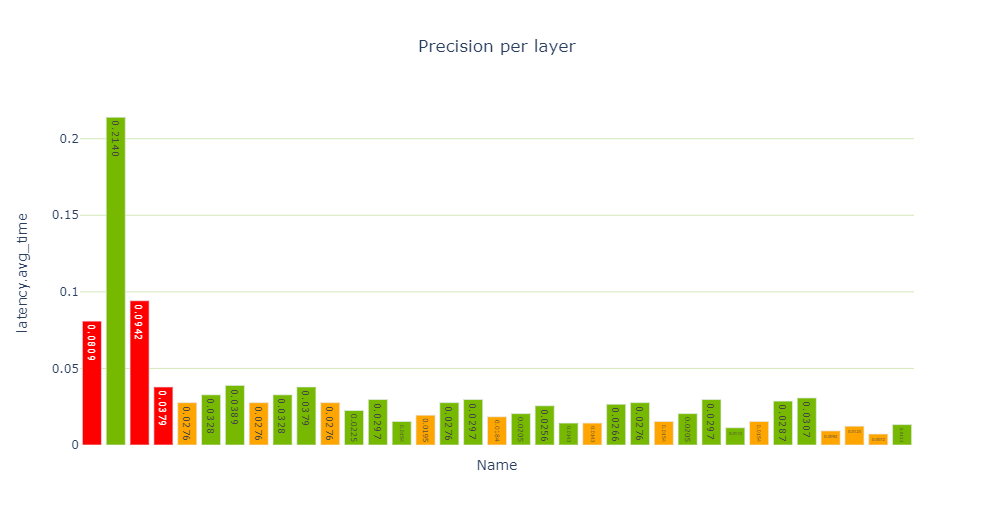
在检查每层类型的延迟视图时,共有 12 个重新格式化节点,约占运行时的 26.5% 。那是相当多的。在优化过程中,重新格式化节点会插入到引擎图中,但也会插入这些节点以转换精度。每个重新格式化层都有一个原点属性,描述其存在的原因。
如果您看到太多的精度转换,您应该看看是否可以做些什么来减少这些转换。在 TensorRT 8.2 中,您可以看到缩放图层,而不是为 Q / DQ 操作重新格式化图层。这是因为 TensorRT 8.2 和 8.4 中使用了不同的图形优化策略。
要想挖得更深,请转到衣料单元中可用的发动机衣料 API 。您可以看到,卷积和 Q / DQ 过滤机都标记了一些潜在的问题。
卷积 linter 标记 13 个具有 INT8 输入和 FP32 输出的卷积。理想情况下,如果卷积后面是 INT8 精度层,则希望卷积输出 INT8 数据。 linter 建议在卷积之后添加量化操作。为什么这些卷积的输出没有量化?
