调试很困难。跨多种语言调试尤其具有挑战性,跨设备调试通常需要一个具有不同技能和专业知识的团队来揭示潜在问题
然而,项目通常需要使用多种语言,以确保必要时的高性能、用户友好的体验以及可能的兼容性。不幸的是,没有一种编程语言能够提供上述所有功能,这就要求开发人员变得多才多艺。
这篇文章展示了RAPIDS该团队着手调试多种编程语言,包括使用GDB以识别和解决死锁。该团队致力于设计加速和扩展数据科学解决方案的软件。
这篇文章中的 bug 是RAPIDS 项目这一问题在 2019 年夏天得到了确认和解决。它涉及到一个包含多种编程语言的复杂堆栈,主要是 C 、 C ++和 Python ,以及CUDA对于 GPU 加速度
记录这个历史错误及其解决方案有几个目的,包括:
- 用 GDB 演示 Python 和 C 调试
- 提出关于如何诊断死锁的想法
- 更好地理解混合 Python 和 CUDA
这篇文章中的内容应该有助于你理解这些错误是如何表现出来的,以及如何在你自己的工作中解决类似的问题。
Bug 描述
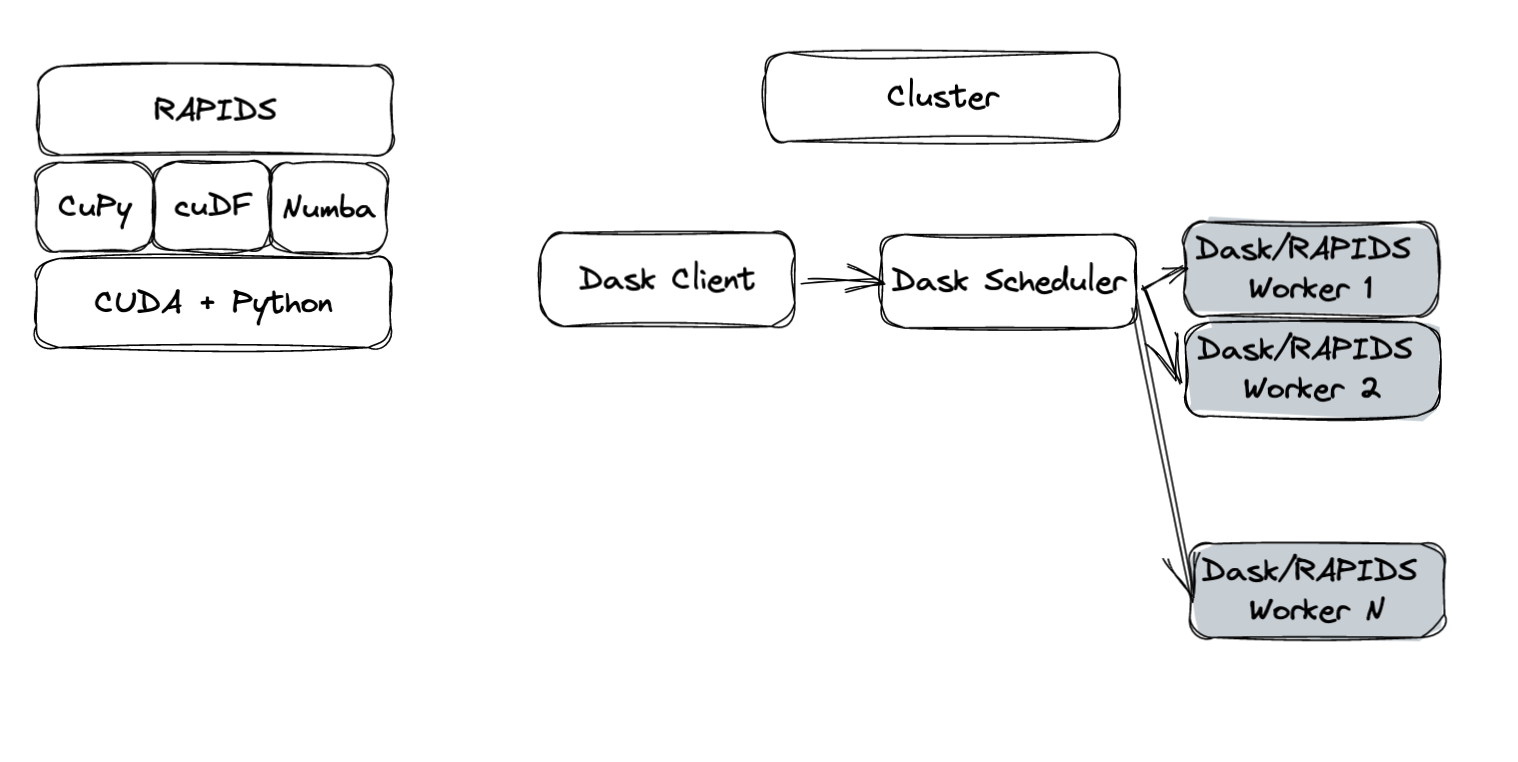
为了高效和高性能, RAPIDS 依赖于各种库进行多种不同的操作。举几个例子, RAPIDS 使用CuPy和cuDF以分别计算 GPU 上的数组和数据帧。Numba是一个即时编译器,可用于加速 GPU 上用户定义的 Python 操作
此外Dask用于将计算扩展到多个 GPU 和多个节点。手头的 bug 中的最后一块拼图是UCX, a communication framework used to leverage a variety of interconnects , such as InfiniBand and NVLink .
