
CUDA Toolkit 12.0 引入了一个新的 nvJitLink 库,用于实时链接时间优化( JIT LTO )支持。在 CUDA 的早期,为了获得最大性能,开发人员必须在整个编程模式下将 CUDA 内核构建和编译为单个源文件。这限制了 SDK 和应用程序具有大量代码,跨越多个文件,需要从移植到 CUDA 进行单独编译。性能的提高与整个程序的编译不符。
随着 CUDA 工具包 11.2 的发布, NVCC 增加了对离线链接时间优化( LTO )的支持,以使单独编译的应用程序和库能够获得与从单个翻译单元编译的完全优化程序类似的 GPU 运行时性能。在某些情况下,据报告,性能增益约为 20% 或更高。要了解更多信息,请参见 Improving GPU Application Performance with NVIDIA CUDA 11.2 Device Link Time Optimization 。
在论文 Enhancements Supporting IC Usage of PEM Libraries on Next-Gen Platforms 中, Lawrence Livermore 国家实验室报告了通过离线 LTO 获得的性能改进,“在所有情况下都提供了加速;最大加速为 27.1% ”
CUDA Toolkit12.0 随着 JIT LTO 的正式引入,进一步扩展了 LTO 支持。这扩展了 LTO 使用运行时链接为应用程序提供的相同性能优势。
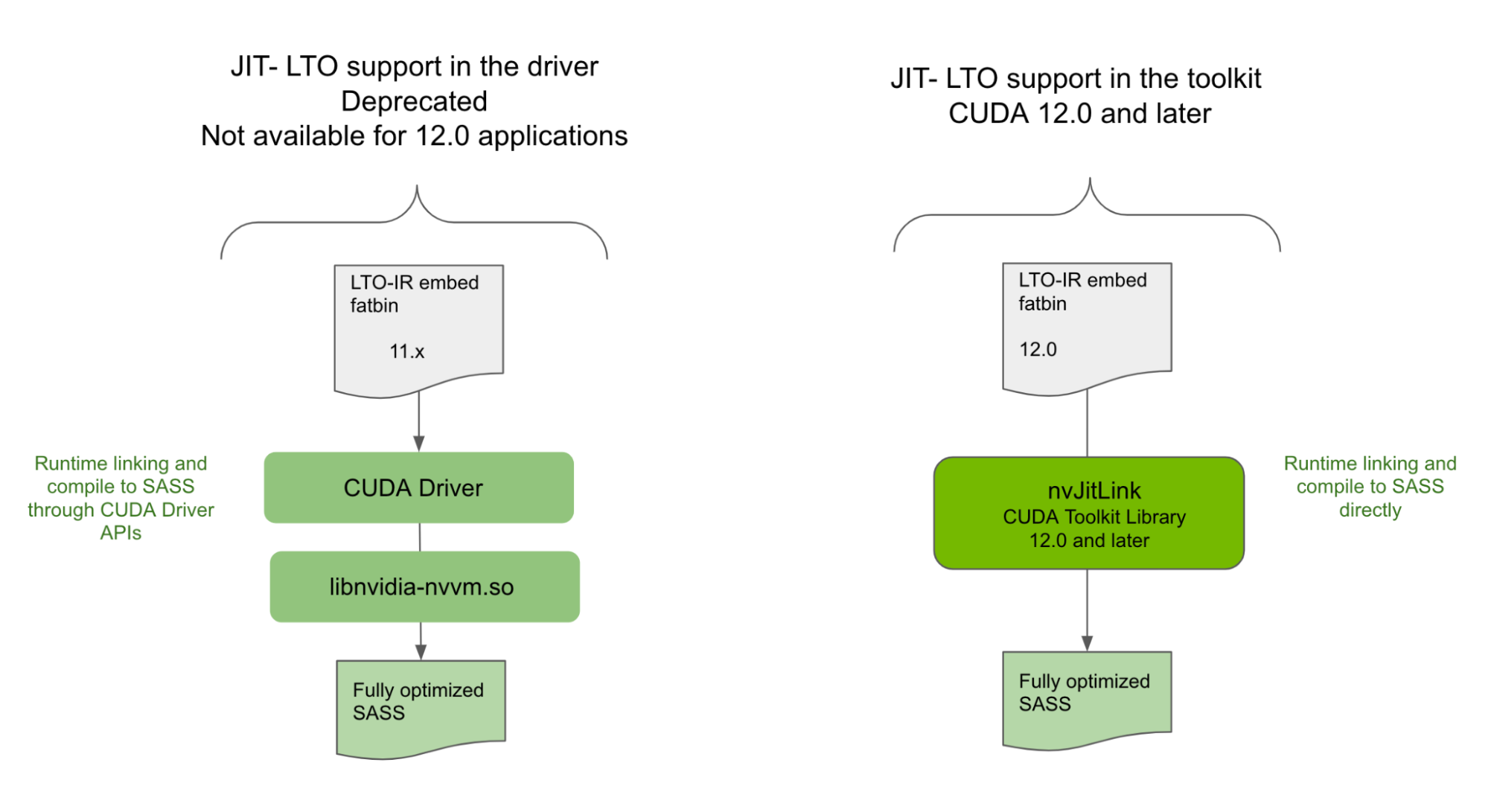
驱动程序中不支持 JIT LTO
虽然 JIT LTO 在 CUDA 11.4 中引入,但该版本的 JIT LTO 是通过 CUDA 驱动程序中的 cuLink API 实现的。它还依赖于使用 CUDA 驱动程序附带的单独优化器库在运行时执行链接时间优化。由于依赖于 CUDA 驱动程序, 11.4 中发布的 JIT LTO 没有提供次要版本兼容性,在某些情况下, CUDA 的向后兼容性保证。
因此,我们不得不重新考虑我们的设计,考虑到 CUDA 可以使用的各种部署场景以及库和独立应用程序的不同使用模型。
NVIDIA 正在弃用 CUDA 驱动程序中公开的 JIT LTO 功能,并将其作为 CUDA 12.0 及更高版本应用程序的 CUDA Toolkit 功能引入。有关详细信息,请参阅 CUDA 12.0 Release Notes 中的弃用通知。
新库提供 JIT LTO 支持
在 CUDA Toolkit12.0 中,您将发现一个新的库 nvJitLink ,该库带有 API ,可在运行时链接期间支持 JIT LTO 。 nvJitLink 库的用法类似于其他任何熟悉的库,如 nvrtc 和 nvptxcompiler 。将链接时间选项 -lnvJitLink 添加到构建选项中。 CUDA 工具包将提供适用于 Linux 、 Windows 和 Linux4Tegra 平台的 nvJitLink 库的静态和动态版本。
考虑到适当的因素,通过 nvJitLink 库公开的 JIT LTO 将符合 CUDA 兼容性保证。本文主要介绍通过 nvJitLink 库提供的 JIT LTO 功能,并在适当时强调与早期基于驱动器的实现的差异。我们将通过代码示例、兼容性保证和好处深入了解该功能的细节。作为额外的奖励,我们还包括了 NVIDIA 数学库计划如何利用该功能以及为什么要利用该功能的预览。
如何使 JIT LTO 工作
