
CUDA 内核函数参数通过恒定存储器传递给设备,并且被限制为 4096 字节。 CUDA 12.1 将此参数限制从 4096 字节增加到 32764 字节,在所有设备架构上都有效,包括 NVIDIA Volta 及以上。
以前,传递超过 4096 字节的内核参数需要通过将多余的参数复制到常量内存中来绕过内核参数限制cudaMemcpyToSymbol或cudaMemcpyToSymbolAsync,如下面的片段所示。
#define TOTAL_PARAMS (8000) // ints
#define KERNEL_PARAM_LIMIT (1024) // ints
#define CONST_COPIED_PARAMS (TOTAL_PARAMS - KERNEL_PARAM_LIMIT)
__constant__ int excess_params[CONST_COPIED_PARAMS];
typedef struct {
int param[KERNEL_PARAM_LIMIT];
} param_t;
__global__ void kernelDefault(__grid_constant__ const param_t p,...) {
// access <= 4,096 parameters from p
// access excess parameters from __constant__ memory
}
int main() {
param_t p;
int *copied_params = (int*)malloc(CONST_COPIED_PARAMS * sizeof(int));
cudaMemcpyToSymbol(excess_params,
copied_params,
CONST_COPIED_PARAMS * sizeof(int),
0,
cudaMemcpyHostToDevice);
kernelDefault<<<GRIDDIM,BLOCKDIM>>>(p,...);
cudaDeviceSynchronize();
}
这种方法限制了可用性,因为您必须显式管理常量内存分配和副本。复制操作还增加了显著的延迟,降低了接受大于 4096 字节参数的延迟绑定内核的性能。
从 CUDA 12 . 1 开始,您现在可以在 NVIDIA Volta 及更高版本上传递多达 32764 个字节作为内核参数,从而得到下面第二个片段中所示的简化实现。
#define TOTAL_PARAMS (8000) // ints
typedef struct {
int param[TOTAL_PARAMS];
} param_large_t;
__global__ void kernelLargeParam(__grid_constant__ const param_large_t p,...) {
// access all parameters from p
}
int main() {
param_large_t p_large;