图 1 显示了该堆栈的概述。尽管当时未知,但该堆栈中的某个位置发生了死锁,导致工作流无法完成。
这种僵局首次出现在 2019 年 8 月,也就是 UCX 引入堆栈后不久。事实证明,死锁以前在没有 UCX 的情况下表现出来(使用 Dask 默认的 TCP 通信器),只是偶尔出现。
死锁发生时,我们花了很多时间探索这个空间。尽管当时未知,但该错误可能发生在特定的操作中,例如group by aggregation,merge/joins,repartitioning,或在任何库的特定版本中,包括 cuDF 、 CuPy 、 Dask 、 UCX 等。因此,有许多方面需要探索。
准备调试
接下来的部分将向您介绍如何为调试做准备。
设置最小复制机
找到一个最小的复制器是调试任何东西的关键。这个问题最初是在运行 8 GPU 的工作流中发现的。随着时间的推移,我们将其减少到两个 GPU 。拥有一个最小的复制器对于轻松地与他人共享错误并获得更广泛团队的时间和关注至关重要。
设置您的环境
在深入研究这个问题之前,先设置好你的环境。 0 . 10 版本的 RAPIDS (于 2019 年 10 月发布)可以最低限度地再现该漏洞。可以使用 Conda 或 Docker 来设置环境(请参阅本文后面的相应部分)。
整个过程假设使用 Linux 。由于 UCX 在 Windows 或 MacOS 上不受支持,因此在这些操作系统上无法复制。
Conda
首先,安装Miniconda。初次安装后,强烈建议您安装mamba通过运行以下脚本:
conda install mamba -n base -c conda-forge
然后运行以下脚本创建并激活一个 RAPIDS 0 . 10 的 conda 环境:
mamba create -n rapids-0.10 -c rapidsai -c nvidia -c conda-forge rapids=0.10 glog=0.4 cupy=6.7 numba=0.45.1 ucx-py=0.11 ucx=1.7 ucx-proc=*=gpu libnuma dask=2.30 dask-core=2.30 distributed=2.30 gdb
conda activate rapids-0.10
我们建议曼巴加快环境分辨率。跳过该步骤并替换mamba具有conda应该也能工作,但可能会慢得多。
Docker
或者,您可以使用 Docker 重现该错误。在你拥有NVIDIA Container Toolkit之后按照这些说明进行设置。
docker run -it --rm --cap-add sys_admin --cap-add sys_ptrace --ipc shareable --net host --gpus all rapidsai/rapidsai:0.10-cuda10.0-runtime-ubuntu18.04 /bin/bash
在容器中,安装mamba以加快环境分辨率。
conda create -n mamba -c conda-forge mamba -y
然后,安装 UCX / UCX-Py ,然后libnuma,这是一个 UCX 依赖项。此外,将 Dask 升级到集成了 UCX 支持的版本。为了以后进行调试,还可以安装 GDB 。
/opt/conda/envs/mamba/bin/mamba install -y -c rapidsai -c nvidia -c conda-forge dask=2.30 dask-core=2.30 distributed=2.30 fsspec=2022.11.0 libnuma ucx-py=0.11 ucx=1.7 ucx-proc=*=gpu gdb -p /opt/conda/envs/rapids
调试
本节详细介绍了这个特定问题是如何遇到并最终解决的,并提供了详细的分步概述。您还可以复制和练习一些所描述的概念。
正在运行(或挂起)
有问题的调试问题肯定不仅限于单个计算问题,但使用我们在 2019 年使用的相同工作流更容易。可以通过运行以下脚本将该脚本下载到本地环境:
wget
https://gist.githubusercontent.com/pentschev/9ce97f8efe370552c7dd5e84b64d3c92/raw/424c9cf95f31c18d32a9481f78dd241e08a071a9/cudf-deadlock.py
要进行复制,请执行以下操作:
OPENBLAS_NUM_THREADS=1 UCX_RNDV_SCHEME=put_zcopy UCX_MEMTYPE_CACHE=n UCX_TLS=sockcm,tcp,cuda_copy,cuda_ipc python cudf-deadlock.py
在几次迭代中(可能只有一两次),您应该会看到前面的程序挂起。现在真正的工作开始了。
僵局
死锁的一个好特性是进程和线程(如果你知道如何调查它们)可以显示它们当前正在尝试做什么。你可以推断出是什么导致了死锁
关键工具是 GDB 。然而, PDB 最初花了很多时间来调查 Python 在每一步都在做什么。 GDB 可以连接到活动进程,因此您必须首先了解进程及其关联 ID 是什么:
(rapids) root@dgx13:/rapids/notebooks# ps ax | grep python
19 pts/0 S 0:01 /opt/conda/envs/rapids/bin/python /opt/conda/envs/rapids/bin/jupyter-lab --allow-root --ip=0.0.0.0 --no-browser --NotebookApp.token=
865 pts/0 Sl+ 0:03 python cudf-deadlock.py
871 pts/0 S+ 0:00 /opt/conda/envs/rapids/bin/python -c from multiprocessing.semaphore_tracker import main;main(69)
873 pts/0 Sl+ 0:08 /opt/conda/envs/rapids/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=70, pipe_handle=76) --multiprocessing-fork
