
说话人日记化是按说话人标签对录音进行分段的过程,旨在回答“谁在何时发言?”。与语音识别相比,它有着明显的区别。
在你执行说话人日记化之前,你知道“说的是什么”,但你不知道“谁说的”。因此,说话人日记化是语音识别系统的一个基本特征,它可以用说话人标签丰富转录内容。也就是说,如果没有说话人日记化过程,会话录音永远不能被视为完全转录,因为没有说话者标签的转录无法通知您是谁在和谁说话。
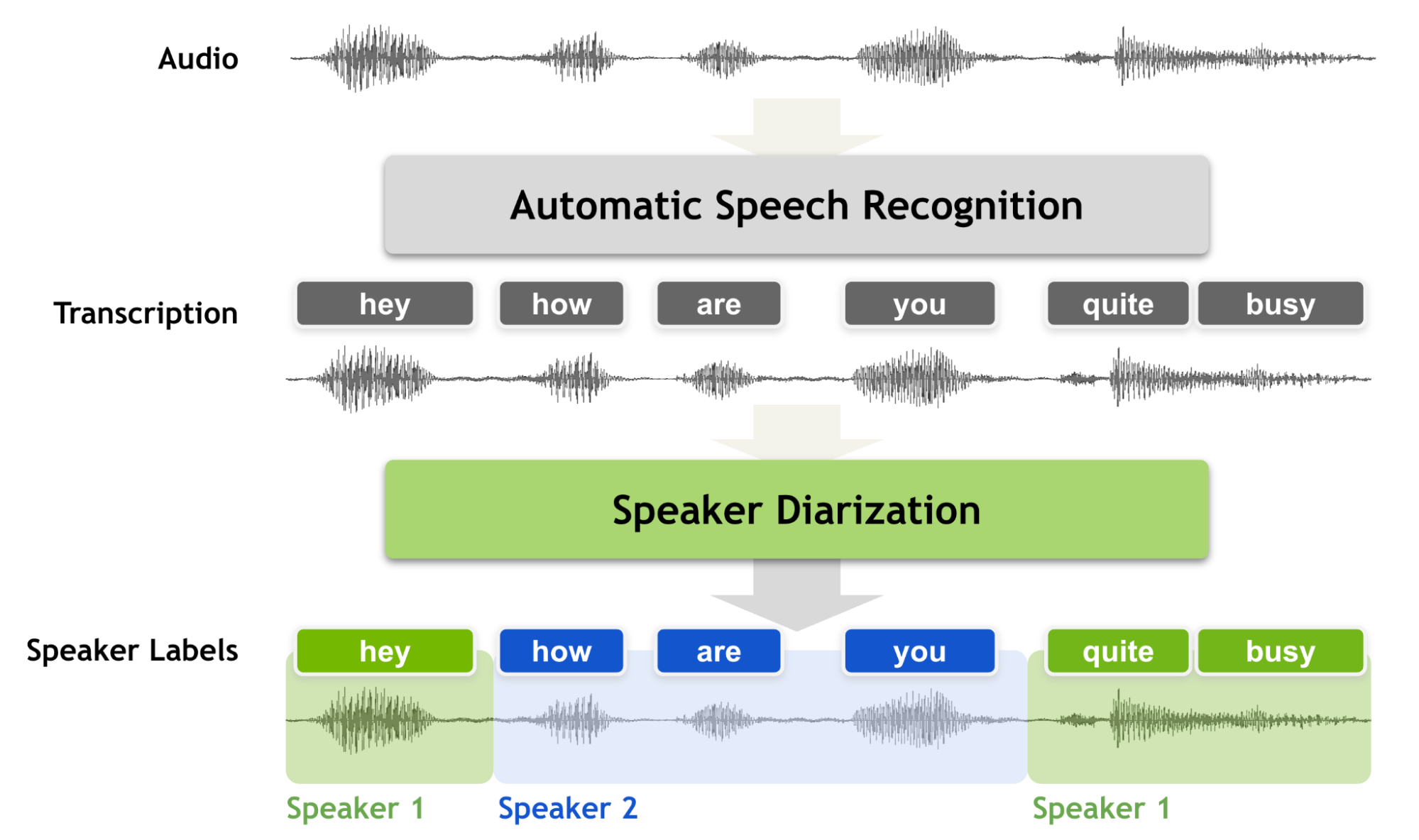
说话人日记必须产生准确的时间戳,因为在会话设置中,说话人的话轮数可能非常短。我们经常使用短的反向通道词,如“ yes ”、“ uh huh ”或“ oh ”。这些词对机器转录和识别说话人来说很有挑战性。
虽然根据说话人身份对音频记录进行分段,但说话人日记化需要对相对较短的分段进行细粒度决策,从十分之几秒到几秒不等。对如此短的音频片段做出准确、细粒度的决策是一项挑战,因为它不太可能捕捉到可靠的说话人特征。
在本文中,我们讨论了如何通过引入一种称为多尺度方法和多尺度二值化解码器( MSDD )的新技术来处理多尺度输入来解决这个问题。
多尺度分割机制
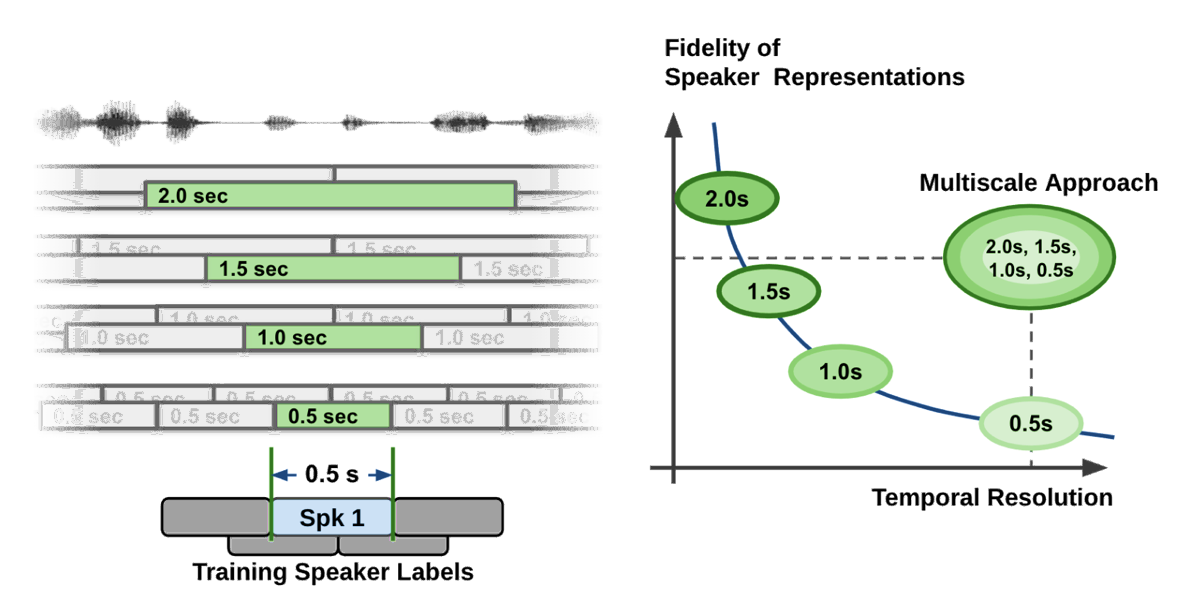
