
对语音识别技术感兴趣?报名参加 NVIDIA 语音 AI 通讯 .
在过去十年中,人工智能支持的语音识别系统逐渐成为我们日常生活的一部分,从语音搜索到联络中心、汽车、医院和餐馆的虚拟助手。这些语音识别的发展得益于深度学习的进步。
许多行业的开发人员现在使用自动语音识别( ASR )来提高业务生产率、应用程序效率,甚至数字访问能力。继续阅读,了解更多关于 ASR 的信息,它是如何工作的,用例,进步等等。
什么是自动语音识别
语音识别技术能够将口语(音频信号)转换为通常用作命令的书面文本。
当今最先进的软件可以准确地处理各种语言方言和口音。例如, ASR 通常出现在面向用户的应用程序中,如虚拟代理、实时字幕和临床笔记。准确的语音转录对于这些用例至关重要。
语音 AI 领域的开发者也使用 替代术语 描述语音识别,如 ASR 、语音到文本( STT )和语音识别。
ASR 是系统的关键组成部分 语音 AI ,这是一套旨在帮助人类通过语音与计算机对话的技术。
为什么在语音识别中使用自然语言处理
开发人员通常不清楚自然语言处理( NLP )模型在 ASR 管道中的作用。除了应用于语言模型之外, NLP 还用于在 ASR 管道的末尾添加标点和大写字母来增强生成的转录本。
在用 NLP 对转录本进行后处理后,文本用于下游语言建模任务,包括:
- 情绪分析
- 文本分析
- 文本摘要
- 问答
语音识别算法
语音识别算法可以通过使用统计算法的传统方式实现,或者通过使用深度学习技术(如神经网络)将语音转换为文本。
传统的 ASR 算法