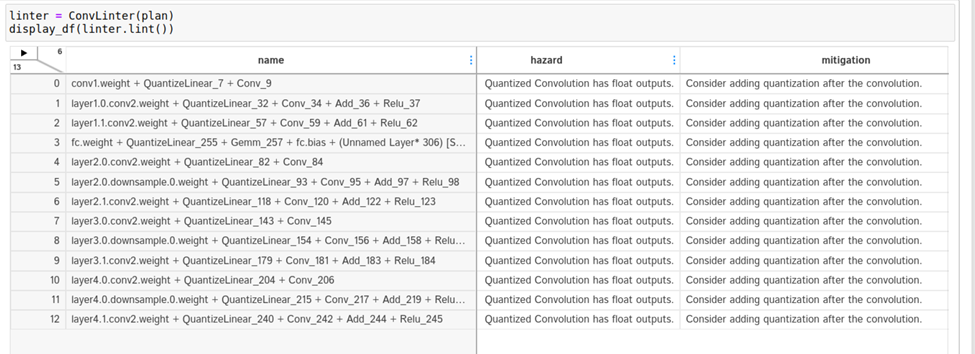
仔细看看。要在引擎图中查找卷积,请从 linter 表中复制卷积的名称,并在图形 SVG 浏览器选项卡中搜索它。结果表明,这些卷积涉及到残差加法运算。
在咨询了 Q / DQ 层铺设建议 之后,您可能会得出结论,您必须在 PyTorch 模型中的剩余连接中添加 Q / DQ 层。不幸的是, QAT 工具包无法自动执行此操作,您必须手动干预 PyTorch 模型代码。有关更多信息,请参阅 TensorRT QAT 工具包( resnet.py )中的示例。
下面的代码示例显示了BasicBlock.forward方法,新的量化代码以黄色突出显示。
def forward(self, x: Tensor) -> Tensor: identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample is not None: identity = self.downsample(x) if self._quantize: out += self.residual_quantizer(identity) else: out += identity out = self.relu(out) return out
更改 PyTorch 代码后,必须重新生成模型,并使用修改后的模型再次遍历笔记本单元格。现在,您可以减少到三个重新格式化层,它们消耗了大约 20.5% 的总延迟(从 26.5% 下降),并且大多数层现在都以 INT8 精度执行。
其余的 FP32 层围绕网络末端的全局平均池( GAP )层。再次修改模型以量化间隙层。