就扬声器特征的质量而言,提取长音频段是可取的。然而,音频段的长度也限制了粒度,这导致扬声器标签决策的单位长度较粗。如图 2 所示的曲线所示,说话人区分系统面临着时间分辨率和说话人表示保真度之间的权衡问题。
在说话人区分流水线中的说话人特征提取过程中,为了获得高质量的说话者表示向量,不可避免地要花费较长的语音段来牺牲时间分辨率。在简单明了的语言中,如果你试图准确掌握语音特征,那么你必须考虑更长的时间跨度。
同时,如果你考虑更长的时间跨度,你必须在相当长的时间跨度内做出决定。这会导致粗决策(时间分辨率低)。想想这样一个事实,如果只录下半秒钟的讲话,即使是人类听众也无法准确地说出谁在讲话。
在大多数分音系统中,音频段长度在 1.5 到 3.0 秒之间,因为这样的数字在扬声器特性的质量和时间分辨率之间取得了很好的折衷。这种分割方法称为 single-scale approach 。
即使使用重叠技术,单尺度分割也将时间分辨率限制在 0.75 ~ 1.5 秒,这在时间精度方面留下了改进的空间。
粗略的时间分辨率不仅会降低二值化的性能,而且会降低说话人计数的准确性,因为短语音片段无法正确捕获。 更重要的是,说话人时间戳中的这种粗时间分辨率使得解码后的 ASR 文本与说话人区分结果之间的匹配更容易出错。
