精确标注的数据集对于基于相机的深度学习算法执行自动驾驶车辆感知至关重要。然而,手动标记数据是一个耗时且成本密集的过程。
我们开发了一个自动标记管道,作为基于 Tata Consultancy Services (TCS) 人工智能( AI )的自动驾驶汽车平台的一部分。该管道使用 NVIDIA DGX A100 和 TCS 功能丰富的半自动标签工具进行检查和纠正。这篇文章介绍了标签流水线的设计、 NVIDIA DGX A100 如何加速标签,以及通过实施自动标签流程实现的节约。
设计自动标记管道
自动标记管道必须能够从网络存储驱动器中下载的图像中生成以下注释:
- 具有可见性属性(例如完全可见和遮挡)的 2D 对象检测
- 具有可见性属性(例如完全可见和遮挡)的 3D 对象检测
- 带有属性(如车道分类和车道颜色)的车道检测
我们为 2D 对象检测、 3D 对象检测和车道检测任务设计并训练了定制的深度神经网络( DNN )。然而,当测试用于自动标记目的的检测器输出时,我们观察到轻微的漏检。这为执行标签的人增加了更多的工作。此外,为每个对象或车道指定属性需要相当长的时间。
为了解决这些问题,我们添加了一种有效的跟踪算法,该算法为所有检测提供了跟踪标识。该算法与 TCS 半自动标记工具中增强的按轨迹 ID 复制功能相结合,有助于使用相同的轨迹 ID 纠正属性或检测。