885 pts/0 Sl+ 0:07 /opt/conda/envs/rapids/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=70, pipe_handle=85) --multiprocessing-fork
四个 Python 过程与此问题相关:
- Dask 客户端 (
865) - Dask 调度程序 (
871) - 两名 Dask 工人 (
873和885)
有趣的是,自从最初调查这个错误以来,在调试 Python 方面已经取得了重大进展。 2019 年, RAPIDS 在 Python 3 . 6 上运行,该版本已经有了调试较低堆栈的工具,但只有当 Python 以调试模式构建时。这可能需要重建整个软件堆栈,这在像这样的复杂情况下是令人望而却步的
由于 Python 3 . 8debug builds use the same ABI as release builds,极大地简化了 C 和 Python 堆栈组合的调试。我们在这篇文章中没有涉及到这一点。
GDB 勘探
使用gdb连接到最后一个正在运行的进程( Dask 工人之一):
(rapids) root@dgx13:/rapids/notebooks# gdb -p 885
Attaching to process 885
[New LWP 889]
[New LWP 890]
[New LWP 891]
[New LWP 892]
[New LWP 893]
[New LWP 894]
[New LWP 898]
[New LWP 899]
[New LWP 902]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f5494d48938 in pthread_rwlock_wrlock () from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb)
每个 Dask 工作程序都有几个线程(通信、计算、管理等等)。使用gdb命令info threads检查每个线程在做什么。
(gdb) info threads
Id Target Id Frame
* 1 Thread 0x7f5495177740 (LWP 885) "python" 0x00007f5494d48938 in pthread_rwlock_wrlock () from /lib/x86_64-linux-gnu/libpthread.so.0
2 Thread 0x7f5425b98700 (LWP 889) "python" 0x00007f5494d4d384 in read () from /lib/x86_64-linux-gnu/libpthread.so.0
3 Thread 0x7f5425357700 (LWP 890) "python" 0x00007f5494d49f85 in pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib/x86_64-linux-gnu/libpthread.so.0
4 Thread 0x7f5424b16700 (LWP 891) "python" 0x00007f5494d49f85 in pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib/x86_64-linux-gnu/libpthread.so.0
5 Thread 0x7f5411fff700 (LWP 892) "cuda-EvtHandlr" 0x00007f5494a5fbf9 in poll () from /lib/x86_64-linux-gnu/libc.so.6
6 Thread 0x7f54117fe700 (LWP 893) "python" 0x00007f5494a6cbb7 in epoll_wait () from /lib/x86_64-linux-gnu/libc.so.6
7 Thread 0x7f5410d3c700 (LWP 894) "python" 0x00007f5494d4c6d6 in do_futex_wait.constprop () from /lib/x86_64-linux-gnu/libpthread.so.0
8 Thread 0x7f53f6048700 (LWP 898) "python" 0x00007f5494d49f85 in pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib/x86_64-linux-gnu/libpthread.so.0
9 Thread 0x7f53f5847700 (LWP 899) "cuda-EvtHandlr" 0x00007f5494a5fbf9 in poll () from /lib/x86_64-linux-gnu/libc.so.6
10 Thread 0x7f53a39d9700 (LWP 902) "python" 0x00007f5494d4c6d6 in do_futex_wait.constprop () from /lib/x86_64-linux-gnu/libpthread.so.0
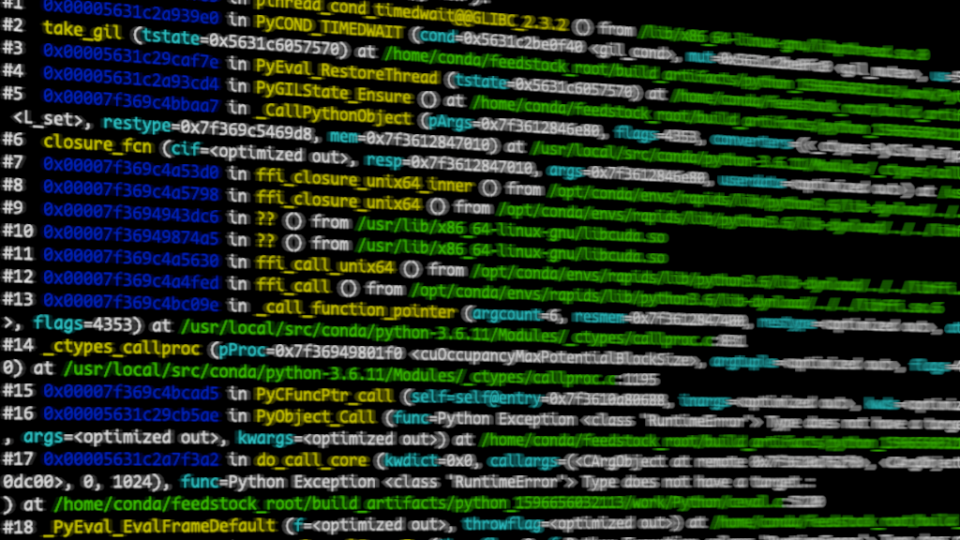
这个 Dask 工作程序有 10 个线程,其中一半似乎在等待互斥/ futex 。另一半cuda-EvtHandlr正在轮询。通过查看回溯,观察当前线程(由左侧的*表示)线程 1 正在做什么:
(gdb) bt
#0 0x00007f5494d48938 in pthread_rwlock_wrlock () from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f548bc770a8 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#2 0x00007f548ba3d87c in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#3 0x00007f548bac6dfa in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#4 0x00007f54240ba372 in uct_cuda_ipc_iface_event_fd_arm (tl_iface=0x562398656990, events=<optimized out>) at cuda_ipc/cuda_ipc_iface.c:271