kernelLargeParam<<<GRIDDIM,BLOCKDIM>>>(p_large,...);
cudaDeviceSynchronize();
}
请注意,在前面的两个示例中,内核参数都用__grid_constant__限定符,以指示它们是只读的。
工具包和驱动程序兼容性
注意,使用 CUDA Toolkit 12.1 和 R530 驱动程序或更高版本编译、启动和调试具有大内核参数的内核是必需的。如果在较旧的驱动程序上尝试启动,CUDA 将发布 CUDA_ERROR_NOT_SUPPORTED 错误。
支持的体系结构
更高的参数限制适用于所有架构,包括 NVIDIA Volta 及以上版本。在低于 NVIDIA Volta 的体系结构上,参数限制保持在 4096 字节
CUDA 工具包修订版之间的链接兼容性
当链接设备对象时,如果至少有一个设备对象包含具有更高参数限制的内核,则必须重新编译设备源中的所有对象,并使用 CUDA Toolkit 12.1 将它们链接在一起。否则将导致链接器错误。
例如,考虑两个设备对象 a.o 和 b.o 链接在一起的场景。如果 a.o 或 b.o 至少包含一个具有较高参数限制的内核,则必须重新编译相应的源并将生成的对象链接在一起。
使用大内核参数可节省性能
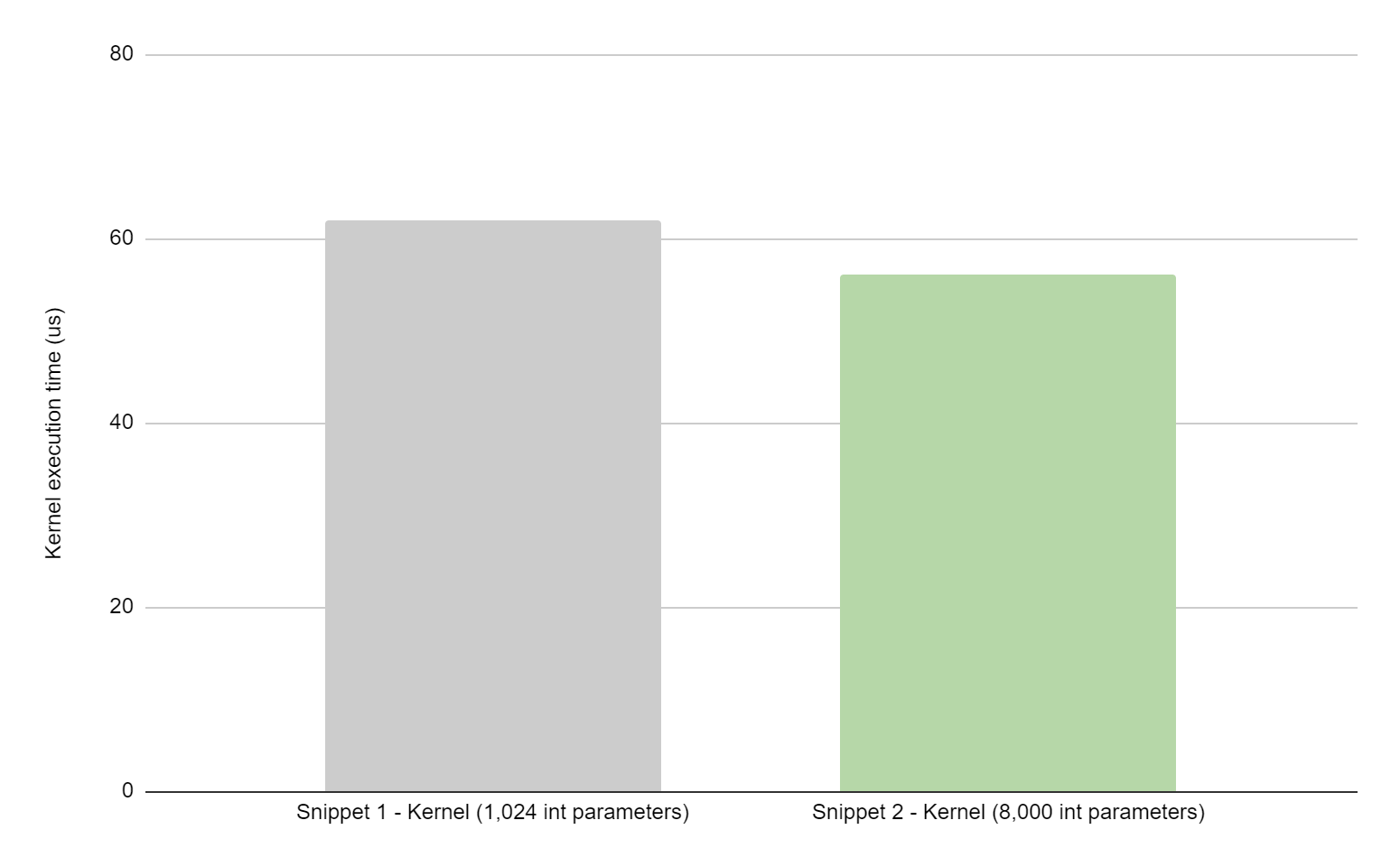
图 1 比较了上面提供的两个代码片段在单个代码上的性能,在 NVIDIA H100 系统上测量了超过 1000 次迭代。在本例中,通过避免常量拷贝,使应用程序运行时总体节省了 28% 。图 2 显示,对于相同的代码段,使用 NVIDIA Nsight Systems 后,内核执行时间提高了 9% 。