一帧中的校正被复制到轨道 ID 相同的后续帧,从而加速校正。端到端管道由以下附加模块组成:
- 2D 对象跟踪器
- 车道跟踪器
优化管道
由于底层模块之间的相互依赖性,所有模块不能并行运行。作为一种解决方案,我们将整个管道执行分为三个阶段,以实现模块的并行执行。
管道的输入是 206 个图像序列,每个图像的分辨率为 1920 x 1280 像素。图 1 、图 2 和图 3 中提供的时序基于每个模块的批处理。
最初,在管道的基础版本中,当部署在 NVIDIA DGX A100 GPU 上时,批处理的端到端执行时间为 16 分 40 秒,即每帧 4.854 秒。
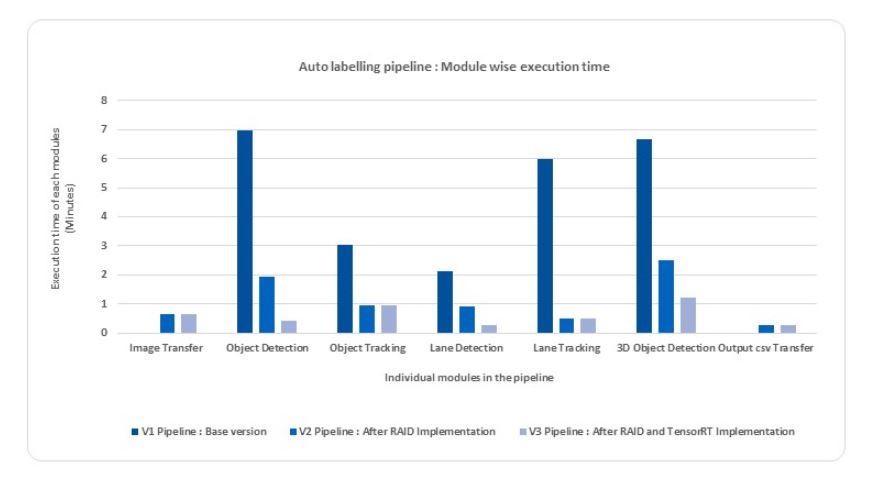
图 1 显示了基本版本的模块化时间分析。该执行时间包括从存储原始图像的网络驱动器读取图像,处理所有管道模块,并将自动注释保存到网络驱动器。
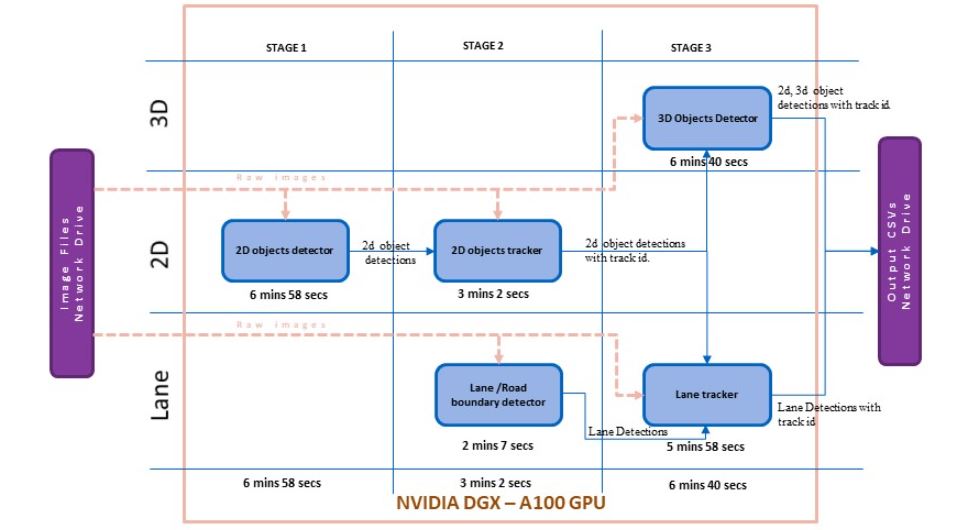
时间分析器分析了处理时间,显示从网络驱动器读取原始图像的速度相当高。这些模块使用原始图像作为输入之一,从网络驱动器读取图像的延迟会导致整个管道执行的巨大开销。
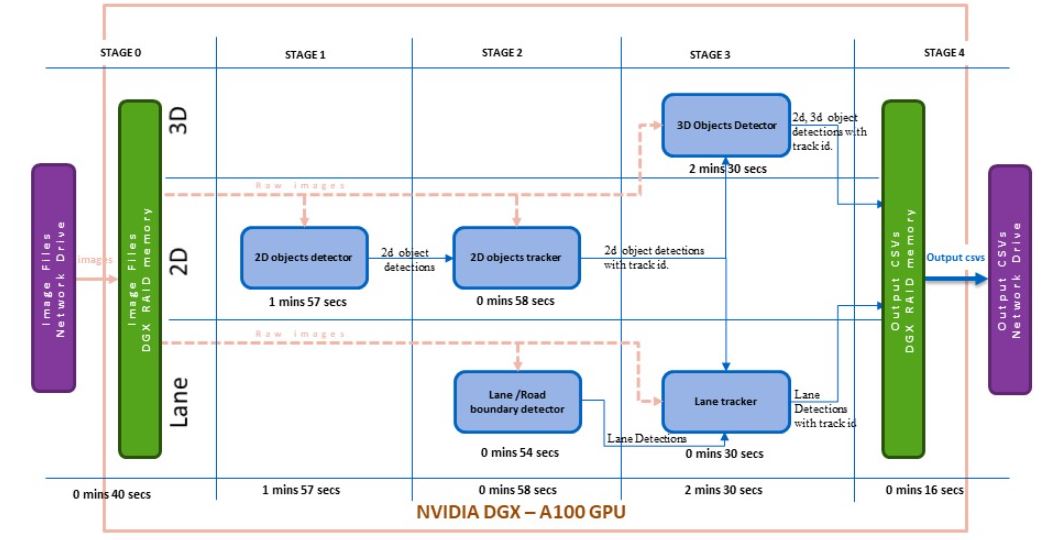
