语音是与 AI 驱动的应用程序通信的主要手段之一。从虚拟助理到数字化身,基于语音的界面正在改变我们通常与智能设备的交互方式。
深度学习 用于语音识别和语音合成的技术有助于改善用户体验,如人类般的响应和自然的音调。
如果您计划构建和部署支持语音 AI 的应用程序,本文将概述 自动语音识别 ( ASR )和文本到语音( TTS )技术如何因深度学习而发展。我还提到了当今现代应用中使用的一些流行的、最先进的 ASR 和 TTS 架构。
解密语音 AI
无论你是在元宇宙中与数字人交谈,还是在联络中心与真人交谈,每天都会产生数千亿分钟的音频。语音 AI 可以帮助自动化所有这些音频分钟。
Speech AI 包括 ASR 、 TTS 和相关任务等技术。有趣的是,这些技术并不新鲜,而且已经存在了 50 年。
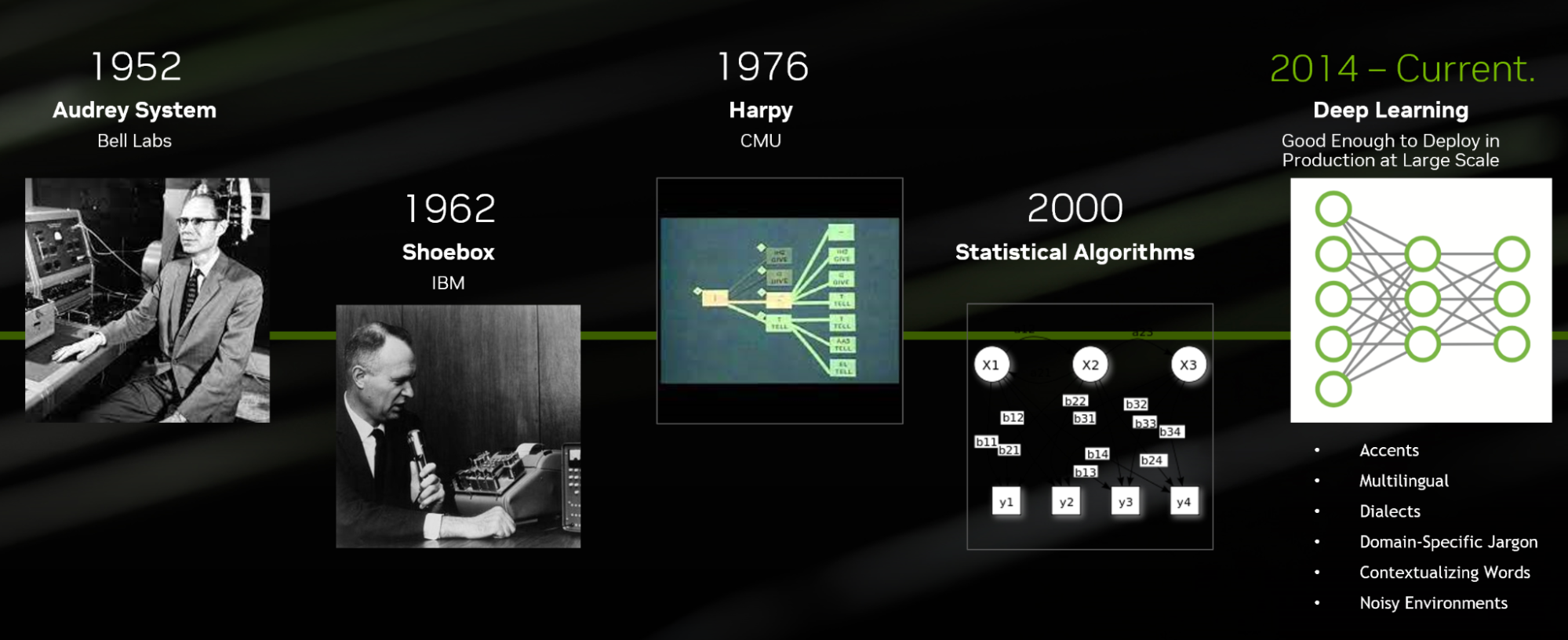
语音识别进化
今天,使用深度学习技术开发的 ASR 算法可以针对特定领域的行话、语言、口音和方言进行定制,也可以在嘈杂的环境中进行转录。
这种技术水平与贝尔实验室于 1952 年发明的第一个 ASR 系统 Audrey 有很大不同。当时, Audrey 只能转录数字,并没有使用深度学习技术开发。
ASR 管道
标准 ASR deep learning pipeline 由特征提取器、声学模型、解码器和语言模型以及 BERT 标点符号和大写模型组成。
文本到语音的演变
使用深度学习技术开发的 TTS 或语音合成系统听起来像真人,可以实时运行,进行自然而有意义的讨论。另一方面,传统系统如 Voder 、 DECtalk 商用和串联 TTS 声音机器人,很难实时运行。
深度学习 TTS 算法足够灵活,因此您可以在推断时调整速度、音调和持续时间,以生成更具表现力的 TTS 语音。
TTS 管道
基本 TTS pipeline 包括以下组件:文本规范化、文本编码、音调/持续时间预测器、谱图生成器和声码器模型。
您可以在点播视频 Speech AI Demystified 中进一步了解 ASR 和 TTS 在过去几年中的变化,以及 ASR 和 TTS 管道中的每个模型和模块。
当前使用的流行 ASR 和 TTS 架构
已经创建了几种最先进的神经网络架构。当今 ASR 中最流行的一些是 CTC 和基于传感器的架构模型。例如,您可以将这些架构技术应用于 CitriNet 和 Conformer 等模型。
对于 TTS ,存在不同类型的架构:
- 自回归或非自回归
- 确定性或生成性
- 显式控件或非显式控件
这些 TTS 架构中的每一个都提供不同的功能。例如,确定性模型可以准确预测结果,而不包括随机性。生成模型包括数据分布本身,可以捕捉合成语音的不同变化。要构建端到端的文本到语音管道,必须将每个类别中的一个架构组合起来。
您可以在点播视频 Speech AI Demystified 中获得最新的架构最佳实践,为支持语音的应用程序构建 ASR 和 TTS 管道。
NVIDIA 语音 AI SDK
通过利用 GPU 加速语音 AI SDK ,您可以开发基于深度学习的 ASR 和 TTS 算法。 NVIDIA Riva 帮助您构建和部署可定制的 AI 管道,在所有云、内部、边缘和嵌入式设备上提供世界级的准确性。
Riva 拥有最先进的 NGC 预训练模型 ,可在多个开放和专有数据集上进行训练。您可以使用低编码工具定制这些模型,以适应您的行业和使用情况,并优化语音 AI 技能,这些技能可以实时运行,而不牺牲准确性。
构建您的第一个语音 AI 应用程序
您是否希望为应用程序添加交互式语音体验?以下免费电子书将指导您的旅程:
- 使用 语音人工智能介绍 全面了解不断增长的语音 AI 环境。
- 使用 End-to-End Speech AI Pipelines 了解如何通过将 TTS 技能添加到应用程序中来实现自然发音的语音。
- 了解您的组织如何使用 开发语音人工智能应用 部署语音 AI 。
如果您喜欢循序渐进的指导,请查看 开始使用用于语音 AI 的高度准确的自定义 ASR 的自定进度在线课程。