
多实例 GPU ( MIG )是 NVIDIA H100 , A100 和 A30 张量核 GPU ,因为它可以将 GPU 划分为多个实例。每个实例都有自己的计算核心、高带宽内存、二级缓存、 DRAM 带宽和解码器等媒体引擎。
这使得多个工作负载或多个用户能够在一个 GPU 上同时运行工作负载,以最大化 CPU 利用率,同时保证服务质量( QoS )。单个 A30 可以被划分为最多四个 MIG 实例,以并行运行四个应用程序。
这篇文章将指导您如何在 A30 上使用 MIG ,从划分 MIG 实例到同时在 MIG 实例上运行深度学习应用程序。
A30 MIG 剖面图
默认情况下, A30 上禁用 MIG 模式。在分区 GPU 上运行任何 MIG 工作负载之前,必须启用 CUDA 模式,然后对 A30 进行分区。要划分 A30 ,请创建 GPU 实例,然后创建相应的计算实例。
GPU 实例是 GPU 切片和 CPU 引擎( DMA 、 NVDEC 等)的组合。 GPU 切片是 GPU 的最小部分,它组合了单个 CPU 内存切片和单个流式多处理器( SM )切片。
在 GPU 实例中,GPU 内存片和其他 CPU 引擎共享,但 SM 片可以进一步细分为计算实例。 GPU 实例提供内存 QoS 。
您可以将具有 24 GB 内存的 A30 配置为:
- 一个 GPU 实例,具有 24 GB 内存
- 两个 GPU 实例,每个实例具有 12 GB 内存
- 三个 GPU 实例,一个具有 12GB 内存,两个具有 6GB 内存
- 四个 GPU 实例,每个实例具有 6 GB 内存
根据 GPU 实例的大小,可以将 GPU 实例进一步划分为一个或多个计算实例。计算实例包含父 GPU 实例的 SM 切片的子集。 GPU 实例中的计算实例共享内存和其他媒体引擎。但是,每个计算实例都有专用的 SM 切片。
例如,您可以将 A30 分成四个 GPU 实例,每个实例有一个计算实例,或者将 A30 分为两个 GPU 示例,每个实例都有两个计算实例。虽然这两个分区导致四个计算实例可以同时运行四个应用程序,但不同之处在于,内存和其他引擎在 GPU 实例级别隔离,而不是在计算实例级别隔离。因此,如果有多个用户共享 A30 ,最好为不同的用户创建不同的 GPU 实例以保证 QoS 。
表 1 概述了 A30 上支持的 GPU 配置文件,包括显示 MIG 实例数量和每个 CPU 实例中 GPU 切片数量的五种可能 MIG 配置。它还显示了硬件解码器如何在 GPU 实例之间划分。
| Config | GPC Slice #0 |
GPC Slice #1 |
GPC Slice #2 |
GPC Slice #3 |
OFA | NVDEC | NVJPG | P2P | GPU Direct RDMA |
| 1 |
4 | 1 | 4 |
1 | No | Supported MemBW proportional to the size of the instance | |||
| 2 | 2 | 2 | 0 | 2+2 | 0 | No | |||
| 3 | 2 | 1 | 1 | 0 | 2+1+1 | 0 | No | ||
| 4 | 1 | 1 | 2 | 0 | 1+1+2 | 0 | No | ||
| 5 | 1 | 1 | 1 | 1 | 0 | 1+1+1+1 | 0 | No | |
GPC (图形处理集群)或切片表示 SMs 、缓存和内存的分组。 GPC 直接映射到 GPU 实例。 OFA (光流加速器)是基于 A100 和 A30 的 GA100 架构上的引擎。对等( P2P )已禁用。
表 2 提供了 A30 上受支持的 MIG 实例的配置文件名,以及内存、 SMs 和二级缓存如何在 MIG 配置文件之间划分。 MIG 的配置文件名可以解释为其 GPU 实例的 SM 切片计数及其总内存大小( GB )。例如:
- MIG 2g 。 12gb 意味着这个 MIG 实例有两个 SM 片和 12gb 内存
- MIG 4g 。 24gb 意味着这个 MIG 实例有四个 SM 片和 24gb 内存
通过查看 2g 中 2 或 4 的 SM 切片计数。 12gb 或 4g 。 24gb ,您知道可以将 GPU 实例划分为两个或四个计算实例。有关详细信息,请参阅 分割 在MIG 用户指南.