DGX RAID 内存被设置为管道第二版本的中间存储。在阶段 0 中,所有原始映像都从网络驱动器读取到 DGX RAID 内存(图 2 )。
模块从 RAID 内存加载原始图像,所有输出都存储在 RAID 内存中。管道执行后,最终的注释输出被移动到网络驱动器。
具有管道版本 2 的一批 206 个图像的总执行时间减少到 6 分 21 秒,即每帧 1.84 秒。图 2 显示了管道版本 2 的模块化时间分析。
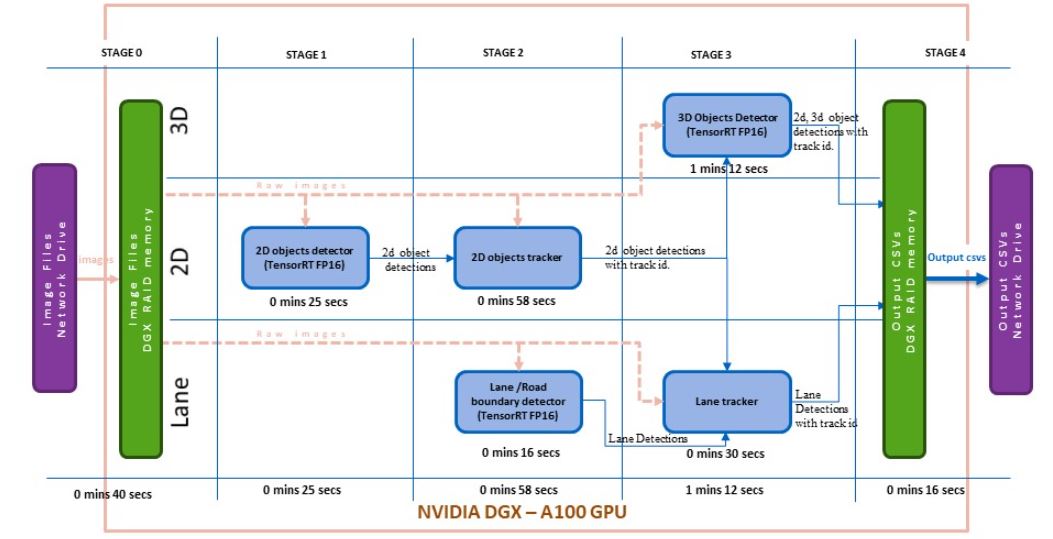
管道的版本 3 使用 NVIDIA NGC 容器和 TensorFlow 2.5 和 NVIDIA CUDA 11.4.1 ( TensorFlow : 21.08-tf2-py3 )。 PyTorch 的安装是为了满足底层 DNN 模块的依赖性。 GPU – 支持的 OpenCV 是在这个基础图像之上从源代码构建的。
核心深度学习算法需要进一步加速以达到所需的处理时间。通过利用 NGC Docker 中的 NVIDIA TensorRT 8.0.1.6 ,车道检测模型、 2D 物体检测模型和 3D 物体检测模型都被转换为 FP16 TensorRT 模型,并在管道的第 3 版中实现。
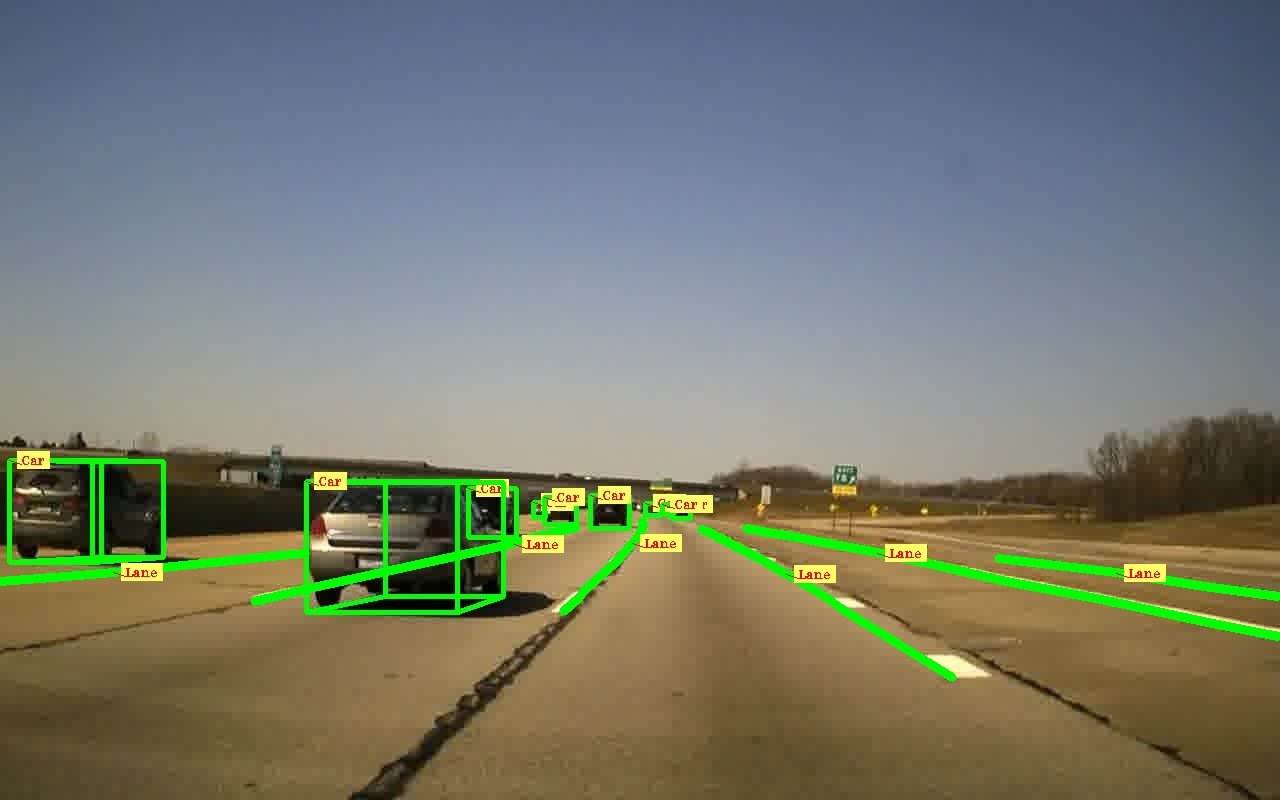