为了解决这个问题,我们提出了一种多尺度方法,这是一种通过从多段长度中提取说话人特征,然后将多尺度的结果结合起来来处理这种权衡的方法。多尺度技术在最流行的说话人方言化基准数据集上实现了最先进的精度。它已经是开源会话 AI 工具包 NVIDIA NeMo 的一部分。
图 2 显示了多尺度扬声器分辨率的关键技术解决方案。
多尺度方法通过使用多尺度分割和从每个尺度提取说话人嵌入来实现。在图 2 的左侧,在多尺度分割方法中执行了四种不同的尺度。
在段关联性计算过程中,将合并从最长刻度到最短刻度的所有信息,但只对最短的段范围作出决策。当组合每个音阶的特征时,每个音阶权重在很大程度上影响说话人的区分性能。
基于神经模型的多尺度分解流水线
由于刻度权重在很大程度上决定了说话人区分系统的准确性,因此应设置刻度权重以使说话人的区分性能达到最大。
我们提出了一种称为 multiscale diarization decoder ( MSDD )的新型多尺度二值化系统,该系统在每个时间步长动态确定每个尺度的重要性。
说话人日记系统依赖于被称为说话人嵌入的音频特征向量捕获的说话人特征。通过神经模型提取说话人嵌入向量,从给定的音频信号中生成稠密浮点数向量。