| Profile | Fraction of memory | Fraction of SMs | Hardware units | L2 cache size | Number of instances available |
| MIG 1g.6gb | 1/4 | 1/4 | 0 NVDECs /0 JPEG /0 OFA | 1/4 | 4 |
| MIG 1g.6gb+me | 1/4 | 1/4 | 1 NVDEC /1 JPEG /1 OFA | 1/4 | 1 (A single 1g profile can include media extensions) |
| MIG 2g.12gb | 2/4 | 2/4 | 2 NVDECs /0 JPEG /0 OFA | 2/4 | 2 |
| MIG 4g.24gb | Full | 4/4 | 4 NVDECs /1 JPEG /1 OFA | Full | 1 |
MIG 1g 。 6gb + me : me 是指在创建 1g 时访问视频和 JPEG 解码器的媒体扩展。 6gb 配置文件。
MIG 实例可以动态创建和销毁. 创建和销毁不会影响其他实例,因此它为您提供了销毁未使用的实例并创建不同配置的灵活性。
管理 MIG 实例
使用mig-parted分区编辑器( MIG )自动创建 GPU 实例和计算实例 工具 或者按照中的nvidia-smi mig命令执行 开始使用 MIG .
强烈建议使用mig-parted工具,因为它使您能够轻松更改和应用 MIG 分区的配置,而无需发出一系列nvidia-smi mig命令。在使用该工具之前,您必须按照 说明 安装 mig-parted 工具或从标记的 版本 中获取预构建的二进制文件。
下面是如何使用该工具将 A30 划分为 1g 的四个 MIG 实例。 6gb 配置文件。首先,创建一个示例配置文件,然后可以与该工具一起使用。这个示例文件不仅包括前面讨论的分区,还包括一个自定义配置custom-config,将 GPU 0 划分为四个 1g 。 6gb 实例和 GPU 1 到两个 2g 。 12gb 实例。
$ cat << EOF > a30-example-configs.yaml
version: v1
mig-configs:
all-disabled:
- devices: all
mig-enabled: false
all-enabled:
- devices: all
mig-enabled: true
mig-devices: {}
all-1g.6gb:
- devices: all
mig-enabled: true
mig-devices:
"1g.6gb": 4
all-2g.12gb:
- devices: all
mig-enabled: true
mig-devices:
"2g.12gb": 2
all-balanced:
- devices: all
mig-enabled: true
mig-devices:
"1g.6gb": 2
"2g.12gb": 1
custom-config:
- devices: [0]
mig-enabled: true
mig-devices:
"1g.6gb": 4
- devices: [1]
mig-enabled: true
mig-devices:
"2g.12gb": 2
EOF
接下来,应用all-1g.6gb配置将 A30 划分为四个 MIG 实例。如果 MIG 模式尚未启用,则mig-parted启用GPU 模式,然后创建分区:
$ sudo ./nvidia-mig-parted apply -f a30-example-configs.yaml -c all-1g.6gb MIG configuration applied successfully $ sudo nvidia-smi mig -lgi +-------------------------------------------------------+ | GPU instances: | | GPU Name Profile Instance Placement | | ID ID Start:Size | |=======================================================| | 0 MIG 1g.6gb 14 3 0:1 | +-------------------------------------------------------+ | 0 MIG 1g.6gb 14 4 1:1 | +-------------------------------------------------------+ | 0 MIG 1g.6gb 14 5 2:1 | +-------------------------------------------------------+ | 0 MIG 1g.6gb 14 6 3:1 | +-------------------------------------------------------+
通过指定 MIG 几何图形,然后使用mig-parted适当配置 GPU ,您可以轻松选择其他配置或创建自己的自定义配置。
创建 MIG 实例后,现在您可以运行一些工作负载了!