def _forward_impl(self, x: Tensor) -> Tensor: # See note [TorchScript super()] x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) if self._quantize_gap: x = self.gap_quantizer(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x
使用新模型在笔记本单元中进行最后一次迭代。现在只有一个重新格式化层,所有其他层都在 INT8 中执行。搞定了!
现在您已经完成了优化,可以使用 发动机比较笔记本 来比较这两个引擎。此笔记本不仅在您正在积极优化网络性能时有用,而且在以下情况下也有用:
- 当您想要比较为不同的 GPU HW 平台或不同的 TensorRT 版本构建的引擎时。
- 当您想要评估层的性能如何跨不同的批处理大小进行扩展时。
- 了解发动机之间的精度不一致是否是由于 TensorRT 层精度选择不同所致。
发动机比较笔记本提供了表格和图形视图来比较发动机,这两种视图都适用,具体取决于您需要的详细程度。图 8 显示了我们为 PyTorch ResNet18 模型构建的五个引擎的叠加延迟。为简洁起见,我没有讨论创建 FP32 和 FP16 引擎,但这些引擎可以在 TREx GitHub 存储库中找到。
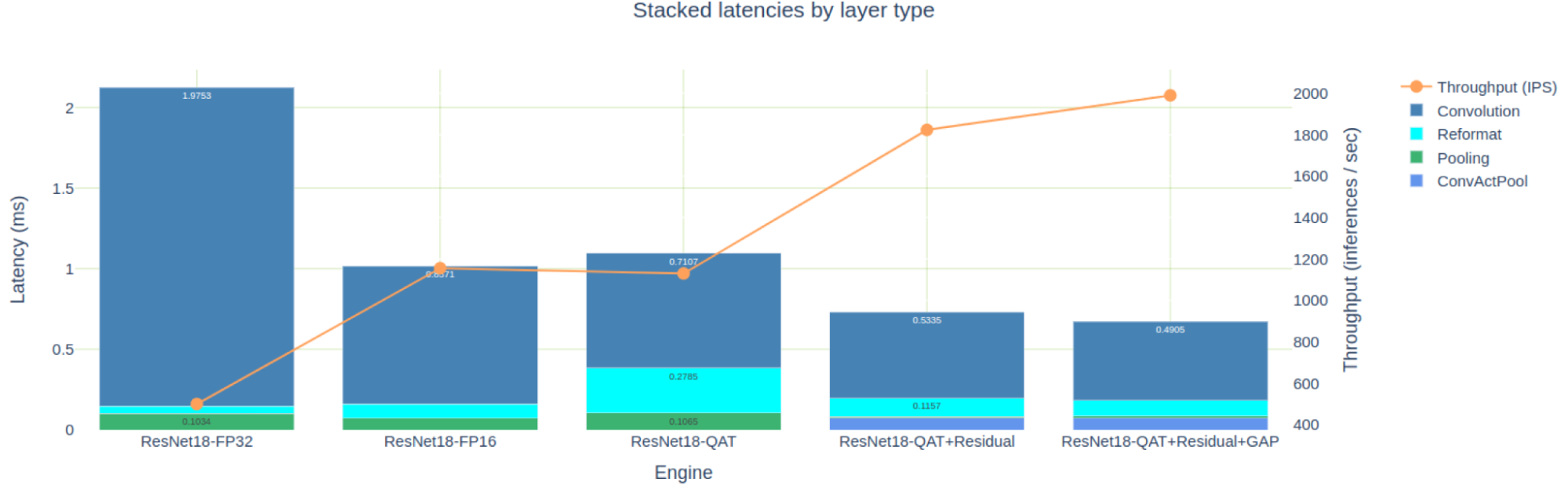
为 FP16 精度优化的引擎大约比 FP32 引擎快 2 倍,但也比我们首次尝试的 INT8 QAT 引擎快。如前所述,这是由于许多 INT8 卷积输出 FP16 数据,然后需要重新格式化层以显式量化回 INT8 。