对于运行时 LTO ,请遵循下面概述的三个主要步骤。
1.创建稍后将引用的链接器句柄,以将相关对象链接在一起。您需要将-lto作为选项之一传递。
nvJitLinkCreate (&handle, numOptions, options)2.添加要与以下任一脚本链接在一起的对象:
nvJitLinkAddFile (handle, inputKind, fileName);输入类型通常可以是 ELF 、 PTX 、 fatbinary 、主机对象和主机库。对于 JIT LTO ,输入类型是 LTOIR 或包含 LTOIR 的格式,例如 fatbinary 。
3. 使用以下脚本执行实际链接:
nvJitLinkComplete (handle);您还可以检索生成的链接立方体。为此,需要显式的缓冲区分配。因此,您可以查询缓冲区的大小,并使用该缓冲区获取链接立方体。例如:
nvJitLinkGetLinkedCubinSize (handle, &size);
void *cubin = malloc(size);
nvJitLinkGetLinkedCubin(handle, cubin);LTO-IR 作为目标格式
JIT LTO 在基于 LLVM : LTO-IR 的中间表示格式上执行。此中间表示与 NVCC 生成的内容相同,并由离线 LTO 中的 nvlink 设备链接器使用( CUDA 11.2 )。 JIT LTO 的运行时链接输入需要采用 LTO-IR 格式,或以包含格式嵌入 LTO-IR 。例如, LTO-IR 可以存储在 fatbinary 中。
有两种方法可以为 nvJitLink 库的输入生成 LTO-IR ,如图 2 所示。
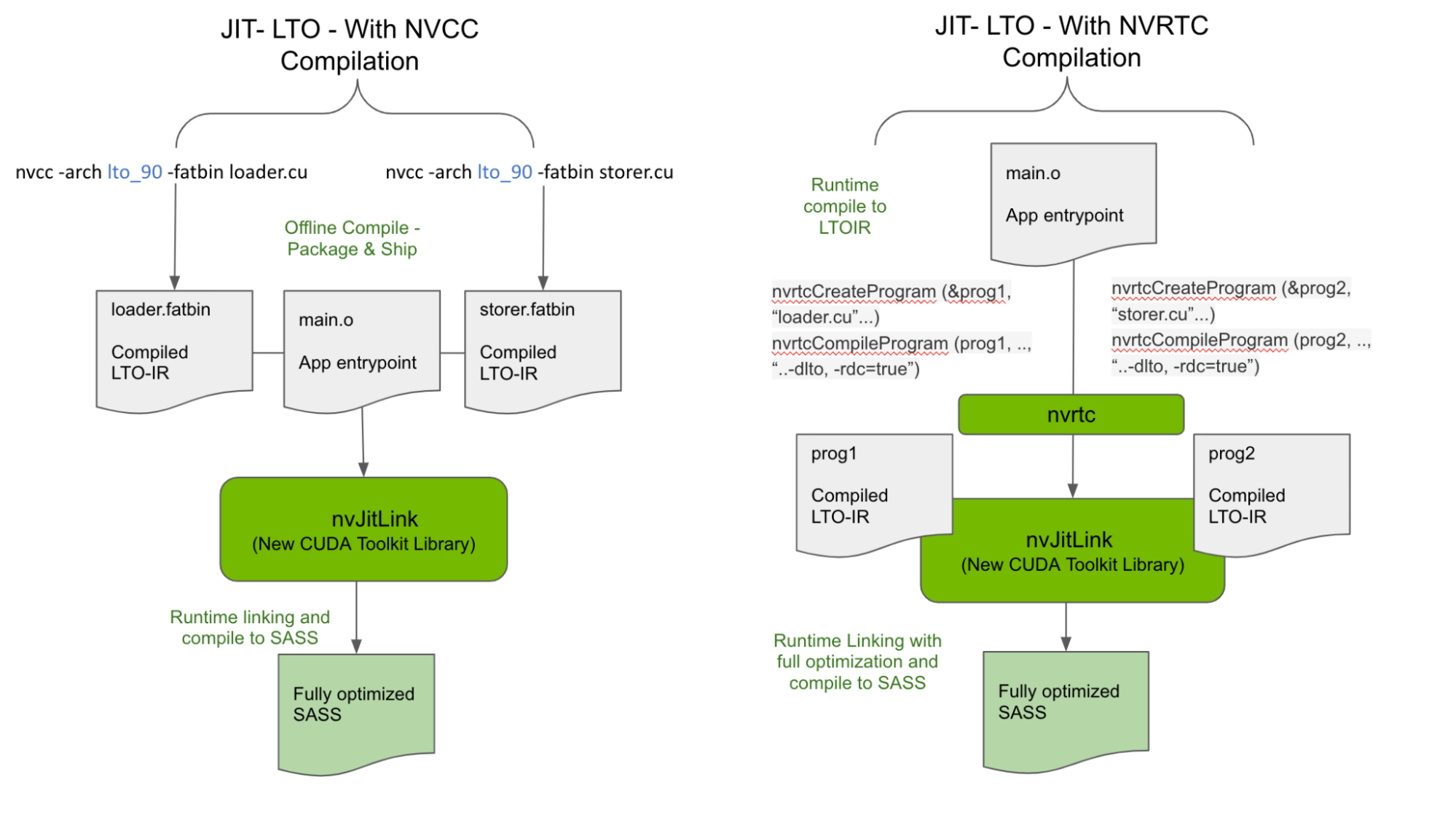
使用 NVCC 离线生成 LTO-IR
CUDA 11.2 介绍了 LTO-IR 格式,以及如何使用-dlto构建选项使用 NVCC 生成 LTO-IR 。我们将此功能保留为运行时 LTO-IR 对象有效链接的公认输入形式之一。因此,离线生成的 LTO-IR 对象存储在 fatbinary 中,如下面生成的loader.fatbin和storer.fatbin,可以在运行时链接起来,以获得 LTO 的最大性能优势。
nvcc -arch lto_90 -fatbin loader.cu // stores LTO-IR inside a fatbinary
nvcc -arch lto_90 -fatbin storer.cu因此,应用程序和库可以运送独立的 LTO-IR 片段,而不是 SASS 或 PTX ,以与运行时跨多个 LTO-IR 碎片执行的优化相链接。注意,在运送 LTO-IR 时,需要仔细考虑目标上的 nvJitLink 库版本。
char smbuf[16];
memset(smbuf,0,16);
sprintf(smbuf, "-arch=sm_%d", arch)
// Load the generated LTO IR and link them together
nvJitLinkHandle handle;
const char *lopts[] = {"-lto", smbuf};
nvJitLinkCreate (&handle, 2, lopts)
nvJitLinkAddFile (handle, NVJITLINK_INPUT_FATBIN, loader.fatbin);
