在过去的几个月里,我们中的许多人已经习惯于通过视频电话看医生。这当然很方便,但在通话结束后,医生的重要建议就开始溜走了。我需要服用什么新药?有什么副作用需要注意吗?
Conversational AI 可以帮助构建一个应用程序来转录语音,并突出该转录本中的重要短语。 NVIDIA Riva 是一款 SDK ,它可以减少您构建和部署可用于这些任务的最先进的深度学习模型的时间。
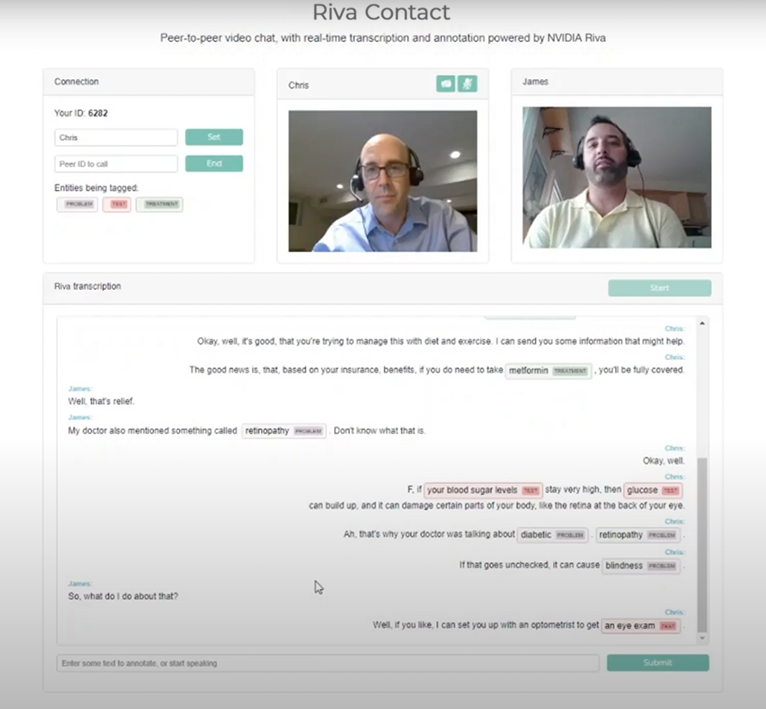
在本文中,我们将向您展示如何构建一个 web 应用程序,该应用程序可以从实时视频聊天中转录语音,并在转录本中标记关键短语。视频聊天使用 PeerJS ,这是一个基于 WebRTC 的开源对等聊天框架。对于实时转录,您使用 Riva 中的自动语音识别( ASR )。标记成绩单中的关键短语使用命名实体识别( NER ),也来自 Riva 。我们还向您展示了如何使用来自医学领域的数据来训练 NER 模型。虽然我们确实包含代码示例,但为了清晰起见,我们省略了一些技术细节,因此我们鼓励您看看 Riva Samples Docker 容器。
该应用程序的起点是一个简单的点对点视频通话 web 应用程序。它包含以下资源:
- 一个 HTML 页面
- 一个客户端 JavaScript 文件
- 一个服务器 JavaScript 文件,用于托管资产并设置对等连接
我们将教程保持在最低限度,因此请记住,真正的应用程序应该更加复杂。它将包括身份和会话管理、警报、分析和更强大的网络处理。

在本文中,我们将重点介绍如何将 ASR 和 NLP 功能添加到 web 应用程序中,并跳过有关应用程序结构的一些细节。总结一下这个应用程序,它是一个简单的服务器,在 Node . js 中实现,它使用 Express 托管 web 资产,使用 PeerJ 帮助客户端在点对点 WebRTC 视频聊天中相互连接。在客户机上,浏览器加载网页,然后与服务器对话以帮助建立与对等方的连接。建立对等连接后,两个客户端直接相互通信。视频不再通过服务器路由。
此时,用户可以加载网页,联系其他用户,并进行实时视频聊天。
添加 ASR 和 NLP
NVIDIA Riva 是一个 SDK ,可快速部署高性能对话式人工智能服务。 Riva quick start 参考资料提供了一个简单易懂的指南,用于部署到 Riva 推理服务器。将资源下载到服务器后,可以归结为几个基本步骤:
- 在
config.sh中配置部署。 - 通过运行
riva_init.sh下载、优化和准备模型。 - 使用
riva_start.sh启动 Riva 技能服务器。
服务器启动后,它会创建几个 gRPC 端点,以帮助应用程序与 Riva 通信。为了确保一切正常工作,请尝试从设置 Riva 的服务器启动客户端容器。致电 riva_start_client.sh ,然后查看示例客户端,浏览笔记本,了解 Riva 提供的功能。
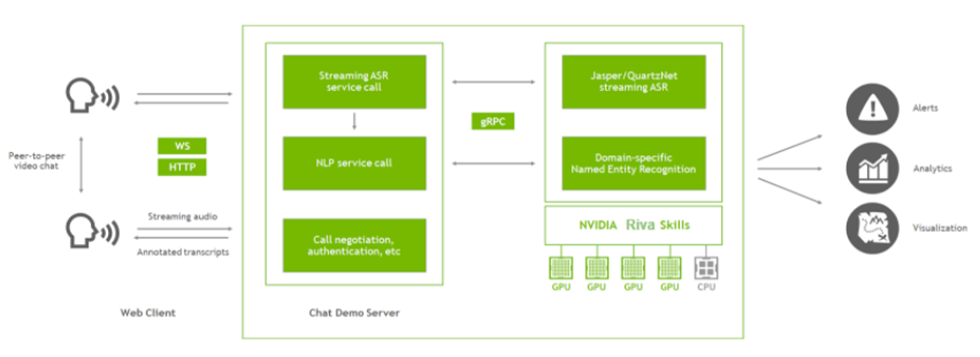
图 3 显示了应用程序的主要组件,现在您已经添加了 Riva 。聊天演示服务器( Node . js 应用程序)仍然设置视频通话,现在它还与 Riva 服务器通信。
在该应用程序中,您可以使用 Riva 实现两个功能:获取对话的流媒体记录,并在记录中标记关键短语(命名实体)。为此,从客户端提取音频流,并将该音频传递到 Node . js 服务器。服务器使用 gRPC 调用 Riva 来获取成绩单和命名实体,并将结果传递回客户端。然后,客户端可以在浏览器中呈现文本,并通过点对点连接传递文本,以便两个用户都可以看到整个对话。
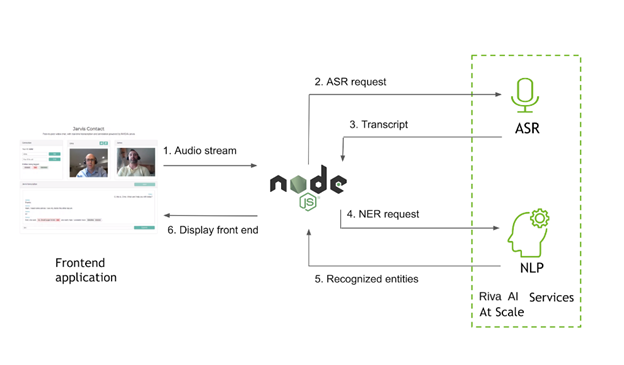
从 web 客户端获取音频
在客户端,您可以通过点击发送给对等方进行视频聊天的本地 WebRTC 流来访问音频流。在客户端 JavaScript 文件中,当用户选择时,初始化与服务器的 Riva 连接开始. 您正在通过套接字连接发送音频数据,因此首先确保套接字处于活动状态:
socket = socketio.on('connect', function() { console.log('Connected to speech server');
});
WebRTC audio 使用处理图的概念。要在浏览器中使用音频,请执行以下操作:
- 连接到音频源,在本例中是从本地视频聊天流。
- 创建一个处理节点来处理该音频。
- 在您参与之前,将新节点连接回原始目的地,即音频最初传输的地方。
每次您获得进入新处理节点的完整音频缓冲区时,请使用 web worker 重新采样,并通过套接字连接将重新采样的缓冲区发送到服务器。设置音频源连接并初始化重采样器:
audio_context = new AudioContext();
