NVIDIA 平台是最成熟、最完整的加速计算平台。在这篇文章中,我将介绍最简单、最高效、最可移植的加速计算方法。有三种编程方法 GPU (图 1 )。
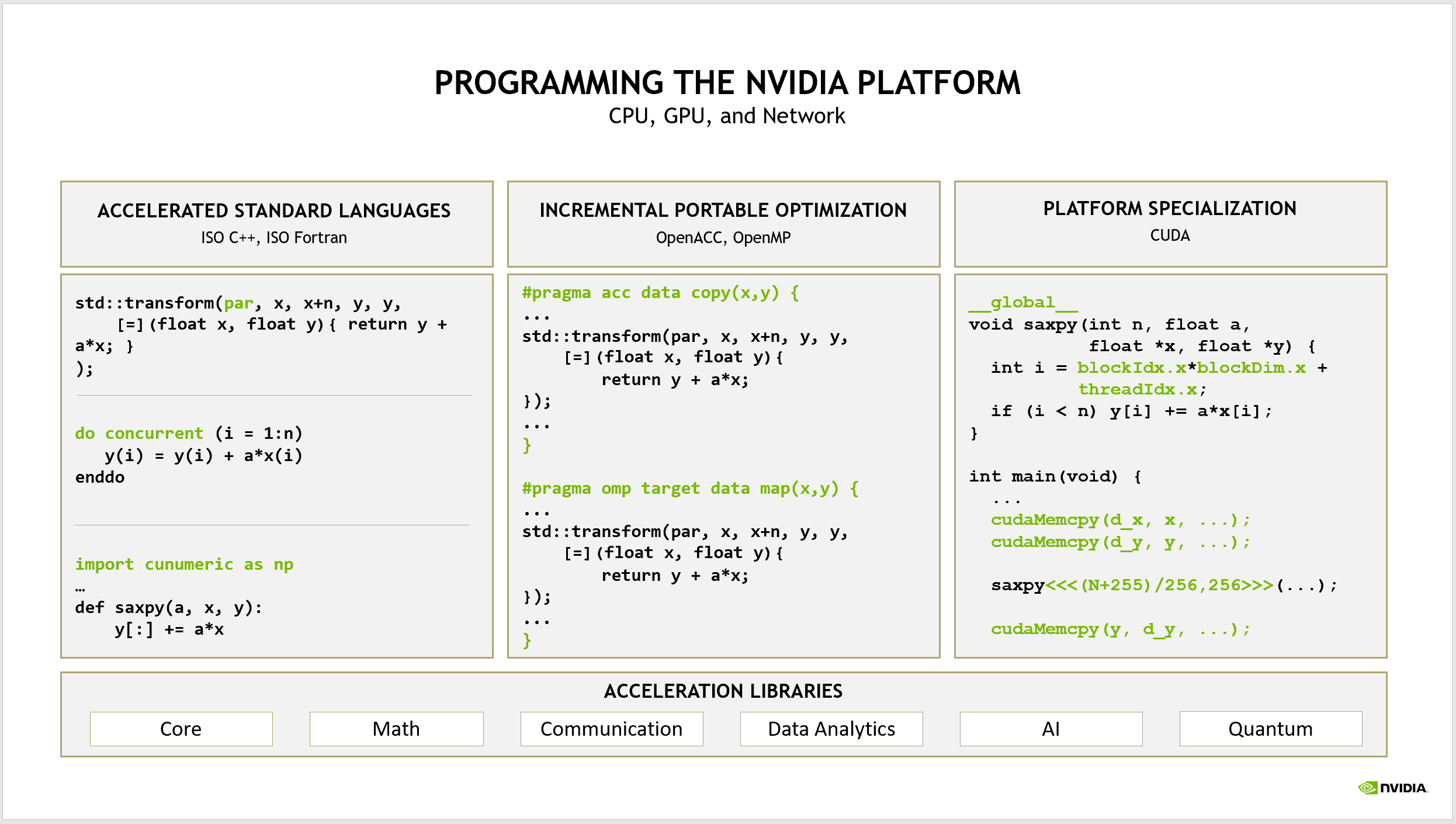
CUDA C ++ Fortran 是 NVIDIA 可以展示新硬件和软件创新的创新平台,在这里,您可以调整应用程序以在 NVIDIA GPU 上实现最佳性能。许多开发人员认为这就是 NVIDIA 希望每个人为 GPU 编程的方式。
相反,我们预计,开发者首次来到NVIDIA 平台将使用标准的并行编程语言,如 ISO C ++、 ISO Fortran 和 Python 。在这篇文章中,我强调了使用这种方法进行并行编程的一些成功,以证明进入NVIDIA CUDA 生态系统的最有成效的途径。
NVIDIA 战略的基础是提供一套丰富、成熟的 SDK 和库,在这些数据库上可以构建应用程序。 NVIDIA 已经提供了高度优化的数学库,如 cuBLAS 、 cuSolver 和 cuFFT ;核心库,如 Thrust 和 libcu++ ;和通信库,如 NCCL 和 NVSHMEM ,以及其他可用于构建应用程序的包和框架。
除此之外, NVIDIA 还将三种不同的编程方法分层:
- 标准语言并行性,这是本文的主题
- 用于平台专业化的语言,如 CUDA C ++和 CUDA FORTRAN ,以获得NVIDIA 平台上的最佳性能
- 编译器指令,通过启用增量性能优化来弥合这两种方法之间的差距
每种方法都在性能、生产率和代码可移植性方面进行权衡。因为它们都可以互操作,所以您不必使用特定的模型,但可以根据需要混合任何或所有模型。
如果您开始使用标准编程语言中的并行性编写代码,那么您可以来到NVIDIA 平台或任何其他已经具有并行运行能力的基线代码平台。这就是为什么我们在标准语言委员会中投入了十多年的时间来合作,采用特性来支持并行编程,而不需要额外的扩展或 API 。标准语言并行性是一股兴起的潮流,它让所有人都感到振奋。
ISO C ++