nvJitLinkAddFile (handle, NVJITLINK_INPUT_FATBIN, storer.fatbin);
nvJitLinkComplete (handle);这种可能性打开了新的途径,通过在运行时合成内核而不影响性能,从而显著减少二进制大小。例如,用户内核和库内核的片段可以以 LTO-IR 格式单独发送,并在运行时 JIT 链接和编译到适合目标配置的单个内核。由于片段链接和优化在运行时发生,因此优化技术应用于用户和库代码,从而最大化性能。
在运行时生成 LTO-IR
除了上面描述并如图 2 所示的离线编译 – 运行时链接模型之外, LTO-IR 对象还可以在运行时使用 NVRTC 通过在编译时传递 -dlto 来完全构建,并在运行时通过 nvJitLinkAddData API 进行链接。 CUDA 示例的示例代码如下所示,并对使用 nvJitLink API 进行了相关修改。
nvrtcProgram prog1, prog2;
char *ltoIR1, *ltoIR2
...
...
/* Compile using –dlto option */
const char* opts = (“--gpu-architecture=compute_80”, “--dlto”, "--relocatable-device-code=true"});
NVRTC_SAFE_CALL(nvrtcCompileProgram(&prog1, 3, opts);
NVRTC_SAFE_CALL(nvrtcCompileProgram(&prog2, 3, opts);
...
nvrtcGetLTOIRSize(prog1, <oIR1Size);
ltoIR1 = malloc(ltoIR1Size);
nvrtcGetLTOIRSize(prog2, <oIR2Size);
ltoIR2 = malloc(ltoIR2Size);
nvrtcGetLTOIR(prog1, ltoIR1);
nvrtcGetLTOIR(prog2, ltoIR2);
char smbuf[16];
memset(smbuf,0,16);
sprintf(smbuf, "-arch=sm_%d", arch)
// Load the generated LTO IR and link them together
nvJitLinkHandle handle;
const char *lopts[] = {"-lto", smbuf};
nvJitLinkCreate(&handle, 2, lopts);
nvJitLinkAddData(handle, NVJITLINK_INPUT_LTOIR,
(void *)ltoIR1, ltoIR1Size, "lto_saxpy");
nvJitLinkAddData(handle, NVJITLINK_INPUT_LTOIR,
(void *)ltoIR2, ltoIR2Size,"lto_compute");
// Call to nvJitLinkComplete causes linker to link together the
// two LTO IR modules, do optimization on the linked LTO IR,
// and generate cubin from it.
nvJitLinkComplete(handle);
. . .