MSDD 从多个尺度中提取多个说话人嵌入向量,然后估计所需的尺度权重。基于估计的音阶权重,生成扬声器标签。如果输入信号被认为在某些尺度上具有更准确的信息,则所提出的系统在大尺度上的权重更大。
图 3 显示了提议的多尺度说话人分离系统的数据流。从音频输入中提取多尺度分段,并使用扬声器嵌入提取器( TitaNet )生成用于多尺度音频输入的相应扬声器嵌入向量。
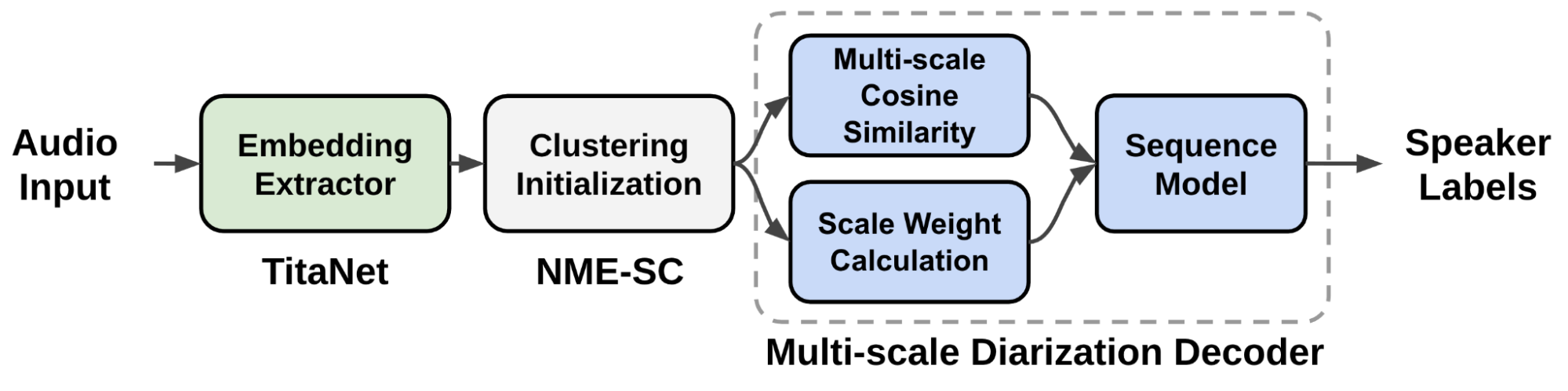
提取的多尺度嵌入通过聚类算法进行处理,以向 MSDD 模块提供初始化聚类结果。 MSDD 模块使用簇平均说话人嵌入向量与输入说话人嵌入式序列进行比较。估计每个步骤的磅秤权重,以衡量每个磅秤的重要性。
最后,训练序列模型输出每个说话人的说话人标签概率。
MSDD 机制
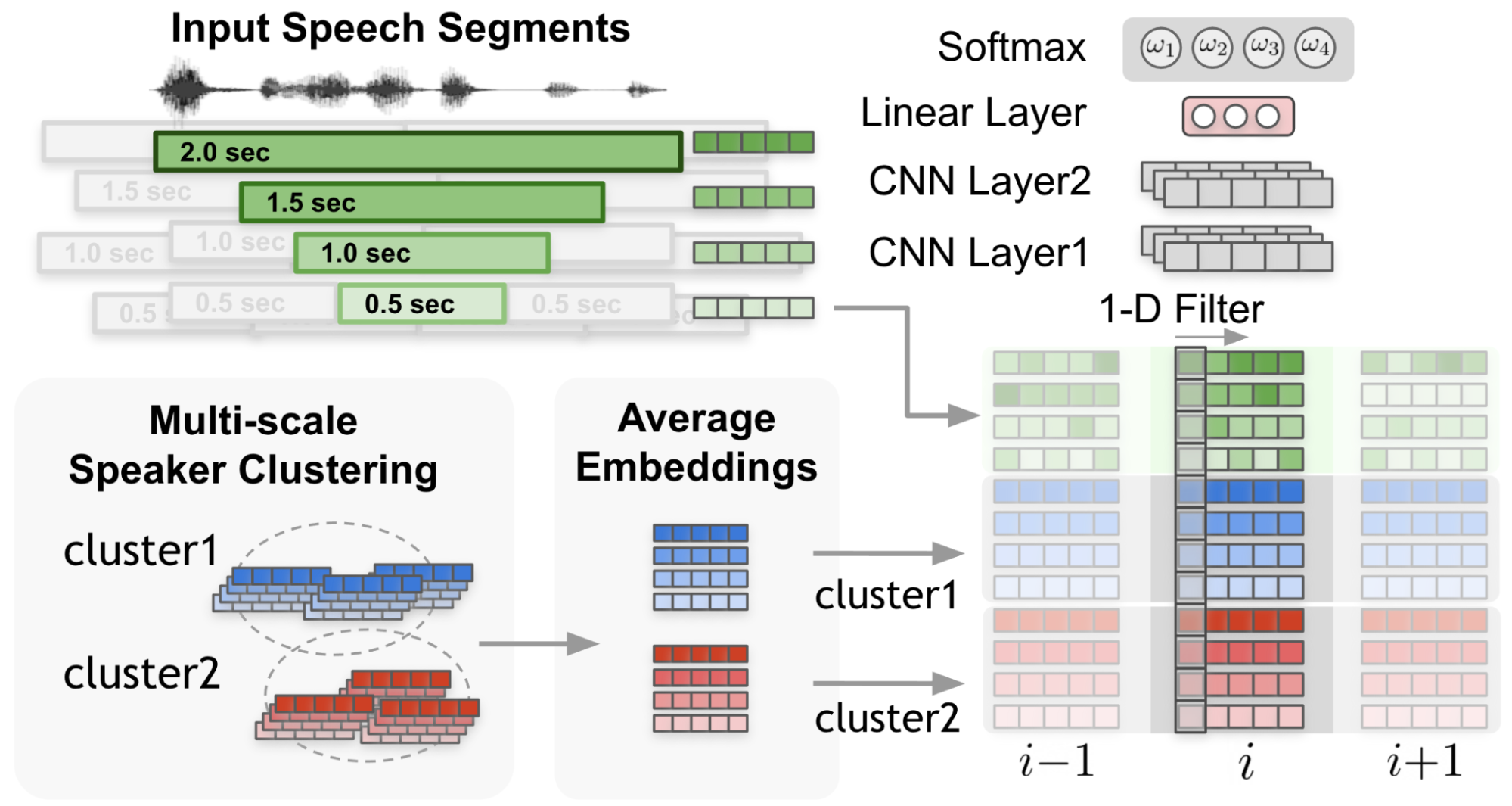
在图 4 中, 1-D 滤波器 从输入嵌入和集群平均嵌入捕获上下文。
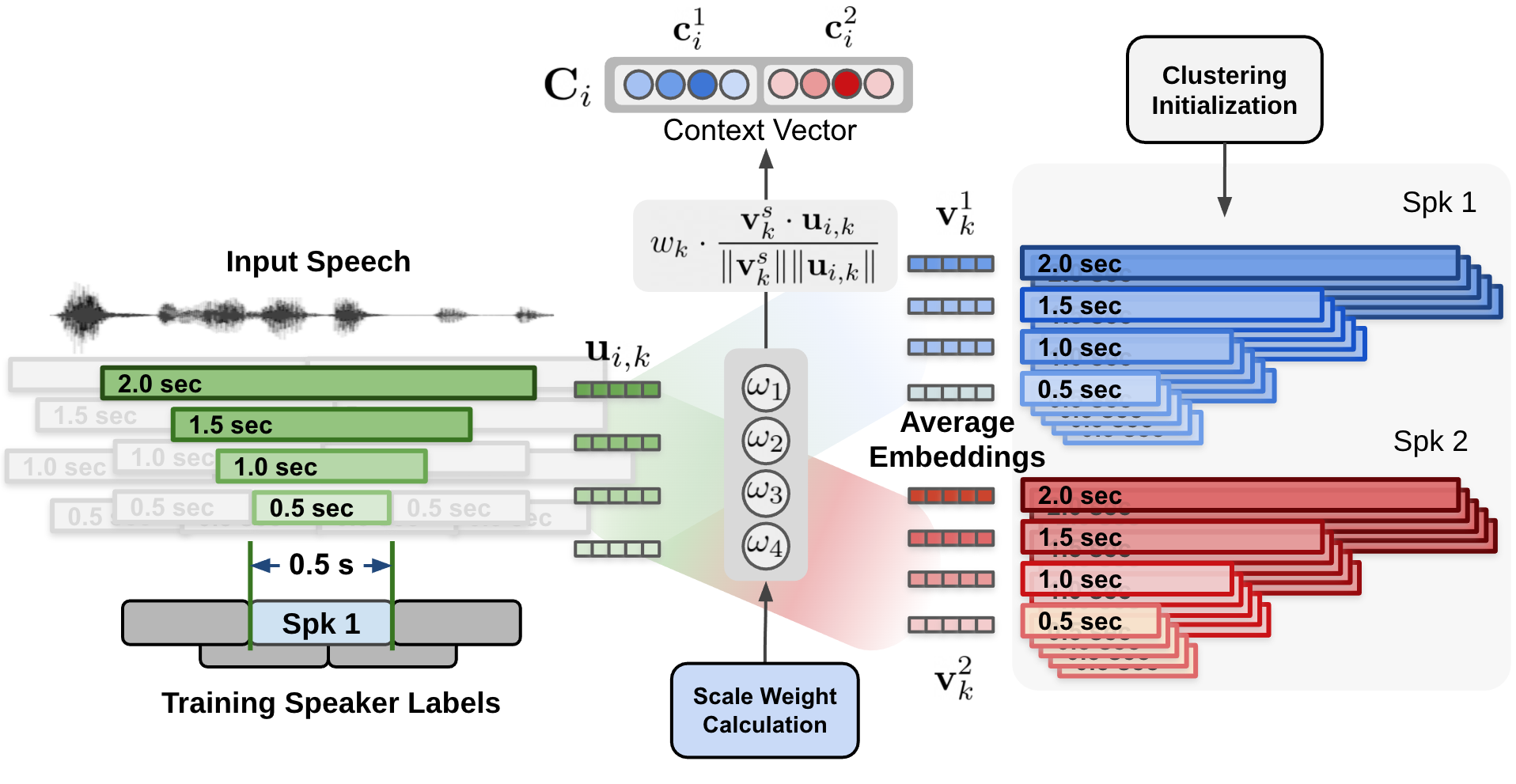
在图 5 中,每个说话人和每个尺度的余弦相似性值由尺度权重加权,形成加权余弦相似向量。
通过动态计算每个尺度的权重,训练神经网络模型 MSDD 以利用多尺度方法。 MSDD 获取初始聚类结果,并将提取的说话人嵌入与聚类平均说话人表示向量进行比较。