#5 0x00007f54241d4fc2 in ucp_worker_arm (worker=0x5623987839e0) at core/ucp_worker.c:1990
#6 0x00007f5424259b76 in __pyx_pw_3ucp_5_libs_4core_18ApplicationContext_23_blocking_progress_mode_1_fd_reader_callback ()
from /opt/conda/envs/rapids/lib/python3.6/site-packages/ucp/_libs/core.cpython-36m-x86_64-linux-gnu.so
#7 0x000056239601d5ae in PyObject_Call (func=<cython_function_or_method at remote 0x7f54242bb608>, args=<optimized out>, kwargs=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Objects/abstract.c:2261
#8 0x00005623960d13a2 in do_call_core (kwdict=0x0, callargs=(), func=<cython_function_or_method at remote 0x7f54242bb608>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:5120
#9 _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:3404
#10 0x00005623960924b5 in PyEval_EvalFrameEx (throwflag=0, f=Python Exception <class 'RuntimeError'> Type does not have a target.:
) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:754
#11 _PyFunction_FastCall (globals=<optimized out>, nargs=<optimized out>, args=<optimized out>, co=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:4933
#12 fast_function (func=<optimized out>, stack=<optimized out>, nargs=<optimized out>, kwnames=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:4968
#13 0x00005623960a13af in call_function (pp_stack=0x7ffdfa2311e8, oparg=<optimized out>, kwnames=0x0)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:4872
#14 0x00005623960cfcaa in _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:3335
#15 0x00005623960924b5 in PyEval_EvalFrameEx (throwflag=0, Python Exception <class 'RuntimeError'> Type does not have a target.:
f=) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:754
#16 _PyFunction_FastCall (globals=<optimized out>, nargs=<optimized out>, args=<optimized out>, co=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:4933
#17 fast_function (func=<optimized out>, stack=<optimized out>, nargs=<optimized out>, kwnames=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:4968
#18 0x00005623960a13af in call_function (pp_stack=0x7ffdfa2313f8, oparg=<optimized out>, kwnames=0x0)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:4872
#19 0x00005623960cfcaa in _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>)
at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:3335
#20 0x00005623960924b5 in PyEval_EvalFrameEx (throwflag=0, Python Exception <class 'RuntimeError'> Type does not have a target.:
f=) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:754
查看堆栈的前 20 帧(为了简洁起见,后面的帧都是不相关的 Python 内部调用,省略了),您可以看到一些内部的 Python 调用:_PyEval_EvalFrameDefault,_PyFunction_FastCall和_PyEval_EvalCodeWithName。也有一些电话libcuda.so.