sampleRate = audio_context.sampleRate;
let audioInput = audio_context.createMediaStreamSource(localStream);
let bufferSize = 4096;
let recorder = audio_context.createScriptProcessor(bufferSize, 1, 1);
let worker = new Worker(resampleWorker);
worker.postMessage({ command: 'init', config: { sampleRate: sampleRate, outputSampleRate: 16000 }
});
每次缓冲区填满时,浏览器都会触发一个事件,因此告诉处理器节点如何处理它。使用辅助线程重新采样,然后使用套接字连接将其传递给服务器:
recorder.onaudioprocess = function(audioProcessingEvent) { let inputBuffer = audioProcessingEvent.inputBuffer; worker.postMessage({ command: 'convert', // You only need the first channel buffer: inputBuffer.getChannelData(0) }); worker.onmessage = function(msg) { if (msg.data.command == 'newBuffer') { socket.emit('audio_in', msg.data.resampled.buffer); } };
};
在将音频发送到 Riva 之前,不完全需要对其进行重新采样。 Riva 可以自行进行重新采样。但是,在浏览器中执行此操作既降低了带宽要求,又简化了从一个录制源到另一个录制源的一些差异。现在,您可以将新处理器节点连接到音频图中,包括源音频和目标音频:
audioInput.connect(recorder); recorder.connect(audio_context.destination);
此时,应用程序可以从用户的麦克风中提取音频,对流重新采样,并使用套接字将重新采样的音频发送到服务器。接下来,我们将向您展示如何在服务器上使用此音频。
将音频路由到 Riva
在 Node . js 中实现的主服务器脚本使用 Express server 和 Socket . IO 来处理传入的连接。当插座首次连接时,设置 Riva 连接。
io.on('connect', (socket) => { console.log('Client connected from %s', socket.handshake.address); // Initialize Riva socket.handshake.session.asr = new ASRPipe(); socket.handshake.session.asr.setupASR(); socket.handshake.session.asr.mainASR(function(result){ var nlpResult; if (result.transcript == undefined) { return; } // Final transcripts also get sent to NLP before returning if (result.is_final) { nlp.getRivaNer(result.transcript) .then(function(nerResult) { result.annotations = nerResult; socket.emit('transcript', result); }, function(error) { result.annotations = {err: error}; socket.emit('transcript', result); }); } else { socket.emit('transcript', result); } });
});
这里发生了一些事情。您可以创建一个新的 ASRPipe 并将其附加到套接字的 handshake.session 对象,这样您就有一个单独的 setupASR 流与每个客户端连接关联。使用 Riva 执行一些基本的 Riva 设置,然后启动 ASR 侦听循环。