因此,对于 206 帧,管道的端到端执行时间降至 3 分 30 秒,即每帧 1.01 秒。图 3 显示了版本 3 的模块化时间分析。我们在不影响模型所需精度的情况下获得了结果。图 4 显示了这个自动标记管道的结果。
在管道的端到端执行期间,每个模块的处理时间节省如图 5 所示。通过 NVIDIA DGX 中的一个 NVIDIA A100 40 GB GPU ,深度学习算法被优化以减少模型加载时间的开销,从而实现更大的节约,以实现全天候自动标记所需的放大。
结论
凭借 NVIDIA DGX A100 GPU 的计算性能,加上 TCS 在 AI 和深度学习算法部署方面的专业知识,我们开发了一个高效的自动标记流水线,用于 AV 摄像机感知算法。 DGX RAID 内存和 NVIDIA TensorRT 的有效利用将自动标记管道的处理时间减少到总时间的四分之一。
部署了这条自动标记管线的国际汽车零部件供应商达到了65%的人工工作量的减少,而使用目前最先进的开放模型比如YOLOX,LaneNet只能提供34%的工作量的减少。
想了解更多信息吗? 免费注册 NVIDIA GTC 2023 , 3 月 20-23 日加入我们 为 AV 感知开发强大的多任务模型 。查看自动驾驶汽车开发人员的目标会话轨迹,包括 映射, 模拟, 安全性, 和更多 。