在编程趋势的最近研究中, C ++编程语言一直是最高级的编程语言之一。它在科学计算中的应用有了显著的增长。其标准模板库的丰富性使其成为新代码开发的高效语言,自 C ++ 17 发布以来,它支持并行编程的几个重要特性。
我看到几个应用程序从传统的循环中重构,有利于这些 C ++并行算法。下面是其中几个的结果。
Lulesh
Lulesh 是劳伦斯 LIVEMOR 国家实验室( LLNL )的流体动力学迷你应用程序,用 C++ 编写。 mini 应用程序有几个版本用于评估不同的编程方法,包括代码质量和性能。我们与开发人员一起工作,以重写他们现有的基于 OpenMP 的代码,使用 C ++并行算法。图 2 显示了应用程序重要功能之一的示例。

左边的代码使用 OpenMP 跨 CPU 线程并行化代码中的循环。为了维护串行和并行版本的代码,开发人员使用了#ifdef宏和编译器杂注。结果是重复代码,并在源代码中引入额外的 API OpenMP 。
右边的代码是相同的例程,但是使用 C ++ transform_reduce算法重写。生成的代码更加紧凑,不易出错,更易于阅读,更易于维护。它还移除了 OpenMP 的依赖性,依赖于 C ++标准模板库,同时为所有平台维护单个源代码。此代码完全符合 ISO C ++,能够由支持 C ++ 17 的任何 C ++编译器构建。事实证明,它也更快!
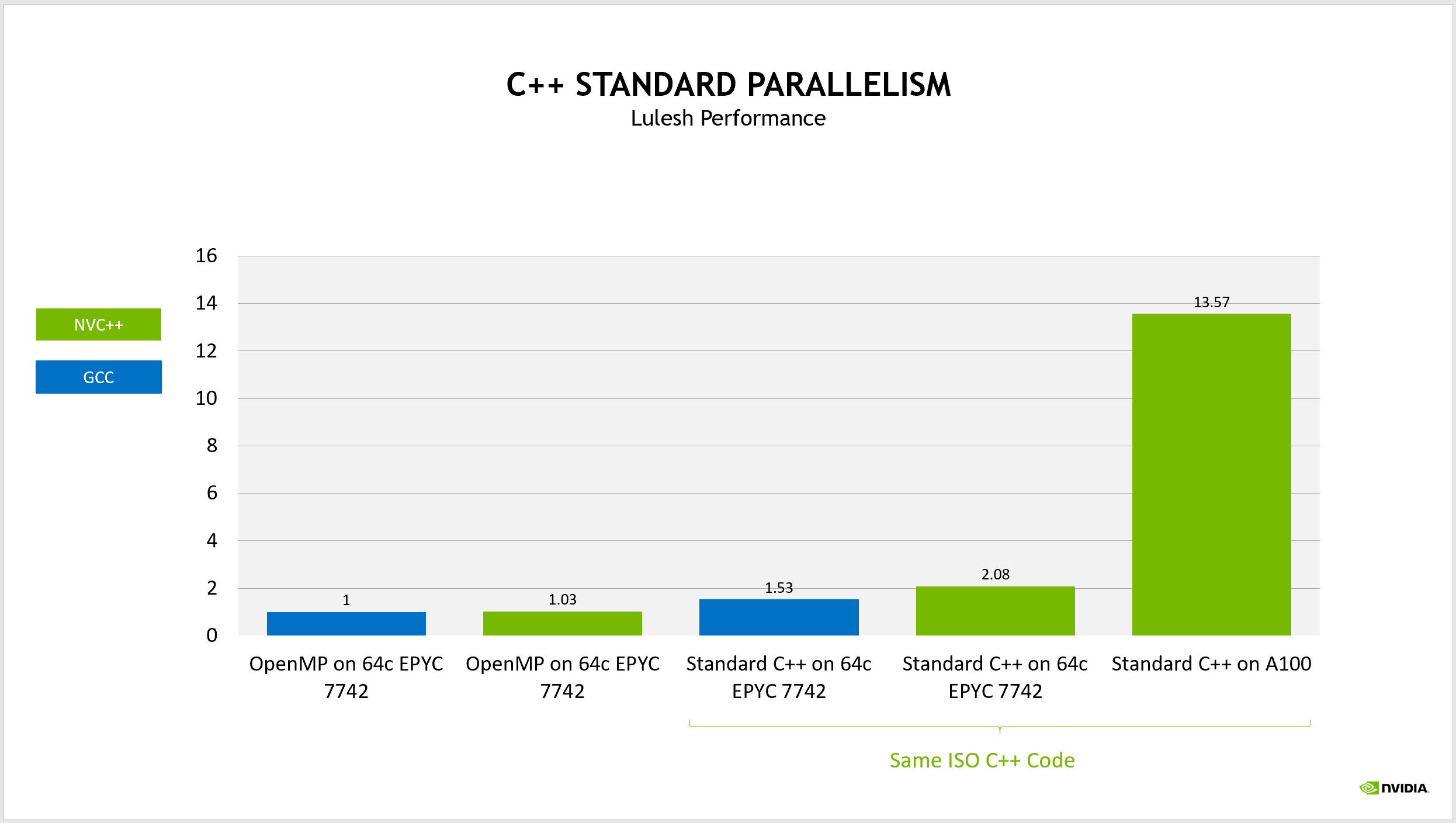
作为性能基准,我们使用运行在 AMD EPYC 7742 处理器所有核心上的 OpenMP 代码,并使用 GCC 构建。使用 NVIDIA nvc++编译器重建此基线代码在 CPU 上实现了基本相同的性能。
如果您使用同一版本的 GCC 来构建 ISO C ++代码,并在同一 CPU 上运行,则性能将提高约 50% ,这是由于编译器的各种改进开销和机会来更好地优化代码。