最重要的是,每个时间步长的每个尺度的权重是通过尺度权重机制确定的,其中尺度权重是通过应用于多尺度说话人嵌入输入和簇平均嵌入的一维卷积神经网络( CNN )计算得出的(图 3 )。
估计的尺度权重应用于为每个说话人和每个尺度计算的余弦相似值。图 5 显示了通过对集群平均说话人嵌入和输入说话人嵌入式之间计算出的余弦相似性(图 4 )应用估计的比例权重来计算上下文向量的过程。
最后,每个步骤的每个上下文向量都被送入一个多层 LSTM 模型,该模型生成每个说话人的说话人存在概率。图 6 显示了 LSTM 模型和上下文向量输入如何估计说话人标签序列。
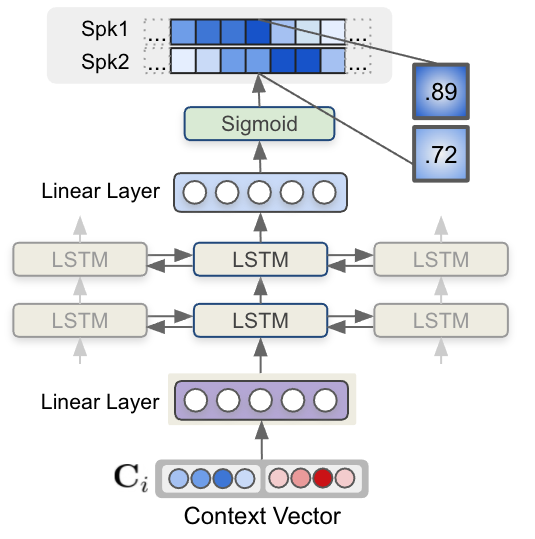
图 6 ,使用 LSTM 的序列建模接受上下文向量输入并生成说话人标签。 MSDD 的输出是两个说话人在每个时间步存在说话人的概率值。
拟议的说话人日记系统旨在支持以下功能:
- 扬声器数量灵活
- 重叠感知区分
- 预训练说话人嵌入模型
扬声器数量灵活
MSDD 使用两两推理来记录与任意数量说话人的对话。例如,如果有四个说话人,则提取六对,并对 MSDD 的推理结果进行平均,以获得四个说话人中每个人的结果。