隐马尔可夫模型( HMM )和动态时间扭曲( DTW )是用于执行语音识别的传统统计技术的两个示例。
使用一组转录的音频样本,通过改变模型参数来训练 HMM 以预测单词序列,从而最大化观察到的音频序列的可能性。
DTW 是一种动态规划算法,通过计算时间序列之间的距离来寻找最佳可能的单词序列:一个代表未知语音,另一个代表已知单词。
深度学习 ASR 算法
在过去几年中,开发人员一直对语音识别的深度学习感兴趣,因为统计算法不太准确。事实上,深度学习算法能更好地理解方言、口音、上下文和多种语言,即使在嘈杂的环境中也能准确地转录。
一些最流行的最先进的语音识别声学模型有: Quartznet, Citrinet 和 Conformer 在典型的语音识别管道中,您可以根据您的用例和性能选择和切换任何声学模型。
深度学习模型的实现工具
有几种工具可用于开发深度学习语音识别模型和管道,包括: Kaldi Mozilla DeepSpeech , NVIDIA NeMo, Riva, TAO Toolkit ,以及来自谷歌、亚马逊和微软的服务。
Kaldi 、 DeepSpeech 和 NeMo 是帮助您构建语音识别模型的开源工具包。 TAO 工具包和 Riva 是封闭源代码 SDK ,可帮助您开发可在生产中部署的可定制管道。
谷歌、 AWS 和微软等云服务提供商提供通用服务,您可以轻松地即插即用。
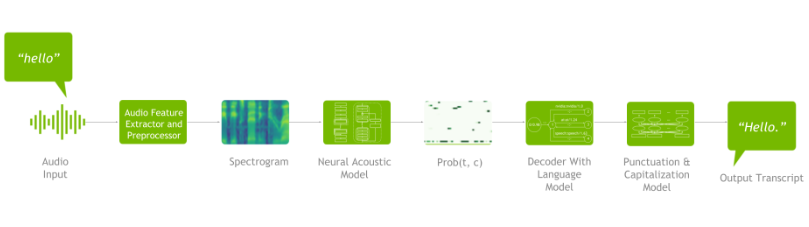
深度学习语音识别流水线