当使用nvc++构建此代码并在同一 CPU 上运行时,这将使性能提高 2 倍。这已经是一项激动人心的成就,但最重要的是,您可以构建相同的代码,只需将编译器选项更改为针对 NVIDIA GPU 而不是多核 CPU 。现在,同样的代码在 NvidiaA100 GPU 上运行速度快了 13 倍以上。从原始代码中得到 13.5x 性能改进,在 CPU 和 GPU 上并行运行,使用严格的 ISO C ++代码。
STLBM
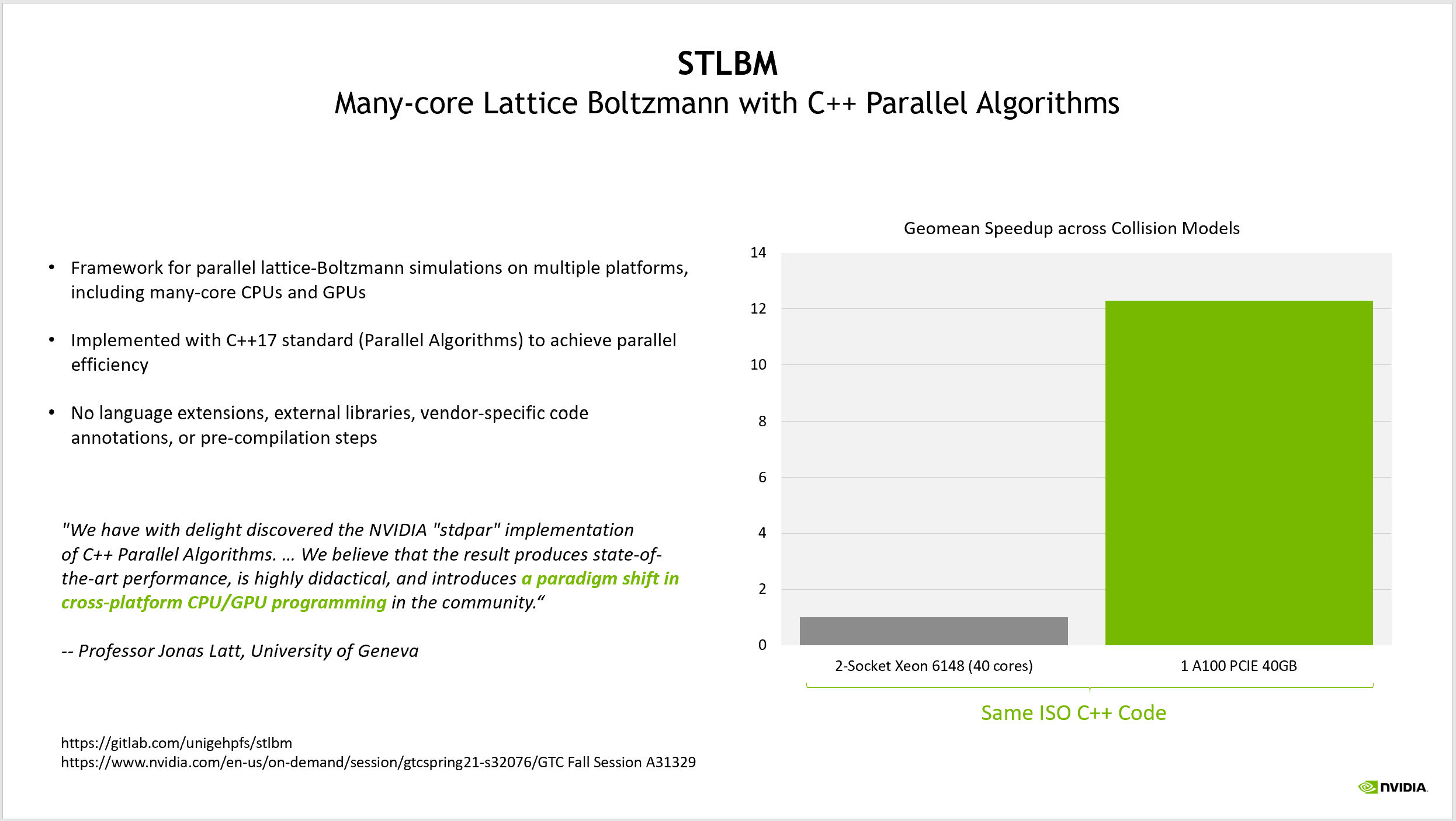
应用 C ++标准并行性的另一个例子是 STLBM ,来自日内瓦大学的格子 Boltzmann 求解器。 Jonas Latt 教授在几次 GTC 会议上讨论了这一应用 显示了如何在没有任何外部 SDK 依赖关系的情况下编写代码在 ISO C ++中运行,可以使用多个编译器和多个硬件平台,包括 NVIDIA GPU 。有关详细信息,请参阅 基于 C ++并行算法的 GPU 流体力学:一种硬件无关方法的最新进展 和 利用 C++ 标准并行技术在 GPU 中移植科学应用
他的应用程序使用 GPU 实现了超过 12 倍的性能改进。值得注意的是,他的比较基准是默认情况下并行的源代码,使用 C ++ 17 标准模板库中的并行算法来表示应用程序中固有的并行性。
他将使用ISO C++作为GPU编程的经验归类为“跨平台CPU/GPU编程的范式转换”。他的团队没有编写一个默认为串行的应用程序,然后再添加并行性,而是编写了一个适用于他们希望运行的任何并行平台的应用程序。
NVIDIA 在 C ++中并行开发和并发性的大量投资,并为即将到来的 C ++ 23 规范编写了各种建议,以进一步提高您编写并行的代码的能力。
ISO Fortran
Fortran 仍然是一种主要关注科学和高性能计算的语言。最初, Fortran 是公式转换器,它为开发人员和编译器提供了多种优势,并且还拥有用于建模和仿真代码的庞大现有代码库。
Fortran 在 2008 年开始添加支持并行编程的功能,在 2018 年增强了这些功能,并在即将发布的版本(目前称为 Fortran 202X )中继续完善这些功能。与 ISOC ++一样, NVIDIA 也一直在与应用程序开发人员一起使用 FORTRAN 中的标准语言并行化来实现它们的应用程序的现代化,并使它们并行。