ASR 侦听循环是异步的。您定期向它发送成批的音频数据,它通过回调函数定期发送结果。回调函数是传递给 mainASR 的函数。在流模式下, Riva 可以发回两种结果:一种是临时假设,随着更多音频的进入(提供更多的上下文),该假设会发生变化;另一种是最终的转录本。每当音频中有短暂的停顿时,例如当演讲者呼吸时,抄本往往会作为“最终”返回。您将这两种结果都发送回客户机,但当您获得最终结果时,您也会将这些成绩单发送到 NLP 服务以获得 NER 。无论哪种方式,都可以使用 transcript 事件通过相同的套接字连接将结果传递回客户端。
使用 Socket . IO ,可以为特定事件设置侦听器。前面提到过其中一个事件: audio_in 事件,该事件在客户端发送音频数据包时触发。在服务器端,将侦听器添加到用于初始化 Riva 的相同 io.on('connect') 作用域。
socket.on('audio_in', (data) => { socket.handshake.session.asr.recognizeStream.write({audio_content: data});
});
这一部分很简单,因为它不需要做很多事情。在连接套接字时设置了 Riva 流之后,您所要做的就是传递新的音频内容。
发送语音识别请求
现在看看 gRPC 接口本身,从 ASR 开始。连接到 gRPC service using Node.js 时,主要有三个步骤:
- 使用协议缓冲区导入 Riva API 。
- 围绕 API 编写方便的函数。
- 在客户端和 Riva 函数之间调解数据。
在 asr . js 模块中,定义前面调用的 ASRPipe 类,首先导入 Riva API :
const jAudio = require('./protos/src/riva_proto/audio_pb');
var asrProto = 'src/riva_proto/riva_asr.proto';
var protoOptions = { keepCase: true, longs: String, enums: String, defaults: true, oneofs: true, includeDirs: [protoRoot]
};
var asrPkgDef = protoLoader.loadSync(asrProto, protoOptions);
var jAsr = grpc.loadPackageDefinition(asrPkgDef).nvidia.riva.asr;
然后,定义 ASRPipe 类以及前面调用的设置函数:
class ASRPipe { setupASR() { // the Riva ASR client this.asrClient = new jAsr.RivaSpeechRecognition(process.env.RIVA_API_URL, grpc.credentials.createInsecure()); this.firstRequest = { streaming_config: { config: { encoding: jAudio.AudioEncoding.LINEAR_PCM, sample_rate_hertz: 16000, language_code: ‘en-US’, max_alternatives: 1, enable_automatic_punctuation: true }, interim_results: true } }; }
}
在这里,您创建一个 Riva ASR 客户机并定义一些配置参数,这些参数在流打开时作为第一个请求发送到流。在同一类定义中,指定 mainASR 函数以设置实际 ASR 流:
async mainASR(transcription_cb) { this.recognizeStream = this.asrClient.streamingRecognize() .on('data', function(data){ if (data.results == undefined || data.results[0] == undefined) { return; } // transcription_cb is the result-handling callback transcription_cb({ transcript: data.results[0].alternatives[0].transcript, is_final: data.results[0].is_final }); }) .on('error', (error) => { console.log('Error via streamingRecognize callback'); console.log(error); }) .on('end', () => { console.log('StreamingRecognize end'); }); // First request to the stream is the configuration this.recognizeStream.write(this.firstRequest);