这一观察结果暗示可能存在死锁。它可以是 Python 、 CUDA ,也可能是两者都有。这个Linux Wikibook on Deadlocks包含调试死锁的方法,以帮助您向前迈进
然而pthread_mutex_lock正如维基解密中所描述的,它在这里pthread_rwlock_wrlock.
(gdb) bt
#0 0x00007f8e94762938 in pthread_rwlock_wrlock () from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f8e8b6910a8 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#2 0x00007f8e8b45787c in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
…
根据documentation for pthread_rwlock_wrlock,只需要一个参数,rwlock,这是一个读/写锁。现在,看看代码在做什么,并列出源代码:
(gdb) list
6 /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Programs/python.c: No such file or directory.
没有调试符号。回到 Linux Wikibook ,您可以查看寄存器。您也可以在 GDB 中这样做:
(gdb) info reg
rax 0xfffffffffffffe00 -512
rbx 0x5623984aa750 94710878873424
rcx 0x7f5494d48938 140001250937144
rdx 0x3 3
rsi 0x189 393
rdi 0x5623984aa75c 94710878873436
rbp 0x0 0x0
rsp 0x7ffdfa230be0 0x7ffdfa230be0
r8 0x0 0
r9 0xffffffff 4294967295
r10 0x0 0
r11 0x246 582
r12 0x5623984aa75c 94710878873436
r13 0xca 202
r14 0xffffffff 4294967295
r15 0x5623984aa754 94710878873428
rip 0x7f5494d48938 0x7f5494d48938 <pthread_rwlock_wrlock+328>
eflags 0x246 [ PF ZF IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
问题是不知道它们的意思。幸运的是,文档是存在的,例如Guide to x86-64 from Stanford CS107,解释了前六个参数在寄存器中%rdi,%rsi,%rdx,%rcx,%r8和%r9.
如前所述,pthread_rwlock_wrlock只需要一个参数,所以必须在%rdi剩下的可能会被用作通用寄存器pthread_rwlock_wrlock.