// get linked cubin
size_t cubinSize;
NVJITLINK_SAFE_CALL(handle, nvJitLinkGetLinkedCubinSize(handle, &cubinSize));
void *cubin = malloc(cubinSize);
NVJITLINK_SAFE_CALL(handle, nvJitLinkGetLinkedCubin(handle, cubin));
NVJITLINK_SAFE_CALL(handle, nvJitLinkDestroy(&handle));
delete[] ltoIR1;
delete[] ltoIR2;
// cubin is linked, so now load it
CUDA_SAFE_CALL(cuModuleLoadData(&module, cubin));
CUDA_SAFE_CALL(cuModuleGetFunction(&kernel, module, "saxpy"));要查看完整的示例,请访问 GitHub 上的 NVIDIA/cuda-samples 。
LTO-IR 对象兼容性
nvJitLink 库直接在 LTO-IR 上执行 JIT 链接以生成 SASS ,从而消除了链接对 CUDA 驱动程序版本的依赖。处理 LTO-IR 的是 nvJitLink 库的工具包版本,而重要的是编译的 LTO-IR 工具包版本。
nvJitLink 库将保留对旧 LTO-IR 的支持,但前提是它们在主要版本中。这种限制主要源于 LLVM 可能为功能或性能引入的任何破坏 ABI 的更改,这些更改可能在主要发布边界被吸收。