重叠感知区分
MSDD 独立估计每个步骤中两个扬声器的两个扬声器标签的概率(图 6 )。这可以在两个扬声器同时讲话的情况下进行重叠检测。
预训练说话人嵌入模型
MSDD 基于预处理嵌入提取器( TitaNet )模型。通过使用预处理说话人模型,可以使用从相对大量的单说话人语音数据中学习的神经网络权重。
此外, MSDD 设计为使用经过预处理的说话人进行优化,以在特定领域的说话者日记数据集上微调整个说话人日记系统。
实验结果和定量效益
提出的 MSDD 系统有几个定量优势:卓越的时间分辨率和提高的准确性。
卓越的时间分辨率
虽然单尺度聚类分解器在 1.5 秒的分段长度上表现出最佳性能,其中单位决策长度为 0.75 秒(半重叠),但提议的多尺度方法的单位决策长度是 0.25 秒。通过使用需要更多步骤和资源的更短移位长度,可以进一步提高时间分辨率。
图 2 显示了多尺度方法的概念和 0.5 秒的单位决策长度。由于扬声器功能的保真度降低,仅将 0.5 秒的片段长度应用于单刻度分划器会显著降低分划性能。
提高准确性
通过比较假设时间戳和地面真值时间戳来计算重化错误率( DER )。图 7 显示了多尺度二值化方法相对于最先进的单尺度聚类方法的量化性能。