}
streamingRecognize 函数是异步的。只要 Riva 有结果要发送,就会触发数据事件,因此请重新打包这些结果,并将它们从早期发送到回调函数。
发送 NER 请求
调用 Riva NER 服务更简单。像前面一样加载 NLP API ,然后使用要处理的每行文本调用 ClassifyTokens 函数。每个请求发送文本以及要使用的 Riva – 部署模型。如果需要,在名为 computeSpans 的函数中进行一些后处理,然后传递结果。
function getRivaNer(text) { var entities; req = { text: , model: {model_name: process.env.RIVA_NER_MODEL} }; return new Promise(function(resolve, reject) { nlpClient.ClassifyTokens(req, function(err, resp_ner) { if (err) { reject(err); } else { entities = computeSpans(text, resp_ner.results[0].results); resolve({ner: entities}); } }); });
};
至此,您已经完成了对 Riva 的 gRPC 调用。您可以在客户端捕获音频,通过流式连接将其发送到 Riva 以获取转录本,并在文本中标记命名实体。每次 Riva 发回结果时,通过带有 transcript 事件的套接字将结果传递给用户的 web 客户端。现在,通过在浏览器中处理这些结果来完成回路。
在浏览器中渲染结果
现在,您已经将带有注释的成绩单返回到 web 客户端,请在浏览器中显示它们。回想一下,所有的客户机 – 服务器通信都是通过 Socket . IO 连接进行的,因此请为带有结果的 transcript 事件设置一个侦听器。
socket.on('transcript', function(result) { document.getElementById('input_field').value = result.transcript; if (result.is_final) { // Erase input field $('#input_field').val(''); showAnnotatedTranscript(username, result.annotations, result.transcript); // Send the transcript to the peer to render if (peerConn != undefined && callActive) { peerConn.send({from: username, type: 'transcript', annotations: result.annotations, text: result.transcript}); } }
});
input_field 元素在 web UI 中是一个方便的地方,可以显示临时记录,在您讲话时可以实时更新。在完整应用程序中,您使用同一字段发送纯文本请求。当成绩单标记为最终成绩单时,将其显示在单独的框中,并将成绩单副本发送给通话中的另一人,以便您可以看到对话的双方。
呈现成绩单本身是标准的 HTML 和 CSS 。为了让您的生活更轻松,请使用优秀的 displaCy-ENT 将命名实体与文本对齐。
微调医疗设备的模型
默认情况下, Riva 提供了一个 NER 模型,该模型处理位置、人员、组织和时间等实体。这对于许多应用程序来说都很好,比如理解新闻文章和构建聊天机器人。早些时候,我们讨论了对话 AI MIG ht 如何帮助远程医疗应用程序。以下是 MIG ht 如何为 Riva 训练一个 NER 模型来标记医疗实体。
从头开始的培训模型通常是一个时间密集型过程。您可以使用现有的经过训练的模型并对自定义数据进行微调,而不是从新的模型开始。 NVIDIA TAO Toolkit 是一款基于 Python 的 AI 工具包,专门设计用于减少使用数据微调和定制预训练模型所需的时间。
因为医疗数据可能高度敏感,所以在线查找并不总是那么容易。一个优秀的 NER 数据集来自 2010 i2b2/VA challenge ,其中包含针对问题(如疾病或症状)、治疗(包括药物)和测试标记的未识别医生注释。您可以申请访问数据集,这是医学 NLP 社区中使用的标准竞争基准。
NER 数据通常以某种形式的 IOB 提供 标记,其中文本中的每个标记标记为实体开头、实体内部(不是第一个单词)或外部。对于医学文本,它通常如下所示:
正文:
DISCHARGE DIAGNOSES : Coronary artery disease , status post coronary artery bypass graft .
标签:
O O O B-problem I-problem I-problem O O O B-treatment I-treatment I-treatment I-treatment O
这是用作 TAO 工具包输入的数据。有关使用工具包培训 NER 模型的更多信息,请参阅 TAO- Riva NER 集合中的培训笔记本。在本例中,您从预训练的语言模型检查点 bert base uncased 开始,并使用预处理的 i2b2 数据为 NER 任务对其进行调优。
培训和部署自定义模型需要几个步骤。从预训练的检查点开始,您可以使用数据微调 TAO 工具箱中的模型。再次使用工具箱将模型导出为 Riva 的优化形式。为 Riva 提供一些基本部署设置,构建一个绑定配置的中间表单。然后,部署该包以创建一个正在运行的 Riva 服务器。有关更多信息,请参阅 NVIDIA Riva Speech Skills 。
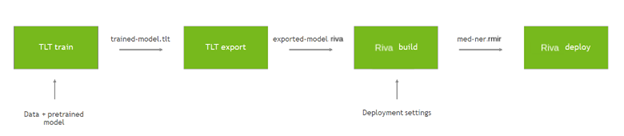
以下命令使用 TAO 工具包对自定义数据上的预训练模型进行微调:
!tlt token_classification train \ -e $SPECS_DIR/train.yaml \ # Specification file -g 1 \ -k $KEY \ -r $RESULTS_DIR/medical_ner \ data_dir={destination_mount}/data/i2b2 \ model.label_ids={destination_mount}/data/i2b2/label_ids.csv \ trainer.max_epochs=10
完成后, TAO 工具包将模型保存在名为 trained-model.tlt 的文件中。下一步是将此模型导出为 Riva 可用于部署的 riva 格式:
!tlt token_classification export \ -e $SPECS_DIR/export.yaml \ # Specification file -g 1 \ -m $RESULTS_DIR/medical_ner/checkpoints/trained-model.tlt \ -k $KEY \ -r $RESULTS_DIR/medical_ner \ export_format=RIVA
该模型现在导出为 exported-model.riva ,可在 Riva 中使用。
使用 Riva ServiceMaker Docker 映像,构建并部署新模型。
docker pull nvcr.io/riva/riva-speech:1.0.0b1-rc5-servicemaker docker run --gpus all -it --rm -v $RESULTS_DIR/medical_ner:/servicemaker-dev -v $RIVA_REPO_DIR:/data --entrypoint="/bin/bash" nvcr.io/ea-riva-stage/riva-service-maker:1.0.0b1-rc5 riva-build token_classification --IOB=true /data/med-ner.jmir /servicemaker-dev/exported-model.riva riva-deploy /data/med-ner.jmir /data/models -f
--IOB 标志告诉 Riva 将模型输出解释为 IOB 标记的 NER 模型,这简化了模型输出。 $RIVA_REPO_DIR 是 Riva 存储库的位置,该存储库是在从快速启动脚本运行 riva_init.sh 时创建的。该存储库包含一个 models 子目录,其中包含所有已部署的模型,包括默认的通用域。调用 riva-deploy 时, Riva 将新的 NER 模型插入该位置。
有了这个新的 NER 模型,你现在可以在应用程序中获得医学领域标签,通过对话实时显示。

部署到生产环境中
Riva 设计为高度可扩展,使用 Riva SDK 开发的应用程序可以部署在云端或本地 Kubernetes 集群中。 Riva 提供了一个示例头盔图,可用于入门:
在集群上安装 Kubernetes 、 Helm 3 . 0 和 Kubernetes 的 NVIDIA GPU Operator 。接下来,从 NGC 下载 Riva AI 服务掌舵图。
