本项目为CUDA官方手册的中文翻译版,有个人翻译并添加自己的理解。主要介绍CUDA编程模型和接口。
1.1 我们为什么要使用GPU
GPU(Graphics Processing Unit)在相同的价格和功率范围内,比CPU提供更高的指令吞吐量和内存带宽。许多应用程序利用这些更高的能力,在GPU上比在CPU上运行得更快(参见GPU应用程序)。其他计算设备,如FPGA,也非常节能,但提供的编程灵活性要比GPU少得多。
GPU和CPU在功能上的差异是因为它们的设计目标不同。虽然 CPU 旨在以尽可能快的速度执行一系列称为线程的操作,并且可以并行执行数十个这样的线程。但GPU却能并行执行成千上万个(摊销较慢的单线程性能以实现更大的吞吐量)。
GPU 专门用于高度并行计算,因此设计时更多的晶体管用于数据处理,而不是数据缓存和流量控制。
将更多晶体管用于数据处理,例如浮点计算,有利于高度并行计算。GPU可以通过计算隐藏内存访问延迟,而不是依靠大数据缓存和复杂的流控制来避免长时间的内存访问延迟,这两者在晶体管方面都是昂贵的。
1.2 CUDA®:通用并行计算平台和编程模型
2006 年 11 月,NVIDIA® 推出了 CUDA®,这是一种通用并行计算平台和编程模型,它利用 NVIDIA GPU 中的并行计算引擎以比 CPU 更有效的方式解决许多复杂的计算问题。
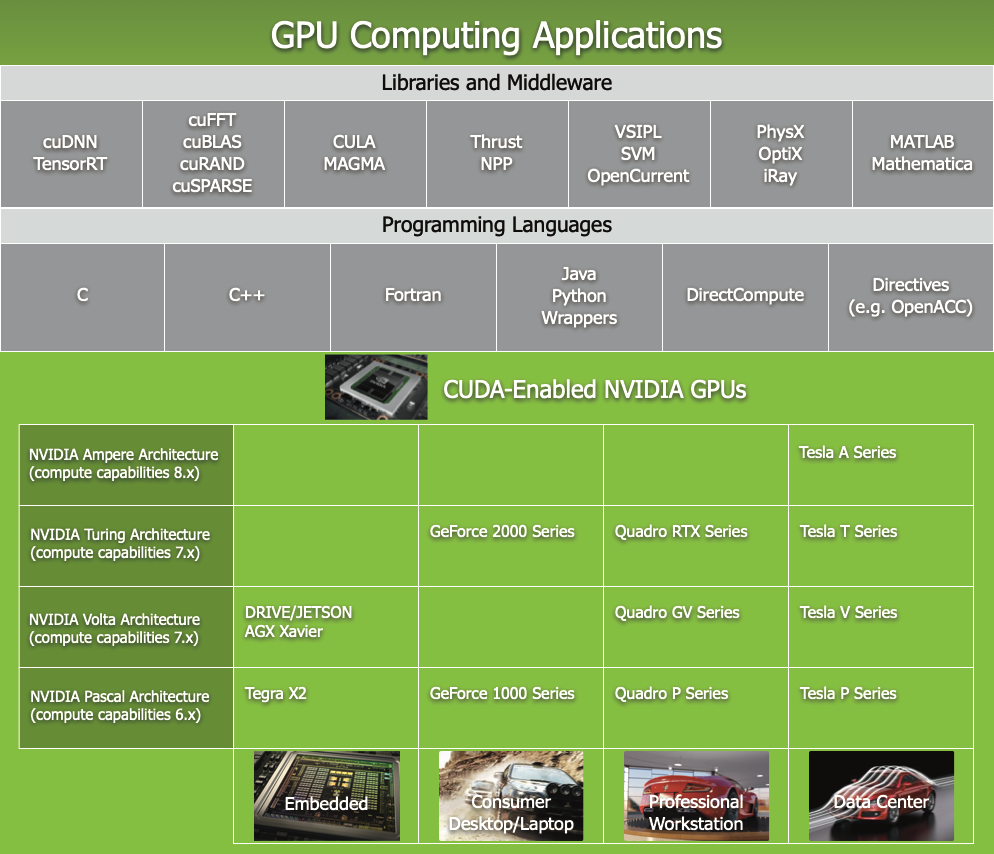
CUDA 附带一个软件环境,允许开发人员使用 C++ 作为高级编程语言。 如下图所示,支持其他语言、应用程序编程接口或基于指令的方法,例如 FORTRAN、DirectCompute、OpenACC。
1.3 可扩展的编程模型
多核 CPU 和众核 GPU 的出现意味着主流处理器芯片现在是并行系统。挑战在于开发能够透明地扩展可并行的应用软件,来利用不断增加的处理器内核数量。就像 3D 图形应用程序透明地将其并行性扩展到具有广泛不同内核数量的多核 GPU 一样。
CUDA 并行编程模型旨在克服这一挑战,同时为熟悉 C 等标准编程语言的程序员保持较低的学习曲线。
其核心是三个关键抽象——线程组的层次结构、共享内存和屏障同步——它们只是作为最小的语言扩展集向程序员公开。
这些抽象提供了细粒度的数据并行和线程并行,嵌套在粗粒度的数据并行和任务并行中。它们指导程序员将问题划分为可以由线程块并行独立解决的粗略子问题,并将每个子问题划分为可以由块内所有线程并行协作解决的更精细的部分。
这种分解通过允许线程在解决每个子问题时进行协作来保留语言表达能力,同时实现自动可扩展性。实际上,每个线程块都可以在 GPU 内的任何可用multiprocessor上以乱序、并发或顺序调度,以便编译的 CUDA 程序可以在任意数量的多处理器上执行,如下图所示,并且只有运行时系统需要知道物理multiprocessor个数。
这种可扩展的编程模型允许 GPU 架构通过简单地扩展multiprocessor和内存分区的数量来跨越广泛的市场范围:高性能发烧友 GeForce GPU ,专业的 Quadro 和 Tesla 计算产品 (有关所有支持 CUDA 的 GPU 的列表,请参阅支持 CUDA 的 GPU)。
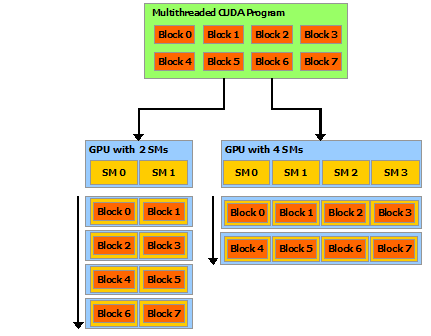
注意:GPU 是围绕一系列流式多处理器 (SM: Streaming Multiprocessors) 构建的(有关详细信息,请参阅硬件实现)。 多线程程序被划分为彼此独立执行的线程块,因此具有更多multiprocessor的 GPU 将比具有更少多处理器的 GPU 在更短的时间内完成程序执行。