然而,即使在同一主要版本中,较旧的 nvJitLink 库也无法处理来自较新 NVCC 的 LTO-IR 。因此,目标系统上的 nvJitLink 库版本必须始终来自 CUDA 主要版本中用于生成任何单个模块 LTO-IR 的工具包的最高版本。
LTO-IR 目标仅在主要版本中与链路兼容。因此,为了跨主要版本链接对象,请在 PTX 或 SASS 中使用 ELF 级链接,遵循用例和安装配置。为了帮助此工作流, nvJitLink 还将支持 ELF 链接的新 API ,类似于驱动程序提供的 cuLinkAPI 。
CUDA 和 JIT LTO 兼容性
The GTC talk on JIT LTO use case 基于基于驱动程序的解决方案。由于 cuLinkAPI 和 nvvm 优化器依赖 CUDA 驱动程序, JIT LTO 的实现不支持 CUDA 的关键兼容性保证。
以下部分讨论了即使在使用 JIT LTO 时,如何使用新库来利用 CUDA 兼容性保证。
CUDA 次要版本兼容性
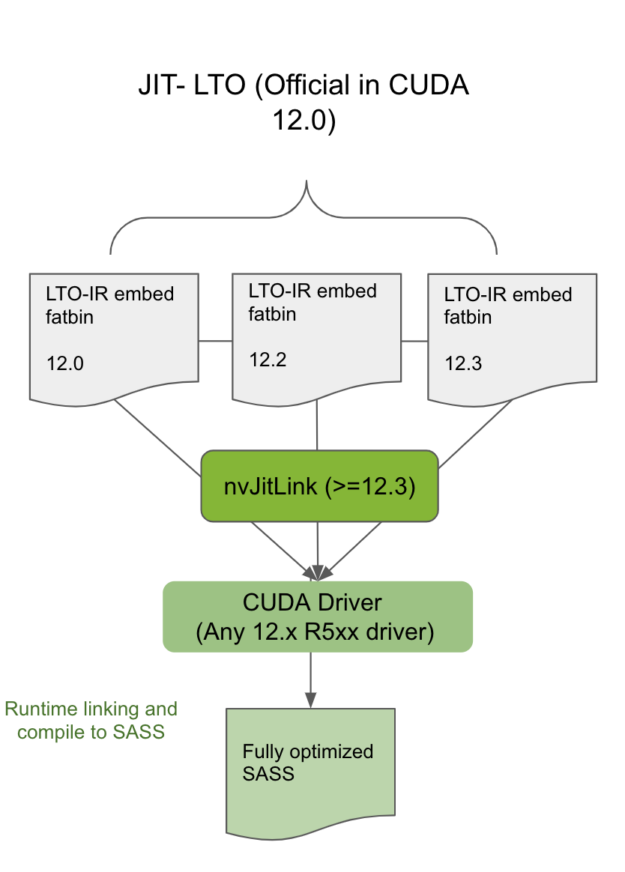
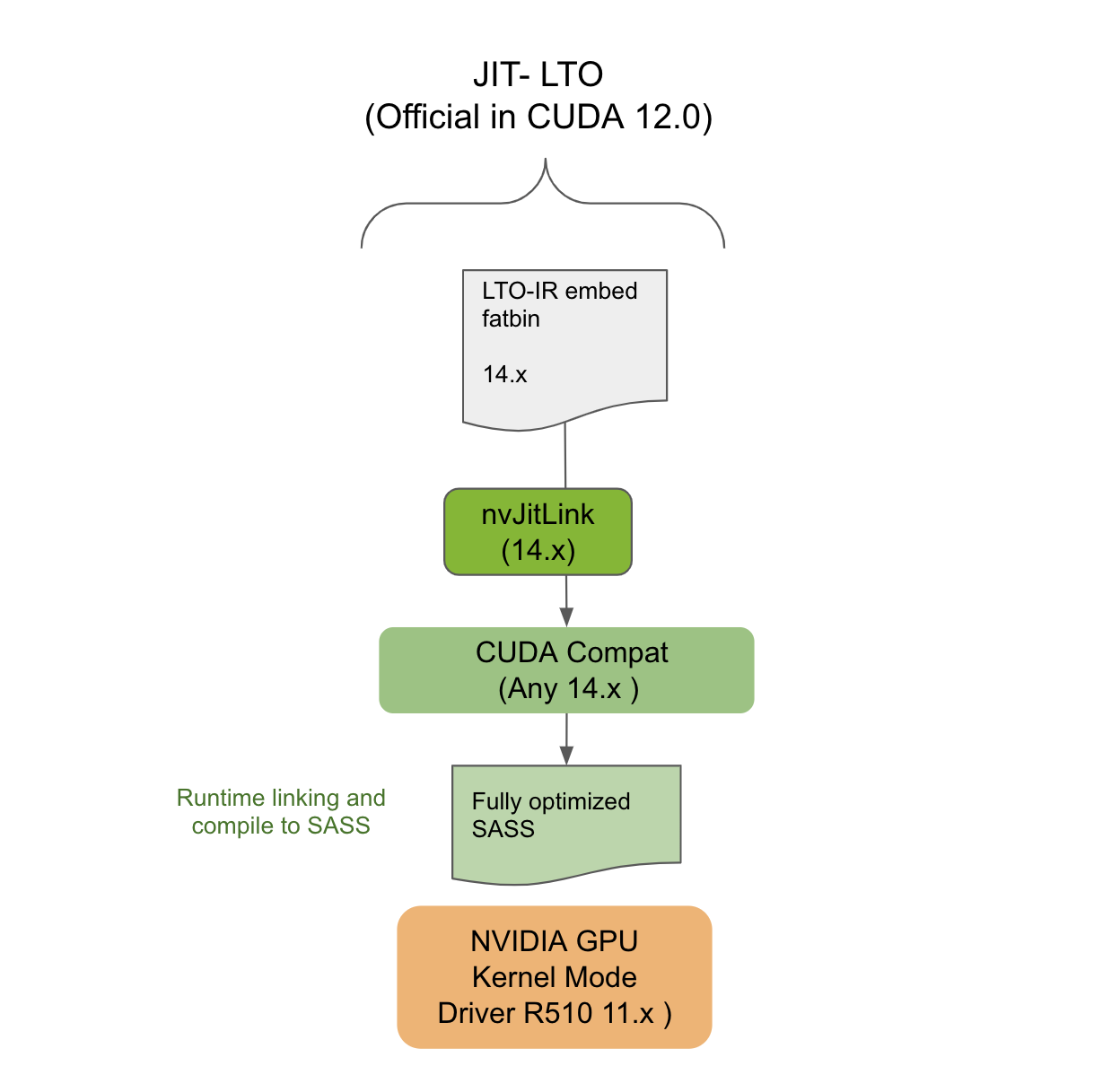
将编译并包含 LTO-IR 的模块与同一 CUDA 主要版本中相同或更新的工具包中的 nvJitLink 库相链接,将允许使用 JIT LTO 的此类应用程序在任何次要版本兼容的驱动程序上运行(图 3 )。从主要版本静态或动态链接 nvJitLink 库的最高版本。要确定哪个 CUDA 驱动程序是与工具包版本兼容的次要版本,请参见 CUDA 12.0 Release Notes 中的表 2 。