深度学习用例
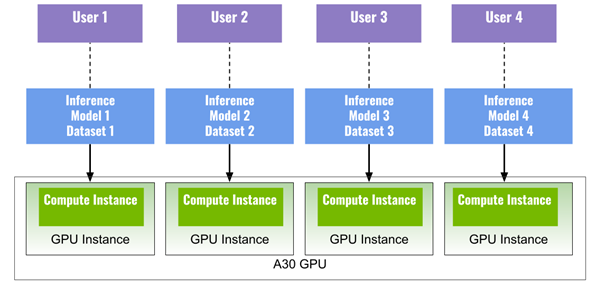
您可以在 MIG 实例上同时运行多个深度学习应用程序。图 1 显示了四个 MIG 实例(四个 GPU 实例,每个实例都有一个计算实例),每个实例运行一个深度学习推理模型,以最大限度地利用单个 A30 同时执行四个不同的任务。
例如,您可以 ResNet50 (图像分类)在实例 1 上, EfficientDet (对象检测)在实例二上, BERT (语言模型)在实例三上,以及 FastPitch (语音合成)实例四。该示例还可以表示四个不同的用户在确保 QoS 的情况下同时共享 A30 。
性能分析
为了分析在启用和不启用 MIG 的情况下 A30 的性能改进,我们对 BERT PyTorch 模型 SQuAD (问答)在 A30 (带和不带 MIG )和 T4 上的三种不同场景中。
- A30 四个 MIG 实例,每个实例有一个模型,总共四个模型同时微调
- A30 MIG 模式被禁用,四个模型在四个容器中同时微调
- A30 MIG 模式被禁用,四种型号串联微调
- T4 有四个串联微调模型
| Fine-tune BERT base, PyTorch, SQuAD, BS=4 | 1 | 2 | 3 | 4 | Result | ||
| A30 MIG: four models on four MIG devices simultaneously | Time (sec) | 5231.96 | 5269.44 | 5261.70 | 5260.45 | 5255.89 (Avg) | |
| Sequences/sec | 33.88 | 33.64 | 33.69 | 33.70 | 134.91 (Total) | ||
| A30 No MIG: four models in four containers simultaneously | Time (sec) | 7305.49 | 7309.98 | 7310.11 | 7310.38 | 7308.99 (Avg) | |
| Sequences/sec | 24.26 | 24.25 | 24.25 | 24.25 | 97.01 (Total) | ||
| A30 No MIG: four models in serial | Time (sec) | 1689.23 | 1660.59 | 1691.32 | 1641.39 | 6682.53 (Total) | |
| Sequences/sec | 104.94 | 106.75 | 104.81 | 108.00 | 106.13 (Avg) | ||
| T4: four models in serial | Time (sec) | 4161.91 | 4175.64 | 4190.65 | 4182.57 | 16710.77 (total) | |
| Sequences/sec | 42.59 | 42.45 | 42.30 | 42.38 | 42.43 (Avg) | ||
要运行此示例,请使用 NVIDIA /深度学习示例 github 回购。
根据表 3 中的实验结果,具有四个 MIG 实例的 A30 显示了总共四个模型的最高吞吐量和最短微调时间。
- 使用 MIG 的 A30 总微调时间的加速:
- 1.39 倍,与 A30 相比,四种型号同时使用 MIG
- 1.27 倍,与 A30 相比,在四个串联型号上无 MIG
- 3.18 倍于 T4
- A30 米格的吞吐量
- 1.39 倍,与 A30 相比,四种型号同时使用 MIG
- 1.27 倍,与 A30 相比,在四个串联型号上无 MIG
- 3.18 倍于 T4
在没有 MIG 的情况下,同时对具有四个模型的 A30 进行微调也可以实现高 GPU 利用率,但不同之处在于,没有 MIG 提供的硬件隔离。与使用 MIG 相比,它会产生上下文切换的开销,并导致性能降低。
下一步是什么?
A30 MIG 模式基于最新的 NVIDIA Ampere 架构,可加速各种工作负载,如大规模人工智能推理,使您能够充分利用单个 GPU ,同时以服务质量为多个用户提供服务。
有关 A30 功能、精度和性能基准测试结果的更多信息,请参阅 使用 NVIDIA A30 GPU 加速 AI 推理工作负载 .有关使用 MIG 和 Kubernetes 自动缩放 AI 推理工作负载的更多信息,请参阅 使用 MIG 和 Kubernetes 大规模部署 NVIDIA Triton .