计算化学
我的同事杰夫·哈蒙德在他的 FortranCon2021:GPU 上的标准 Fortran 及其在量子化学代码中的应用 session 在 NWChem 应用程序和另一个计算化学应用程序 GAMESS 的内核中使用 Fortran do concurrent循环,给出了一些有希望的结果。
对于 NWChem ,他分离了几个执行张量收缩的性能关键循环,并使用几个编程模型编写了它们。在多核 CPU 上,这些张量收缩使用 OpenMP 跨 CPU 核进行线程。对于 GPU ,有使用 OpenACC 、 OpenMP 目标卸载和现在的 Fortran do concurrent循环的版本可用。
图 5 显示了do concurrent循环的性能与 NVIDIA GPU 上的 OpenACC 和 OpenMP 目标卸载相同,但不需要在应用程序中包含这些附加 API 。这都是标准的 Fortran 。
高性能通量传输
在 SC21 会议的最近一次加速器编程使用指令研讨会( WACCPD )上, 预测科学公司。 的一组开发人员展示了他们重构其中一个生产代码的结果,该代码以前使用 OpenACC 在 NVIDIA GPU 上运行,使用do concurrent循环。
他们比较了使用 NVIDIA nvfortran、gfortran和ifort构建这个纯 ISO Fortran 应用程序的结果。他们得出结论,在使用nvfortran编译器的应用程序中,纯 Fortran 提供了他们所需的性能,而不需要任何指令。此外,此代码可以在 GPU 和多核 CPU 上并行运行,无需修改。

这篇论文在研讨会上获得了最佳论文奖,尽管它根本不需要加速器编程的指导。当被问及他们是否会在其他应用程序中继续采用标准语言并行方法时,演示者回答说,他们已经计划在公司的其他重要应用程序中采用这种方法。
Python 带有连字符和楔形文字
Python 语言在过去十年中迅速流行起来。它现在通常用于机器学习、数据科学,甚至是传统的建模和仿真应用。虽然 Python 不是 ISO 编程语言,像 C ++和 FORTRAN ,但是我们也在 Python 语言中实现标准语言并行性的精神。