向后兼容性
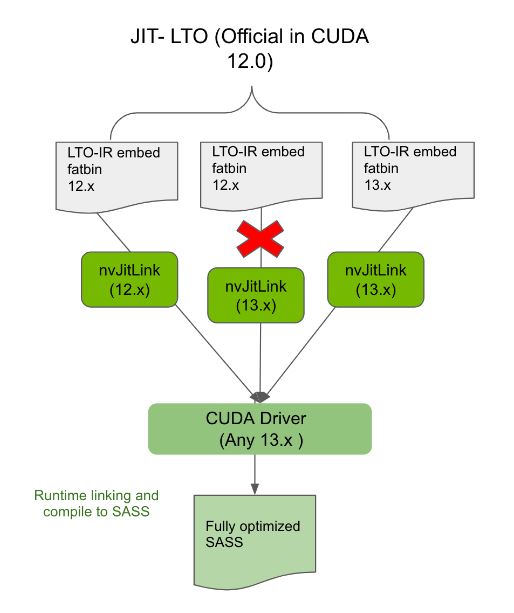
始终将编译为 LTO-IR 的应用程序与同一主要版本的兼容 nvJitLink 库链接,将确保此类应用程序在任何未来的 CUDA 驱动程序上向后兼容。例如,与 12.x nvJitLink 库链接的 12.x 应用程序将在 13.x 驱动程序上运行(图 4 )。
CUDA 前向兼容性
本节介绍了针对 JIT LTO 的 LTO-IR 应用程序如何仍然可以在 CUDA Forward Compatible deployment 中工作。前向兼容性旨在允许在 NVIDIA GPU 驱动程序安装上部署最新的 CUDA 应用程序,这些应用程序来自不同主要版本的旧版本分支。例如,驱动程序属于 10.x 时代,但应用程序来自 12.x 时代。
使用前向兼容性需要在目标系统上安装特殊的 CUDA 兼容包。 CUDA 兼容包与 NVIDIA GPU CUDA 驱动程序关联,但由工具包进行版本控制。为了使 CUDA 11.4 版本的 JIT LTO 工作, CUDA compat 包包含使 JIT LTO 在前向兼容模式下工作所需的组件。
然而,既然该特性是 CUDA Toolkit 新 nvJitLink 库的一部分,那么目标系统上该库的存在就像任何其他工具链依赖一样。它必须确保其在部署系统中的存在。 nvJitLink 库的版本必须再次与用于生成 LTO-IR 的 NVCC 或 NVRTC 的工具包版本相匹配。如图 5 所示, JIT LTO 将在前向兼容性模式下的系统上工作。
JIT LTO 和 cuFFT