现在,您需要阅读%rdi登记你已经知道它有一个类pthread_rwlock_t,因此必须可以取消引用:
(gdb) p *(pthread_rwlock_t*)$rdi
$2 = {__data = {__lock = 3, __nr_readers = 0, __readers_wakeup = 0, __writer_wakeup = 898, __nr_readers_queued = 0, __nr_writers_queued = 0, __writer = 0,
__shared = 0, __pad1 = 0, __pad2 = 0, __flags = 0}, __size = "\003", '\000' <repeats 11 times>, "\202\003", '\000' <repeats 41 times>, __align = 3}
显示的是pthread_rwlock_t反对libcuda.so传递给pthread_rwlock_wrlock– 锁本身。不幸的是,这些名字并没有太大的相关性。你可以推断__lock可能意味着同时尝试获取锁的次数,但这是推断的范围
唯一具有非零值的其他属性是__write_wakeup。 Linux Wikibook 列出了一个有趣的值,称为__owner,它指向当前拥有锁所有权的进程标识符( PID )。鉴于此pthread_rwlock_t是读/写锁,假设__writer_wakeup指向拥有锁的进程可能是一个很好的下一步。
关于 Linux 的一个事实是,程序中的每个线程都像一个进程一样运行。每个线程都应该有一个 PID (或 GDB 中的 LWP )
再次查看进程中的所有线程,查找一个 PID 与相同的线程__writer_wakeup。幸运的是,有一个线程确实具有该 ID :
(gdb) info threads
Id Target Id Frame
8 Thread 0x7f53f6048700 (LWP 898) "python" 0x00007f5494d49f85 in pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib/x86_64-linux-gnu/libpthread.so.0
到目前为止,线程 8 可能拥有线程 1 试图获取的锁。线程 8 的堆栈可能会提供有关正在发生的事情的线索。接下来运行:
(gdb) thread apply 8 bt
Thread 8 (Thread 0x7f53f6048700 (LWP 898) "python"):
#0 0x00007f5494d49f85 in pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00005623960e59e0 in PyCOND_TIMEDWAIT (cond=0x562396232f40 <gil_cond>, mut=0x562396232fc0 <gil_mutex>, us=5000) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/condvar.h:103
#2 take_gil (tstate=0x5623987ff240) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval_gil.h:224
#3 0x000056239601cf7e in PyEval_RestoreThread (tstate=0x5623987ff240) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:369
#4 0x00005623960e5cd4 in PyGILState_Ensure () at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/pystate.c:895
#5 0x00007f5493610aa7 in _CallPythonObject (pArgs=0x7f53f6042e80, flags=4353, converters=(<_ctypes.PyCSimpleType at remote 0x562396b4d588>,), callable=<function at remote 0x7f53ec6e6950>, setfunc=0x7f549360ba80 <L_set>, restype=0x7f549369b9d8, mem=0x7f53f6043010) at /usr/local/src/conda/python-3.6.11/Modules/_ctypes/callbacks.c:141
#6 closure_fcn (cif=<optimized out>, resp=0x7f53f6043010, args=0x7f53f6042e80, userdata=<optimized out>) at /usr/local/src/conda/python-3.6.11/Modules/_ctypes/callbacks.c:296
#7 0x00007f54935fa3d0 in ffi_closure_unix64_inner () from /opt/conda/envs/rapids/lib/python3.6/lib-dynload/../../libffi.so.6
#8 0x00007f54935fa798 in ffi_closure_unix64 () from /opt/conda/envs/rapids/lib/python3.6/lib-dynload/../../libffi.so.6
#9 0x00007f548ba99dc6 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#10 0x00007f548badd4a5 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#11 0x00007f54935fa630 in ffi_call_unix64 () from /opt/conda/envs/rapids/lib/python3.6/lib-dynload/../../libffi.so.6
#12 0x00007f54935f9fed in ffi_call () from /opt/conda/envs/rapids/lib/python3.6/lib-dynload/../../libffi.so.6
#13 0x00007f549361109e in _call_function_pointer (argcount=6, resmem=0x7f53f6043400, restype=<optimized out>, atypes=0x7f53f6043380, avalues=0x7f53f60433c0, pProc=0x7f548bad61f0 <cuOccupancyMaxPotentialBlockSize>, flags=4353) at /usr/local/src/conda/python-3.6.11/Modules/_ctypes/callproc.c:831
#14 _ctypes_callproc (pProc=0x7f548bad61f0 <cuOccupancyMaxPotentialBlockSize>, argtuple=<optimized out>, flags=4353, argtypes=<optimized out>, restype=<_ctypes.PyCSimpleType at remote 0x562396b4d588>, checker=0x0) at /usr/local/src/conda/python-3.6.11/Modules/_ctypes/callproc.c:1195
#15 0x00007f5493611ad5 in PyCFuncPtr_call (self=self@entry=0x7f53ed534750, inargs=<optimized out>, kwds=<optimized out>) at /usr/local/src/conda/python-3.6.11/Modules/_ctypes/_ctypes.c:3970
#16 0x000056239601d5ae in PyObject_Call (func=Python Exception <class 'RuntimeError'> Type does not have a target.:
, args=<optimized out>, kwargs=<optimized out>) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Objects/abstract.c:2261