如果您只关注本文中优化的三个 QAT 引擎,那么您可以看到,在向剩余连接添加 Q / DQ 时,您是如何消除 11 个 FP16 引擎层的。量化间隙层时,消除了另外两个 FP32 层。
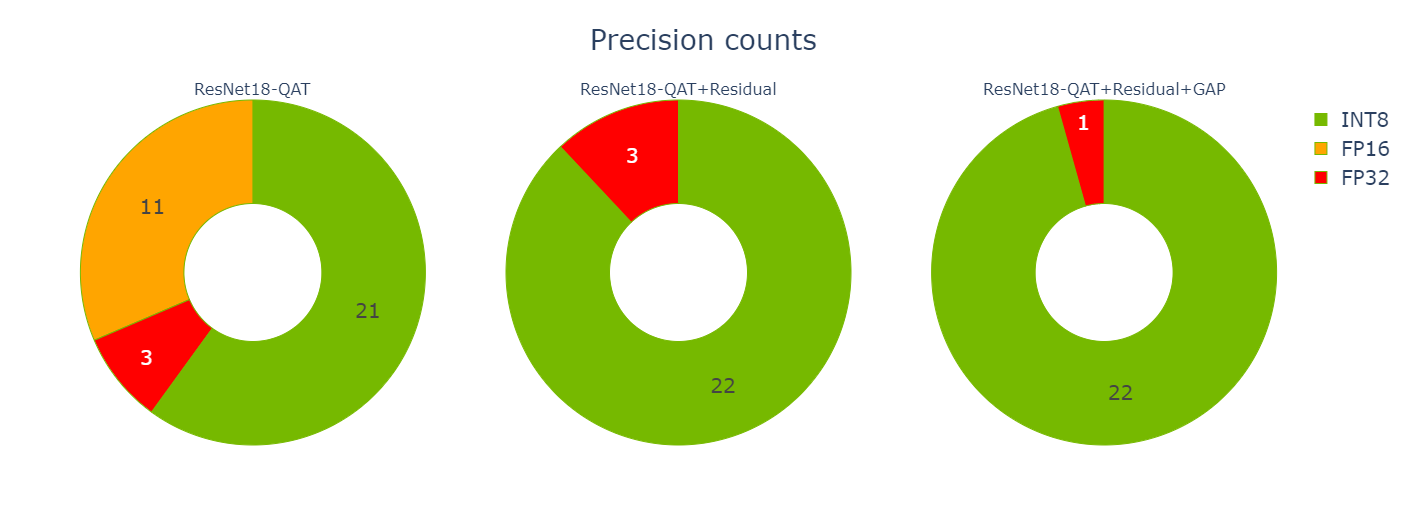
您还可以查看优化如何影响三个引擎的延迟(图 10 )。
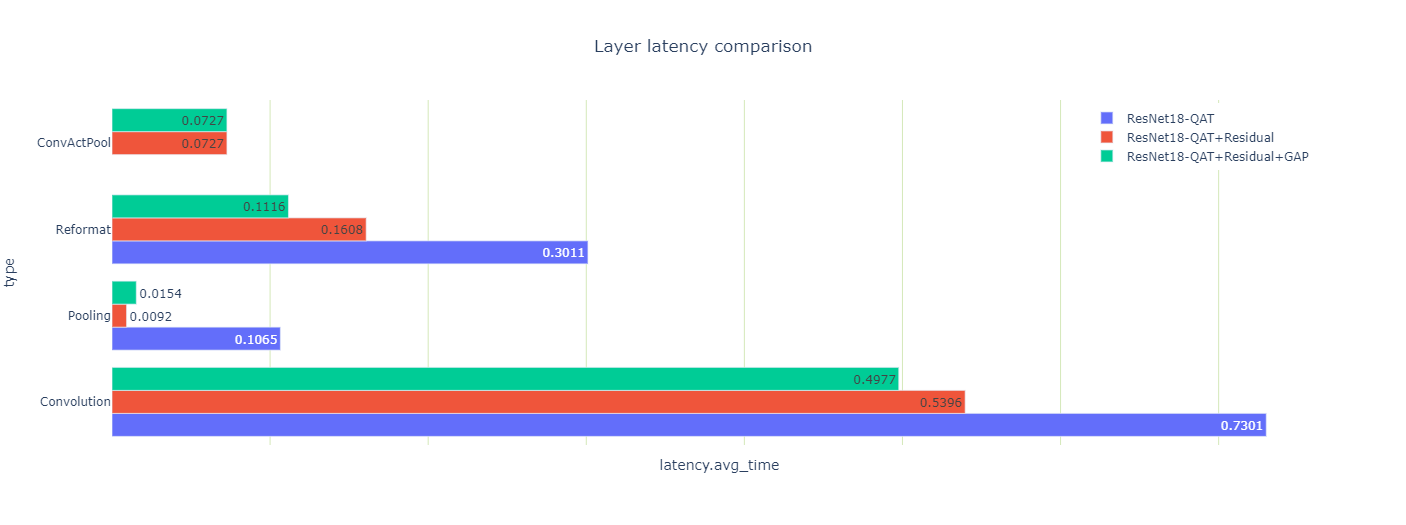
您可能会注意到一些看起来很奇怪的池层延迟结果:当您量化剩余连接时,总池延迟下降了 10 倍,然后当您量化间隙层时,总池延迟上升了 70% 。
这两个结果都是违反直觉的,所以请仔细观察它们。有两个池层,第一次卷积之后是一个大的池层,最后一次卷积之前是一个小的池层。量化剩余连接后,可以使用 INT8 精度的输出执行第一个池和卷积层。它们与夹在中间的 ReLU 融合到 ConfactPool 层中,但浮点类型不支持这种融合。
为什么间隙层在量化时延迟增加?这个层的激活大小很小,每个 INT8 输入系数都转换为 FP32 ,以便使用高精度进行平均。最后,将结果转换回 INT8 。
该层的数据大小也很小,并且驻留在快速二级缓存中,因此额外的精度转换计算相对昂贵。尽管如此,因为您可以去掉围绕间隙层的两个重新格式化层,所以总的引擎延迟(这是您真正关心的)会减少。
总结
在这篇文章中,我介绍了 TensorRT 引擎浏览器,简要回顾了它的 API 和特性,并通过一个示例演示了 TREx 如何帮助优化 TensorRT 引擎的性能。 TREx 可以在 TensorRT 的 GitHub 存储库中的 实验工具 目录下找到。
我鼓励您尝试 API ,并在两个工作流笔记本之外构建新的工作流。