本节介绍了像 cuFFT 这样的 NVIDIA 库如何利用 JIT LTO 。继续阅读,了解 cuFFT 用户的未来。
对于一些 CUDA 数学库,如 cuFFT ,二进制文件的大小是提供功能和性能时的限制因素。更高的性能通常意味着运送更多的专用内核,这反过来意味着运送更大的二进制文件。例如,为数据类型、问题大小、 GPU 和转换( R2C 、 C2R 、 C2C )的每种组合提供专用内核可能会导致二进制大小大于所有数学库的总和。因此,在决定装运哪些内核时必须做出决定。
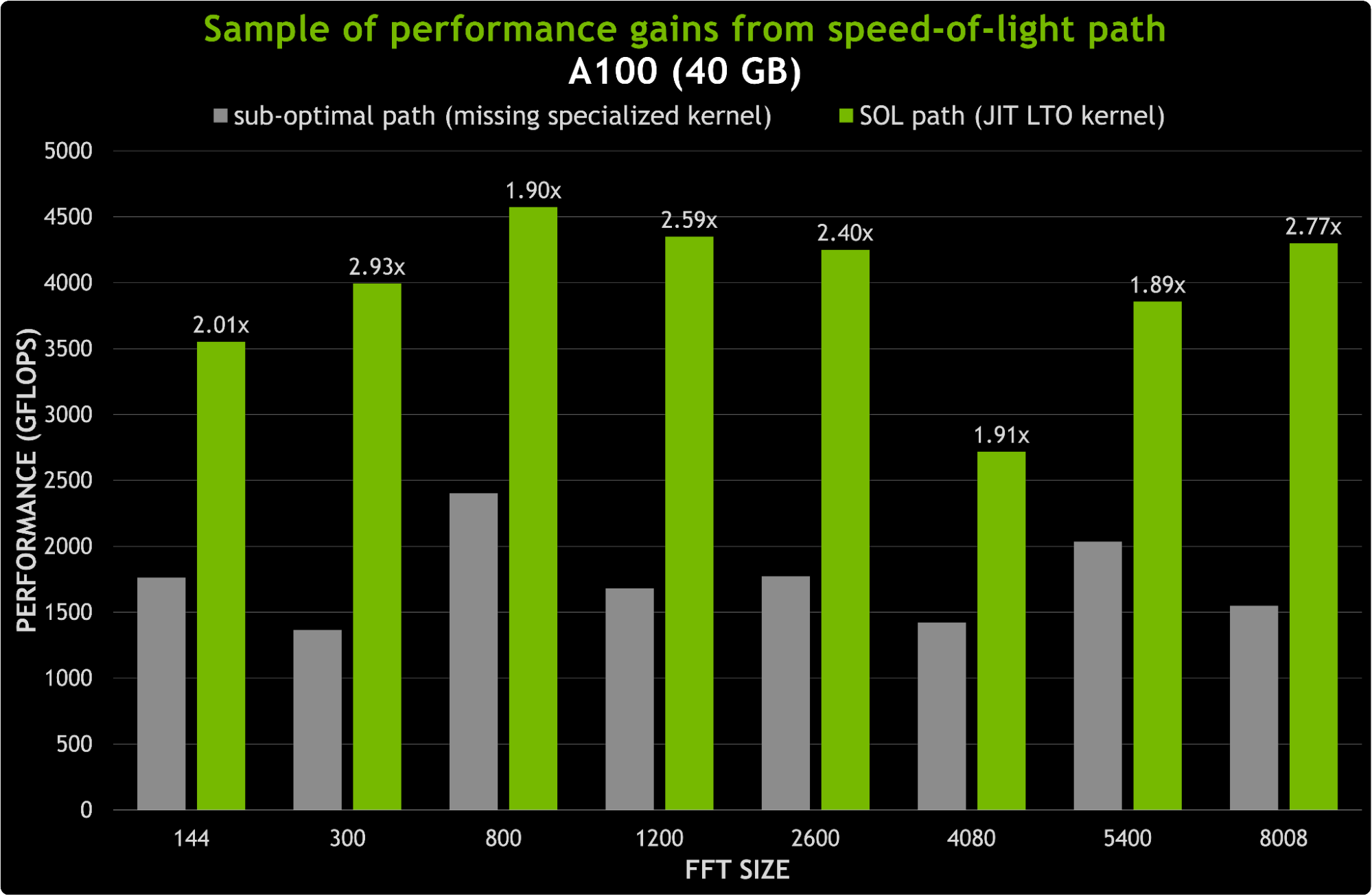
JIT LTO 通过使 cuFFT 库能够在运行时为任何参数组合构建 LTO 优化的光速( SOL )内核,最大限度地减少了对二进制大小的影响。这是通过运送 FFT 内核的构建块而不是专门的 FFT 内核来实现的。图 6 显示了用新的 JIT LTO 内核替换次优路径的可能加速。对于 8K 以下的尺寸,加速可以达到 3 倍。
理想的应用是在 cuFFT 内核中加入用户回调函数。使用 JIT LTO 专门化内核消除了回调内核和非回调内核之间的区别。
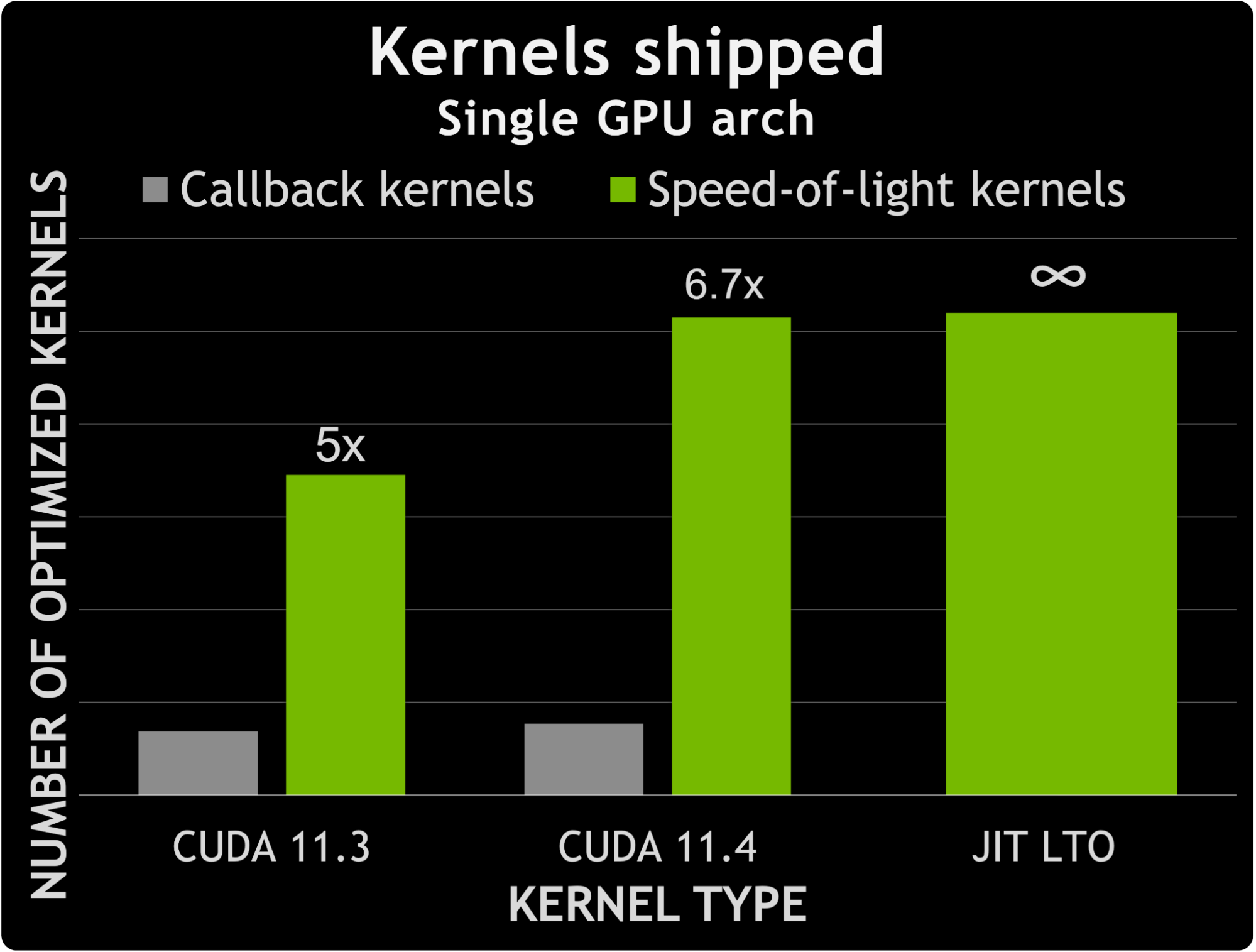
在 CUDA 11.3 和 CUDA 11.4 之间, cuFFT 发现非回调 SOL 内核的数量增加了约 50% 。相比之下,能够处理用户回调的内核数量增加了约 12% 。这意味着专用非回调内核数与专用回调内核数之间的差异增加了 1.6 倍。
图 7 显示了回调内核数量与 CUDA 11.3 和 11.4 附带的专用内核数量之间的比较。它还提示了利用 JIT LTO 处理用户回调所提供的可能性。实际上,专用回调内核的数量增加了近 7 倍,而不会增加内核数量所带来的二进制大小。