#17 0x00005623960d13a2 in do_call_core (kwdict=0x0, callargs=(<CArgObject at remote 0x7f53ed516530>, <CArgObject at remote 0x7f53ed516630>, <c_void_p at remote 0x7f53ed4cad08>, <CFunctionType at remote 0x7f5410f4ef20>, 0, 1024), func=Python Exception <class 'RuntimeError'> Type does not have a target.:
) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:5120
#18 _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:3404
#19 0x0000562396017ea8 in PyEval_EvalFrameEx (throwflag=0, f=Python Exception <class 'RuntimeError'> Type does not have a target.:
) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:754
#20 _PyEval_EvalCodeWithName (_co=<optimized out>, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kwnames=0x0, kwargs=0x7f541805a390, kwcount=<optimized out>, kwstep=1, defs=0x0, defcount=0, kwdefs=0x0, closure=(<cell at remote 0x7f5410520408>, <cell at remote 0x7f53ed637c48>, <cell at remote 0x7f53ed6377f8>), name=Python Exception <class 'RuntimeError'> Type does not have a target.:
, qualname=Python Exception <class 'RuntimeError'> Type does not have a target.:
) at /home/conda/feedstock_root/build_artifacts/python_1596656032113/work/Python/ceval.c:4166
在堆栈的顶部,它看起来像是一个普通的 Python 线程在等待GIL。它看起来不起眼,所以你可以忽略它,在其他地方寻找线索。这正是我们在 2019 年所做的
更全面地查看堆栈的其余部分,尤其是第 9 帧和第 10 帧:
#9 0x00007f548ba99dc6 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
#10 0x00007f548badd4a5 in ?? () from /usr/lib/x86_64-linux-gnu/libcuda.so
在这一点上,事情可能看起来更加令人困惑。线程 1 正在锁定libcuda.so内部构件。如果不能访问 CUDA 源代码,调试将很困难
进一步检查 Thread 8 的堆栈,可以看到两个提供提示的帧:
#13 0x00007f549361109e in _call_function_pointer (argcount=6, resmem=0x7f53f6043400, restype=<optimized out>, atypes=0x7f53f6043380, avalues=0x7f53f60433c0, pProc=0x7f548bad61f0 <cuOccupancyMaxPotentialBlockSize>, flags=4353) at /usr/local/src/conda/python-3.6.11/Modules/_ctypes/callproc.c:831
#14 _ctypes_callproc (pProc=0x7f548bad61f0 <cuOccupancyMaxPotentialBlockSize>, argtuple=<optimized out>, flags=4353, argtypes=<optimized out>, restype=<_ctypes.PyCSimpleType at remote 0x562396b4d588>, checker=0x0) at /usr/local/src/conda/python-3.6.11/Modules/_ctypes/callproc.c:1195
综上所述,两个线程共享一个锁。线程 8 正在尝试获取 GIL ,并对进行 CUDA 调用cuOccupancyMaxPotentialBlockSize.
然而libcuda.so对 Python 一无所知,那么它为什么要试图获得 GIL 呢?
的文档cuOccupancyMaxPotentialBlockSize显示它需要回调。回调是可以向另一个函数注册的函数,以便在某个时间点执行,从而在该预定义点有效地执行用户定义的操作。
这很有趣。接下来,找出那个电话是从哪里打来的。通过一堆又一堆的代码—— cuDF 、 Dask 、 RMM 、 CuPy 和 Numba ,可以显式调用cuOccupancyMaxPotentialBlockSize在 0 . 45 版本的 Numba 中:
def get_max_potential_block_size(self, func, b2d_func, memsize, blocksizelimit, flags=None):
"""Suggest a launch configuration with reasonable occupancy.
:param func: kernel for which occupancy is calculated
:param b2d_func: function that calculates how much per-block dynamic shared memory 'func' uses based on the block size.
:param memsize: per-block dynamic shared memory usage intended, in bytes
:param blocksizelimit: maximum block size the kernel is designed to handle"""
gridsize = c_int()
blocksize = c_int()
b2d_cb = cu_occupancy_b2d_size(b2d_func)
if not flags:
driver.cuOccupancyMaxPotentialBlockSize(byref(gridsize), byref(blocksize),
func.handle,
b2d_cb,
memsize, blocksizelimit)
else:
driver.cuOccupancyMaxPotentialBlockSizeWithFlags(byref(gridsize), byref(blocksize),
func.handle, b2d_cb,
memsize, blocksizelimit, flags)
return (gridsize.value, blocksize.value)
此函数在中调用numba/cuda/compiler:
def _compute_thread_per_block(self, kernel):
tpb = self.thread_per_block
# Prefer user-specified config
if tpb != 0:
return tpb
# Else, ask the driver to give a good cofnig
else:
ctx = get_context()
kwargs = dict(
func=kernel._func.get(),
b2d_func=lambda tpb: 0,
memsize=self.sharedmem,
blocksizelimit=1024,
)
try:
# Raises from the driver if the feature is unavailable
_, tpb = ctx.get_max_potential_block_size(**kwargs)
except AttributeError:
# Fallback to table-based approach.
tpb = self._fallback_autotune_best(kernel)
raise
return tpb
仔细查看的函数定义_compute_thread_per_block,您可以看到一个写为 Python lambda 的回调:b2d_func=lambda tpb: 0.