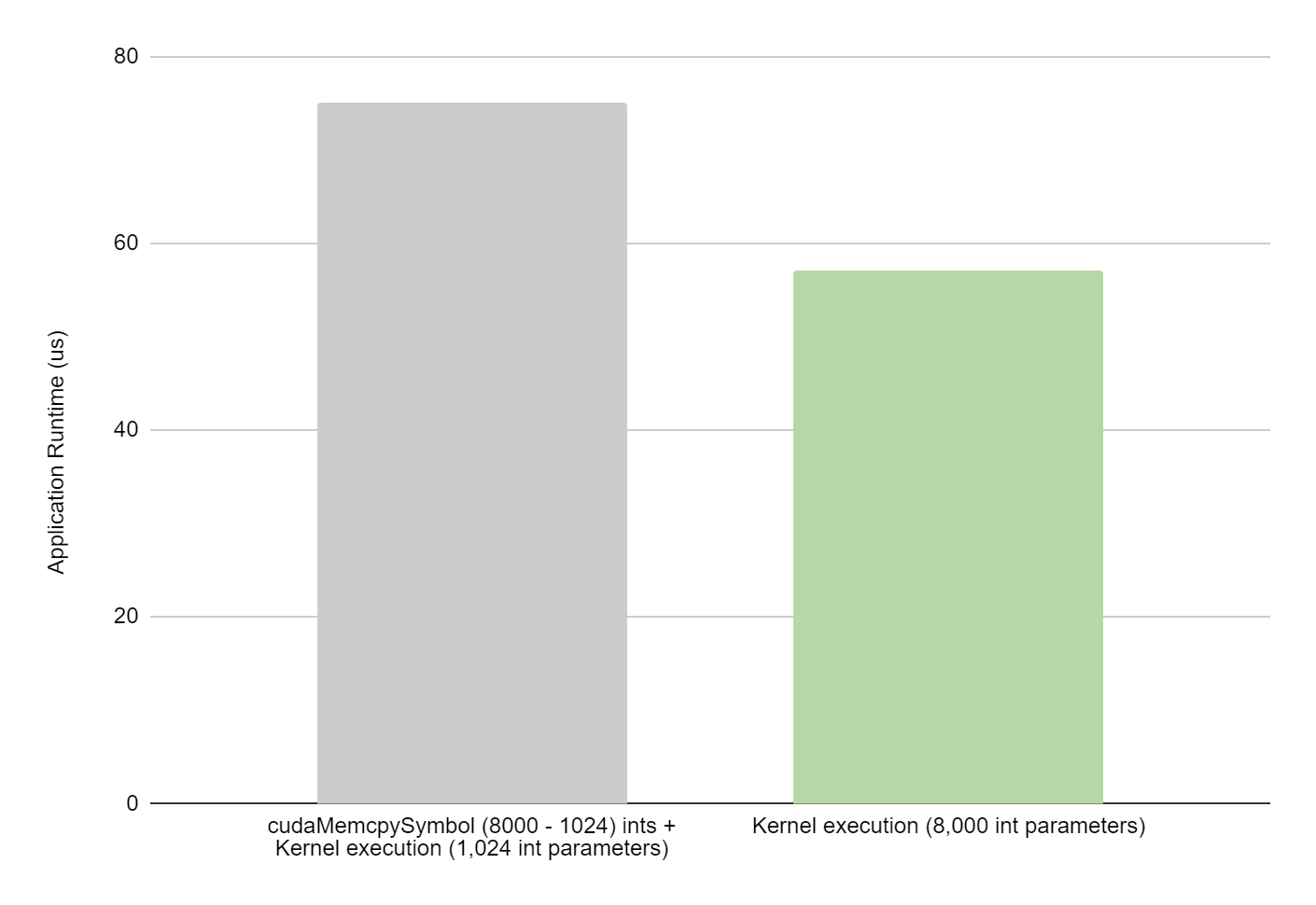
对于这两个图像,灰色条显示了内核的执行时间,其中 1024 个整数作为内核参数传递,其余整数使用恒定内存传递(代码片段 1 )。绿条显示了内核的执行时间,其中 8000 个整数作为内核参数传递(代码片段 2 )。两个内核都累积了 8000 个整数。
请注意,如果省略 __grid_constant__限定符,然后从内核对其执行后续写入操作,自动复制到thread-local-memory被触发。这可能会抵消任何性能提升。
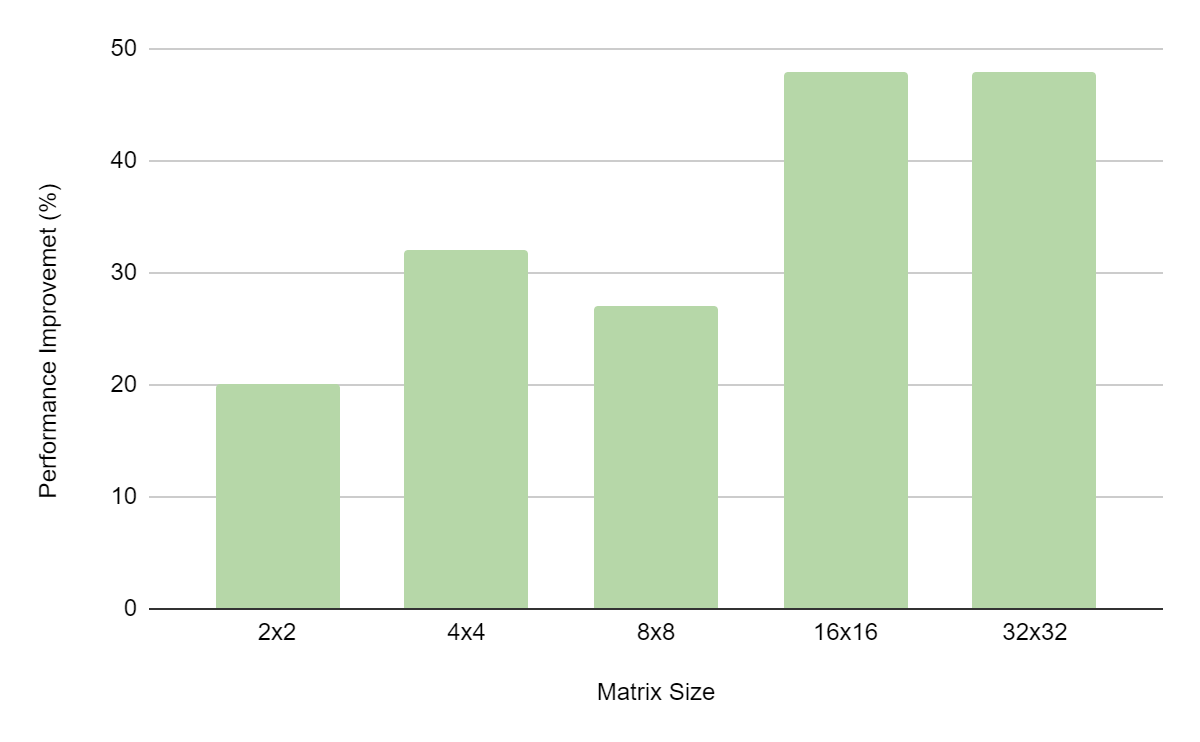
图 3 显示了使用 QUDA(一个用于在晶格量子色动力学中进行计算的 HPC 库)的结果。
本例中的参考内核执行批量矩阵乘法 X * a + Y ,其中 a 、 X 和 Y 是矩阵。内核参数存储 A 的系数。在 CUDA 12.1 之前,当系数超过 4096 字节的参数限制时,它们被显式复制到恒定内存中,大大增加了内核延迟。删除该副本后,可以观察到显著的性能改进(图 3 )。
总结
CUDA 12.1 为您提供了使用内核参数传递多达 32764 个字节的选项,可以利用这些参数简化应用程序并提升性能。要查看本文中引用的完整代码示例,请访问 NVIDIA/cuda-samples GitHub 。