export NGC_API_KEY=<your_api_key> helm fetch https://helm.ngc.nvidia.com/ea-riva/charts/riva-api-0.1-ea.tgz --username='$oauthtoken' --password=<YOUR API KEY>
解开压缩文件夹后,在 /riva-api 下查找部署所需的文件。
riva-api ├── Chart.yaml ├── templates │ ├── deployment.yaml │ ├── _helpers.tpl │ └── service.yaml └── values.yaml
Chart . yaml 文件包含有关头盔部署的信息,如名称、版本等。要更改部署配置,请查看 values . yaml 文件,并根据需要更改配置:
replicaCount: Riva 服务副本的数量。speechServices [asr | nlp | tts]:启用语音服务的三个布尔参数。ngcModelConfigs:要从 NGC 下载的型号配置。service:要在生产中部署的负载平衡服务。
从 values . yaml 文件读取值的 Kubernetes 部署文件位于 templates 文件夹中。 Kubernetes 集群上的 Riva 示例部署执行以下操作:
- 找到 GPU 节点并使用预训练模型拉取 Riva 语音 Docker 容器。
- 装载包含模型目录的 Docker 卷。
- 拉动、设置和运行 Triton 推理服务器。
- 为入站推断请求和出站响应打开端口。
- 设置 Prometheus 服务以提取 GPU 和推断度量。
最后,要部署 Riva 服务器,请运行以下命令:
helm install riva_server riva-api
或者,使用 --set 选项安装,而不修改 values . yaml 文件。确保正确设置 NGC _ API _键 ngcCredentials.email 和 model_key_string 值。默认情况下, model_key_string 选项设置为 tlt_encode.
helm install riva-api --set ngcCredentials.password=`echo -n $NGC_API_KEY | base64 -w0` --set ngcCredentials.email=your_email@your_domain.com --set modelRepoGenerator.modelDeployKey=`echo -n model_key_string | base64 -w0` > NAME: riva-api LAST DEPLOYED: Thu Jan 28 12:05:36 2021 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None
检查日志,查看 Riva 服务器是否已部署且没有任何错误:
kubectl get pods kubectl logs <pod name>
要向 Riva 服务器发出推断请求,必须获取负载平衡器的 IP 地址:
kubectl get services > NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE riva-api LoadBalancer 10.100.194.170 ac51c23e62d094aa68ac2adb98edb7eb-798330929.us-east-2.elb.amazonaws.com 8000:30034/TCP,8001:31749/TCP,8002:30708/TCP,50051:30513/TCP,60051:31739/TCP 2m19s kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 123m
EXTERNAL-IP 值可以在 env.txt 中用作 external endpoint:
RIVA_API_URL= <external-IP>
在理想的微服务部署架构中,示例 web 应用程序也应包含在 Helm 部署中。但是,对于本文,请将 Node . js 应用程序排除在集群环境之外。使用示例应用程序中的上一个命令中的群集 IP 地址,并测试 Riva ASR 和 NLP 的规模能力。
结论
很难构建一个针对您的用例定制的高性能、可伸缩的对话 AI 应用程序。在本文中,我们讨论了如何使用 NVIDIA Riva 轻松地向现有应用程序添加音频转录和命名实体识别功能。我们还介绍了如何使用 TAO Toolkit 定制应用程序,以及如何使用 Helm 图表大规模部署应用程序。您可以从 下载 Riva 开始学习。