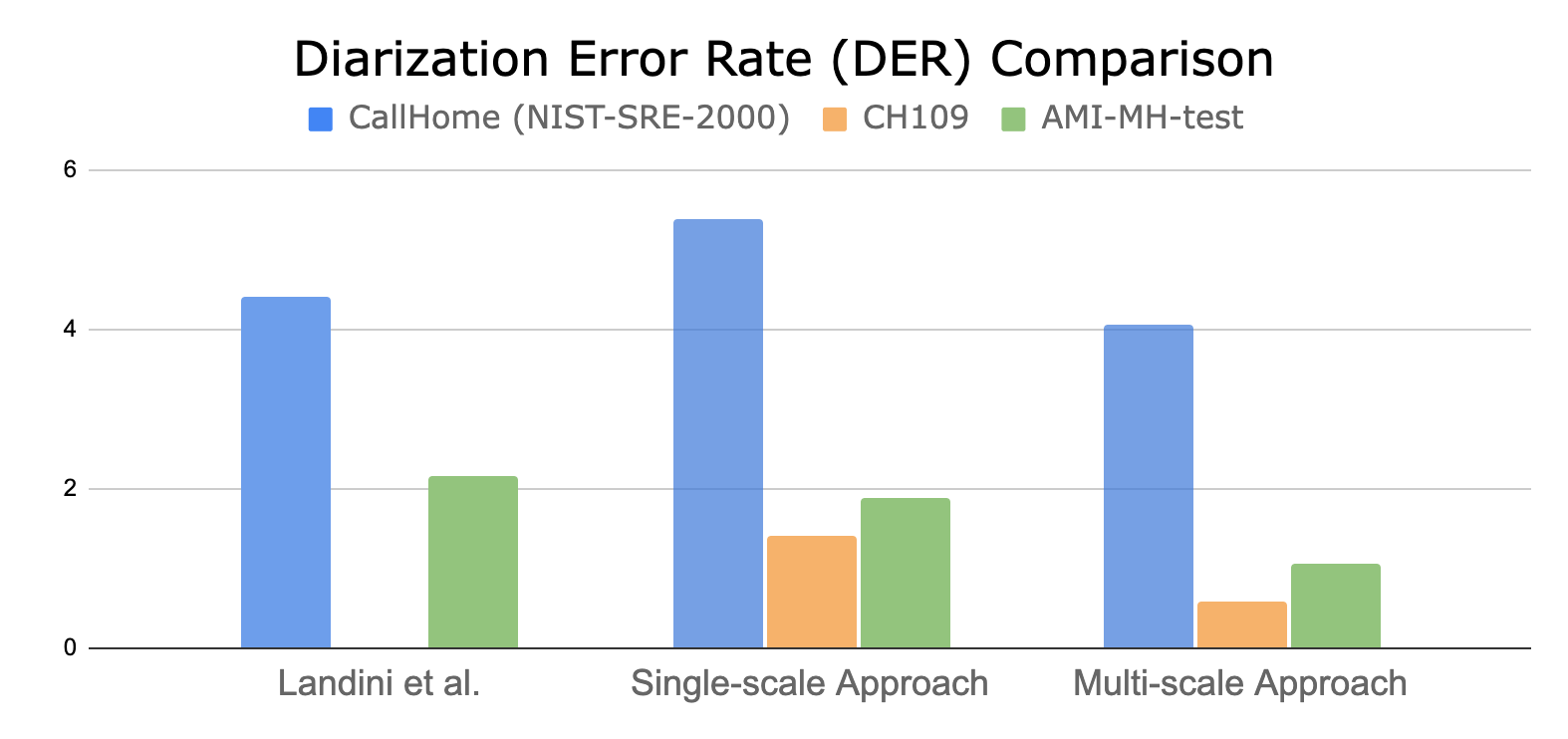
与单尺度聚类日记器相比,所提出的 MSDD 方法可以在两个说话人数据集上减少多达 60% 的 DER 。
结论
拟议系统具有以下优点:
- 这是第一个应用多尺度加权概念和基于序列模型( LSTM )的说话人标签估计的神经网络架构。
- 加权方案集成在单个推理会话中,不需要像其他说话人日记化系统那样融合多个日记化结果。
- 提出的多尺度分解系统能够实现重叠感知的分解,这是传统基于聚类的分解系统无法实现的。
- 因为解码器基于基于聚类的初始化,所以分音系统可以处理灵活数量的说话人。这表明您可以在两个说话人数据集上训练建议的模型,然后使用它对两个或更多说话人进行分类。
- 虽然具有前面提到的所有优点,但与之前公布的结果相比,所提出的方法显示了优越的区分性能。
关于拟议系统,未来有两个研究领域:
- 我们计划通过实现基于短期窗口聚类的二值化解码器来实现该系统的流媒体版本。
- 可以研究从说话人嵌入提取器到二值化解码器的端到端优化,以提高说话人二值化性能。
有关更多信息,请参阅 Multiscale Speaker Diarization with Dynamic Scale Weighting 或 Interspeech 2022 会议。