啊哈!在这个 CUDA 调用的中间,回调函数必须获取 Python GIL 才能执行只返回 0 的函数。这是因为执行任何 Python 代码都需要 GIL ,并且在任何给定的时间点只能由单个线程拥有
用纯 C 函数代替它就解决了这个问题。你可以用 Numba 从 Python 中编写一个纯 C 函数!
@cfunc("uint64(int32)")
def _b2d_func(tpb):
return 0
b2d_func=_b2d_func.address
此修复程序已提交并最终合并到Numba PR #4581Numba 中的这五行代码更改最终解决了几个人在数周的调试中大量编写代码的问题。
调试经验教训
在各种调试过程中,甚至在错误最终解决后,我们都反思了这个问题,并得出了以下教训:
- 不要实现死锁。真的,不要!
- 不要将 Python 函数作为回调传递给 C / C ++函数,除非您绝对确定在执行回调时 GIL 不会被另一个线程占用。即使你绝对确定 GIL 没有被拿走,也要进行双重和三次检查。你不想在这里冒险。
- 使用您所掌握的所有工具。尽管您主要编写 Python 代码,但在用其他语言(如 C 或 C ++)编写的库中仍然可以发现错误。 GDB 在调试 C 和 C ++以及 Python 方面功能强大。有关详细信息,请参阅GDB 支持.
Bug 复杂性与代码修复复杂性相比
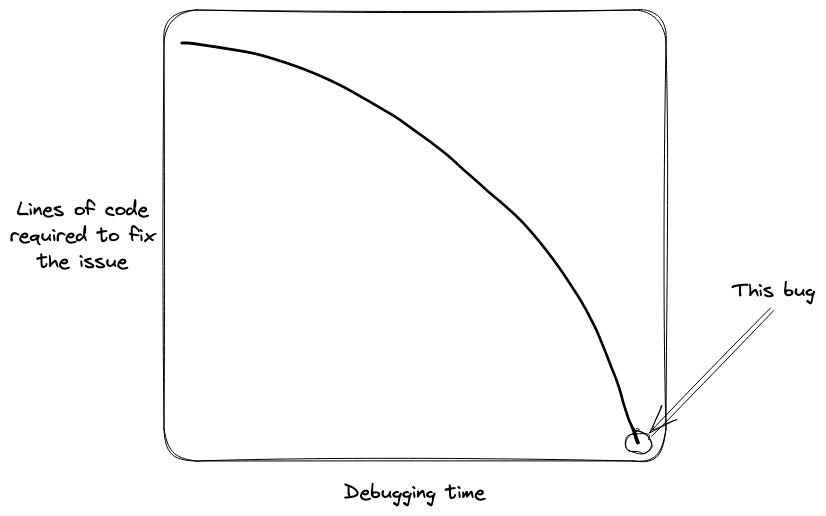
图 2 中的图表示了一种常见的调试模式:理解和发现问题所花费的时间很长,而更改的程度很低。这种情况就是这种模式的一个理想例子:调试时间趋于无穷大,编写或更改的代码行趋于零。
结论
调试可能会让人望而生畏,尤其是当您无法访问所有源代码或一个好的 IDE 时。尽管 GDB 看起来很可怕,但它也同样强大。然而,随着时间的推移,有了正确的工具、经验和知识,看似不可能理解的问题可以被不同程度的细节看待,并得到真正的理解
这篇文章一步一步地概述了一个 bug 是如何花了一个多方面的开发团队几十个工程小时来解决的。有了这个概述和对 GDB 、多线程和死锁的一些理解,您可以使用新获得的技能来帮助解决中等复杂的问题。
最后,永远不要局限于你已经知道的工具。如果你知道 PDB ,接下来试试 GDB 。如果您对操作系统调用堆栈有足够的了解,请尝试探索寄存器和其他 CPU 属性。这些技能当然可以帮助所有领域和编程语言的开发人员更加意识到潜在的陷阱,并提供独特的机会来防止愚蠢的错误成为噩梦般的怪物。