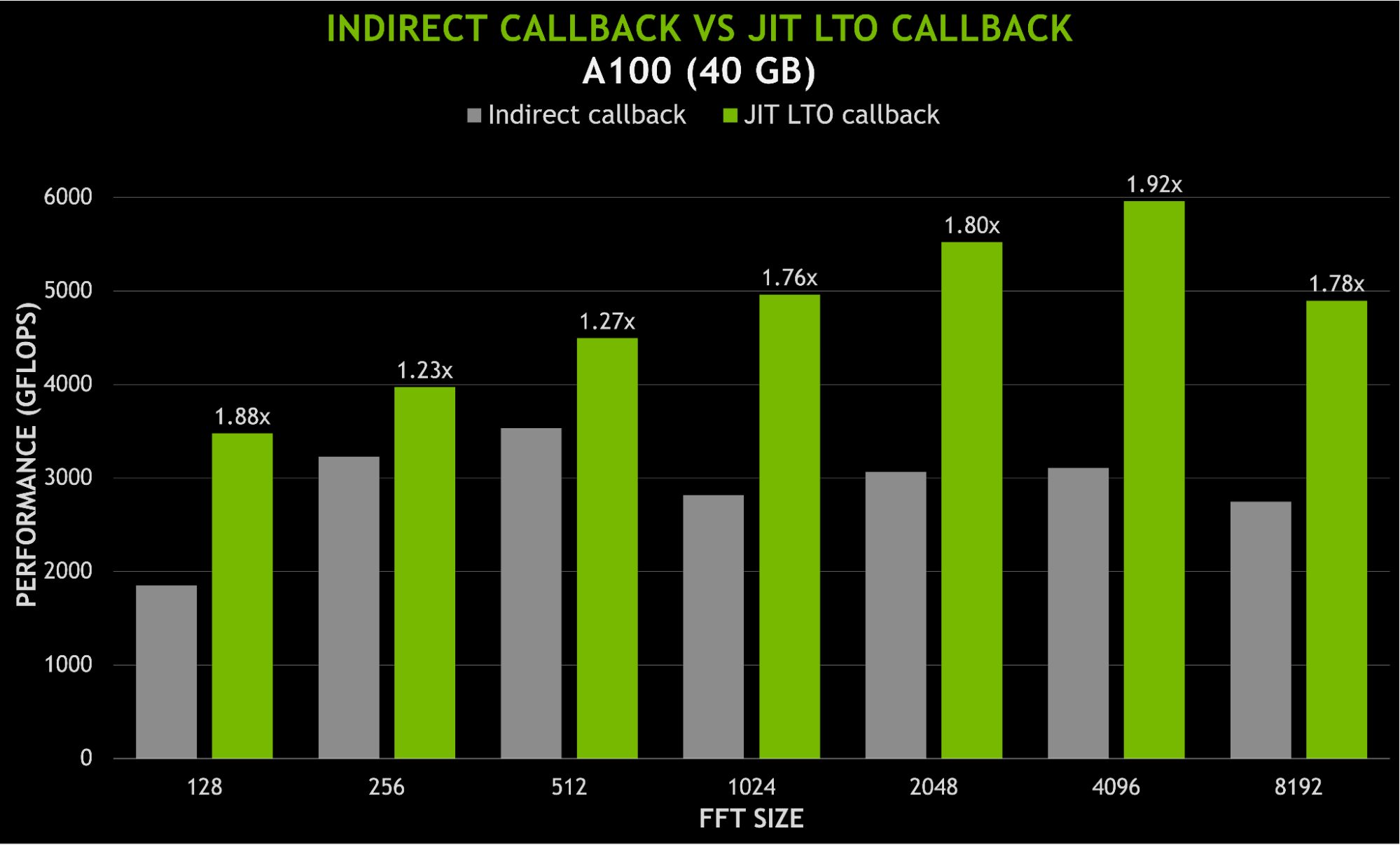
使用 JIT LTO 的另一个好处是能够将用户代码与库内核链接在一起,而不需要针对静态库进行单独的脱机设备链接。由于链接时间优化(尤其是内联),间接调用用户函数所产生的任何开销都应该最小化。图 8 显示了当使用 JIT LTO 回调而不是间接函数调用时,速度提高了近 2 倍。
结论
在较新的形式中, JIT LTO 应该为应用程序开发人员、库开发人员和系统管理员提供更多好处。表 1 突出显示了支持的不同场景,以及在使用 LTO (特别是 JIT LTO )时需要记住的约束。
| Within a minor release | Across major release | |
| LTO-IR | Link compatible | Not link compatible. Link at PTX or SASS Level. |
| nvJitLink library | Use the highest version of the linking objects | Not compatible for linking. Runtime JIT to link compatible object PTX or SASS. |
CUDA 兼容性和易部署性以及不可协商的性能优势将以新的形式定义 JIT LTO 。在未来的 CUDA 版本中,为了进一步增强 JIT LTO 的性能,我们正在考虑通过缓存和其他方案来减少运行时链接开销。