在 GTC ‘ 21 秋季的基调演讲中, NVIDIA 首席执行官 Jensen Huang 介绍了 cuNumeric 的 alpha 版本,该库是在 NumPy 之后建模的,它能够实现与我所讨论的关于 ISO C ++和 FORTRAN 的特性。 NumPy 包在 Python 开发中非常普遍,几乎可以肯定,任何用 Python 编写的 HPC 应用程序都会使用它。
在名为 Legate 的包之上编写的cuNumeric包使 NumPy 应用程序不仅能够在 GPU 上,而且能够在大型集群中跨 GPU 自动扩展其工作。我已经看到了几个例子,简单地替换代码中的NumPy引用,而不是引用cuNumeric,我可以将该应用程序弱地缩放到 NVIDIA 内部集群的完整大小, Selene,这是世界上10个最快的超级计算机之一。
有关cuNumeric的更多信息,请参阅 NVIDIA 宣布 cuNumeric 公开发售 观看 GTC 点播会议, Legate :扩展 Python 生态系统 .
结论
我希望这篇文章能让你看到 GPU 编程并不像你可能听说的那么困难。如果使用标准语言并行性,甚至可能不需要任何代码更改。
NVIDIA 鼓励您先编写并行应用程序,这样就不需要将应用程序“移植”到新平台,而标准语言并行是实现这一点的最佳方法,因为它只需要 ISO 标准语言。这就是为什么我们继续投资于 ISO 编程语言,并为这些语言带来更多并行和并发特性。
总之,使用标准语言并行性有以下好处:
- 完全符合 ISO 语言,从而产生更可移植的代码
- 更紧凑、更易于阅读、不易出错的代码
- 默认情况下是并行的代码,因此它可以在更多平台上运行而无需修改
以下是 GTC ‘ 21 的几篇演讲,可以为您提供关于并行编程方法的更多细节:
有关更多信息,请参阅以下参考资料:
- 在 HPC SDK 上了解有关编译器支持和其他文章的更多信息。
- 免费下载 HPC SDK 软件 。