如图 1 所示, ASR 管道由以下组件组成:将原始音频转换为频谱图的频谱图生成器、将频谱图作为输入并输出随时间变化的字符概率矩阵的声学模型、从概率矩阵生成可能句子的解码器(可选地与语言模型耦合),最后,一种标点符号和大写模式,用于格式化生成的文本,以便于人类使用。
用于语音识别的典型深度学习管道包括:
- 数据预处理
- 神经声学模型
- 解码器(可选地与 n-gram 语言模型耦合)
- 标点和大写模式。
图 1 显示了深度学习语音识别管道的示例:
数据集在任何深度学习应用中都是必不可少的。神经网络的功能类似于人脑。你用来教授模型的数据越多,它学习的越多。语音识别管道也是如此。
一些流行的 语音识别数据集 是 LibriSpeech , Fisher 英语培训演讲, Mozilla 通用语音 ( MCV )、 VoxPopuli 、 2000 HUB 5 英语评估演讲、 AN4 (包括人们拼写地址和姓名的录音)和 Aisell-1 / Aisell-2 汉语语音语料库。除了您自己的专有数据集之外,还可以使用一些开源数据集。
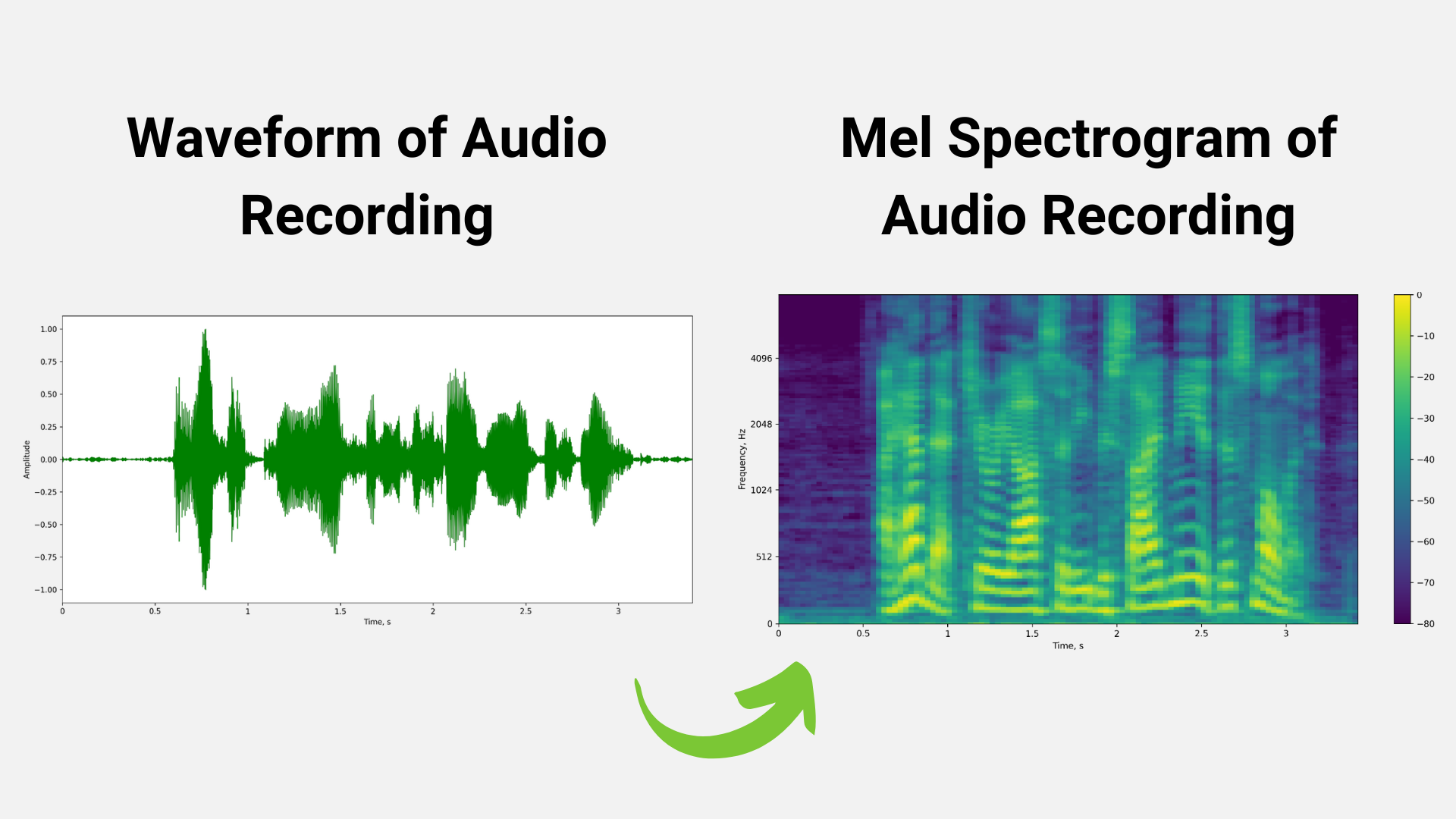
数据处理是第一步。它包括数据预处理/增强技术,如速度/时间/噪声/脉冲扰动和时间拉伸增强、使用窗口的快速傅立叶变换( FFT )和归一化技术。
例如,在下图 2 中,使用加窗技术应用 FFT 后,从原始音频波形生成 mel 谱图。
我们还可以使用扰动技术来扩充训练数据集。图 3 和图 4 显示了噪声扰动和掩蔽等技术,用于增加训练数据集的大小,以避免过拟合等问题。
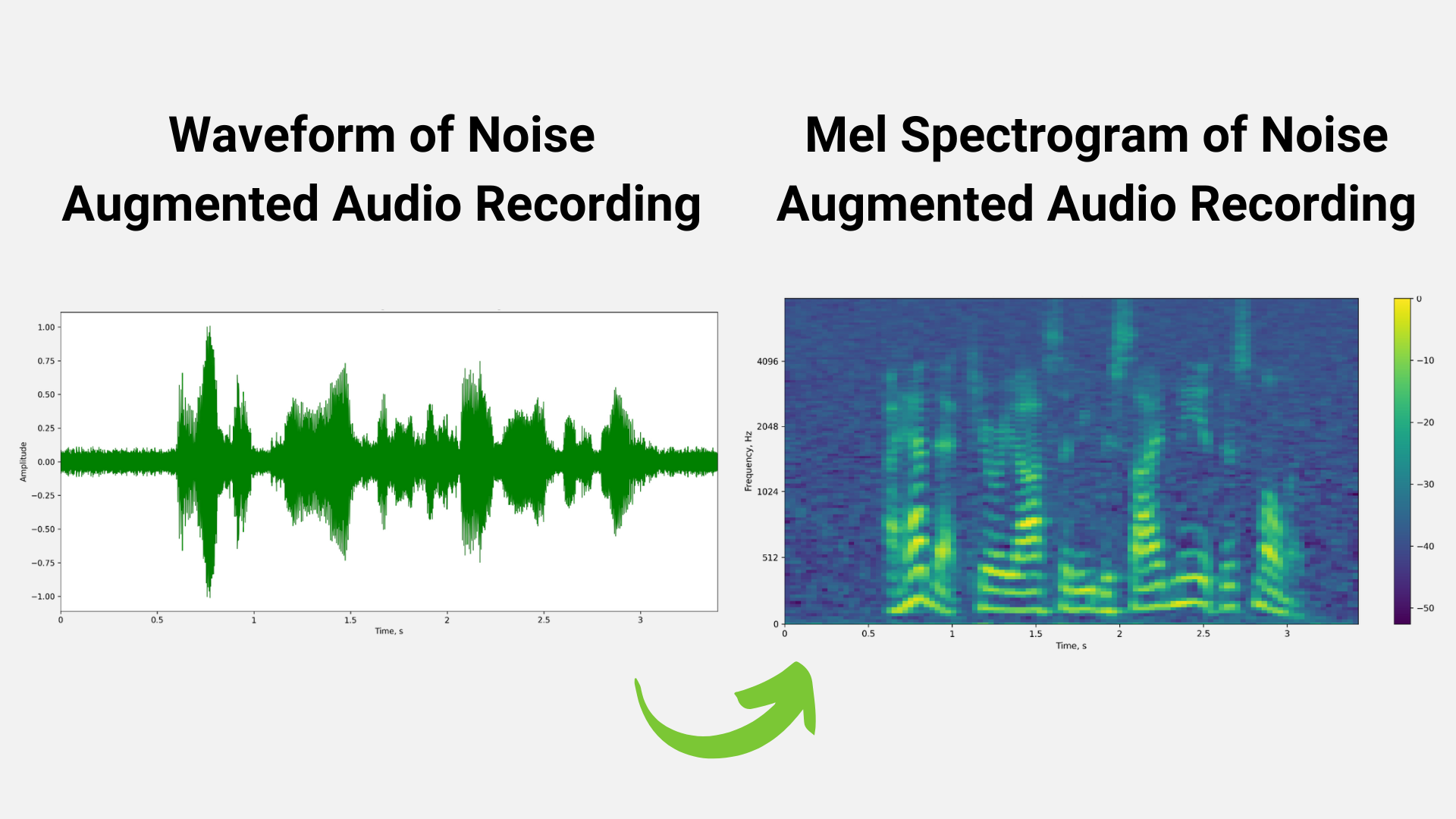
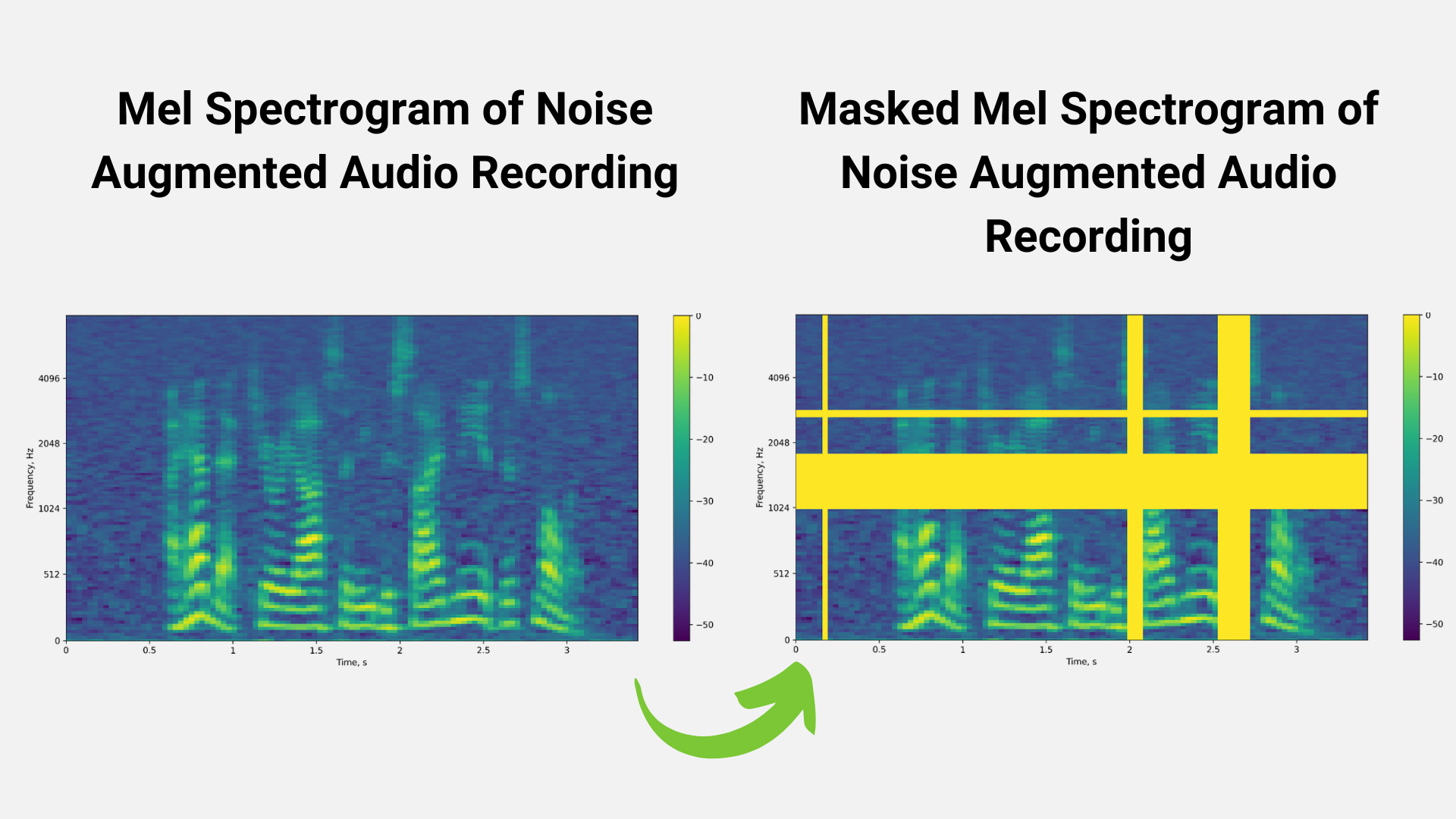
数据预处理阶段的输出是频谱图/ mel 频谱图,它是音频信号强度随时间变化的视觉表示。
然后将 Mel 光谱图送入下一阶段: 神经声学模型 QuartzNet 、 CitriNet 、 ContextNet 、 Conformer CTC 和 Conformer-Transducer 是尖端神经声学模型的示例。存在多个 ASR 模型有几个原因,例如需要实时性能、更高的精度、内存大小和用例的计算成本。
然而,基于构象的模型由于其提高的准确性和理解能力而变得越来越流行。声学模型返回每个时间戳的字符/单词概率。
图 5 显示了声学模型的输出,带有时间戳。
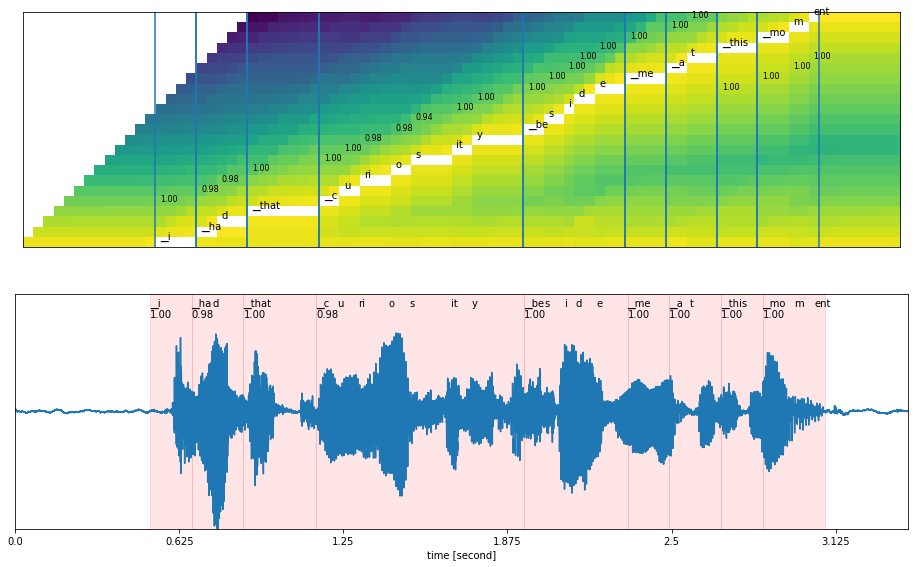
声学模型的输出与语言模型一起输入解码器。解码器包括波束搜索和贪婪解码器,语言模型包括 n-gram 语言、 KenLM 和神经评分。当涉及到解码器时,它有助于生成顶部单词,然后将其传递给语言模型以预测正确的句子。
在下图中,解码器根据概率得分选择下一个最佳单词。根据最终的最高分数,选择正确的单词或句子,并将其发送到标点符号和大小写模型。
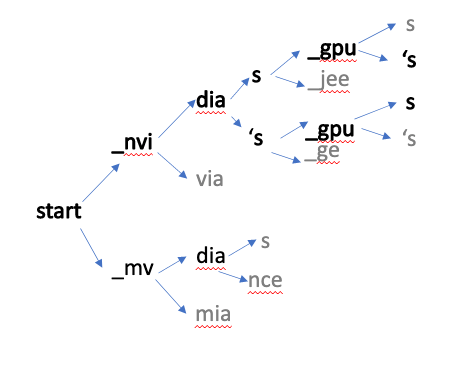
ASR 管道生成没有标点或大写的文本。
最后,使用标点符号和大写字母模型来提高文本质量,以提高可读性。来自变换器( BERT )模型的双向编码器表示通常用于生成标点文本。
图 7 展示了标点符号前后和大小写模型的一个简单示例:

语音识别行业影响
语音识别可以帮助金融、电信和统一通信即服务( UCaaS )等行业改善客户体验、运营效率和投资回报率( ROI )。
视频 1.语音 AI 如何改变客户参与度
金融
语音识别应用于金融行业,例如: 呼叫中心代理协助 和交易记录。 ASR 用于转录客户与呼叫中心代理/交易大厅代理之间的对话。然后可以分析生成的转录,并将其用于向代理提供实时建议。这将使通话后时间减少 80% 。
此外,生成的转录本用于下游任务,包括:
- 情绪分析
- 文本摘要
- 问答
- 意图和实体识别
电信
联络中心是电信行业的重要组成部分。通过呼叫中心技术,您可以重新想象电信客户中心,语音识别可以帮助您实现这一点。正如前面在财务呼叫中心用例中所讨论的, ASR 用于电信联络中心转录客户和联络中心代理之间的对话,以便实时分析客户和推荐呼叫中心代理。 T-Mobile 使用 ASR 快速解决客户问题 例如
统一通信及时服务( UCaaS )
新冠肺炎增加了对统一通信即服务( UCaaS )解决方案的需求,该领域的供应商开始专注于使用语音人工智能技术,如 ASR ,以创造更具吸引力的会议体验。
例如, ASR 可用于生成 视频会议中的实时字幕。 然后,生成的标题可用于后续任务,如会议摘要和识别笔记中的行动项目。
ASR 技术的未来
语音识别并不像听起来那么容易。开发语音识别充满了挑战,从准确性到用例定制,再到实时性能。另一方面,企业和学术机构正在竞相克服其中一些挑战,并推进语音识别能力的使用。
ASR 挑战
在生产中开发和部署语音识别管道的一些挑战包括:
- 由于缺乏提供最先进( SOTA ) ASR 模型的工具和 SDK ,开发人员很难利用最好的语音识别技术。
- 有限的自定义功能,使开发人员能够微调特定于域和上下文的行话、多种语言、方言和口音,以便让您的应用程序像您一样理解和说话
- 限制部署支持;例如,根据用例的不同,软件应该能够部署在任何云中、 prem 、 edge 和嵌入式上。
- 实时语音识别流水线;例如,在呼叫中心代理辅助用例中,在使用会话授权代理之前,我们不能等待几秒钟才能转录会话。
ASR 进展
语音识别在研究和软件开发方面都取得了许多进展。首先,研究结果开发了几种新的尖端 ASR 体系结构、 E2E 语音识别模型和自监督或无监督训练技术。
在软件方面,有一些工具可以快速访问 SOTA 模型,还有一些不同的工具可以将模型部署为生产中的服务。
关键要点
由于语音识别在基于深度学习的算法方面的进步,语音识别的采用率持续增长,这使得语音识别与人类识别一样准确。此外,多语言 ASR 等突破有助于公司在全球范围内提供应用程序,将算法从云端移动到设备上可以节省资金、保护隐私并加快推理速度。
NVIDIA 提供 Riva ,一个语音 AI SDK ,以解决上面讨论的几个挑战。通过 Riva ,您可以快速访问为生产目的量身定制的最新 SOTA 研究模型。您可以根据您的领域和用例自定义这些模型,在任何云上、 prem 上、 edge 上或嵌入式上部署,并实时运行它们以进行自然交互。
通过免费电子书了解您的组织如何从语音识别技能中受益, 构建语音 AI 应用程序。




